RDBMS
SQL(Structured Query Language)은 데이터베이스에서 사용하는 쿼리 언어다.
SQL을 사용하여 RDBMS에서 데이터를 검색, 저장, 수정, 삭제 등이 가능하다.
RDB(Relational Database)란 관계형 데이터 모델에 기초를 둔 데이터베이스다.
관계형 데이터 모델이란 데이터를 구성하는데 필요한 방법 중 하나로 모든 데이터를 2차원 테이블 형태로 표현해준다.
그럼 RDBMS(Relational Database Management System)란 관계형 데이터베이스를 생성하고 수정, 삭제 관리할 수 있는 소프트웨어라고 정의할 수 있다.
특징
데이터는 정해진(엄격한) 데이터 스키마를 따라 db 테이블에 저장된다
데이터는 관계를 통해서 연결된 여러개의 테이블에 분산된다.
장점
명확하게 정의된 스키마 : 데이터 무결성 보장
관계는 각 데이터를 중복없이 한번만 저장
단점
덜유연, 데이터 스키마는 사전에 계획되고 알려져야함 (수정하기 매우 힘들다)
관계를 맺기에 JOIN문이 많은 복잡한 쿼리 생성
수평적 확장 불가, 수직적 확장만 가능. 즉, 어느 시점에서 확장의 한계에 직면
사용하면 유리한 경우
관계를 맺고있는 데이터가(JOIN된) 자주 변경되는 앱일 경우
변경될 여지가 없고, 명확한 스키마가 사용자와 데이터에게 중요한 경우
NOSQL
not only sql
특징
nosql은 기본적으로 sql과 반대되는 접근 방식을 따른다
스키마 없음, 관계 없음
sql에서 데이터는 레코드라 칭하였지만, no-sql에서는 문서(documents)라고 부른다.
sql에서는 정해진 스키마를 따르지 않으면 데이터를 추가할 수 없지만, no-sql에서는 다른 구조의 데이터를 같은 컬렉션(sql의 테이블)에 추가 할 수 있다.
no-sql의 문서(documents)에는 json데이터와 비슷한 형태를 가지고 있다. 일반적으로 관련 데이터를 동일한 컬렉션에 넣는다. (sql처럼 여러 테이블에 나누어 담지 않는다.) 즉 관계형 db에서 사용한 user,products정보 또한 orders에 포함하여 한번에 저장한다.
이러한 방식은 데이터가 중복되기에 불안정한 측면이 있다. User, product에는 orders정보가 동시에 들어가는데 user만 order의 정보를 바꿀경우를 말합니다.
즉, 데이터를 같이 사용하는 컬렉션에서 똑같은 데이터 업데이트를 수행하도록 해야한다
그럼에도.이러한 방식의 커다란 장점은 복잡하고 조인(다른 테이블의 값을 합침)을 사용할 필요가 없다는 것이다.
특히 자주 변경되지 않는 데이터 일때 더 큰 장점이 있다.
기존의 RDBMS에서는 데이터와 트래픽이 증가함에 따라 기존의 장비로는 원활한 데이터의 처리가 어려워졌다. 이를 해결하기 위한 방법으로는 처리하는 장비의 성능을 키우는 수직적 확장(Scale-up)과 처리하는 장비의 수를 늘리는 수평적 확장(Scale-out)이 있다. 위에서 서술했듯이 수직적 확장은 비용적인 문제가 발생하므로 수평적 확장을 통해 성능을 올려야 한다. 하지만 문제는 관계형 데이터베이스가 클러스터 상에서 효율적으로 동작하도록 설계되지 않았다는 점이다.
장점
스키마 없기에 훨씬 유연, 언제든지 저장된 데이터를 조정하고, 새로운 필드 추가 가능
데이터의 저장은 앱이 필요한 부분에 유동적으로 저장 (낭비 없음) => 속도 빨라짐
수직, 수평 확장 가능함으로 db가 앱에서 발생하는 모든 읽기/쓰기 요청 처리 가능
단점
중복된 데이터가 변경된 경우 여러개의 콜렉션에서 데이터를 바꿔야한다.
사용하면 유리한 경우
정확한 데이터 구조를 알 수 없거나 변경 / 확장 될 수 있는 경우
읽기 처리를 자루하지만 데이터를 자주 변경하지 않는 경우 (즉, 한번의 변경으로 많은 문서를 업뎃할 필요가 없는 경우)
db를 수평적 확장 해야하는 경우(데이터의 양이 엄청나게 많은 경우)
종류
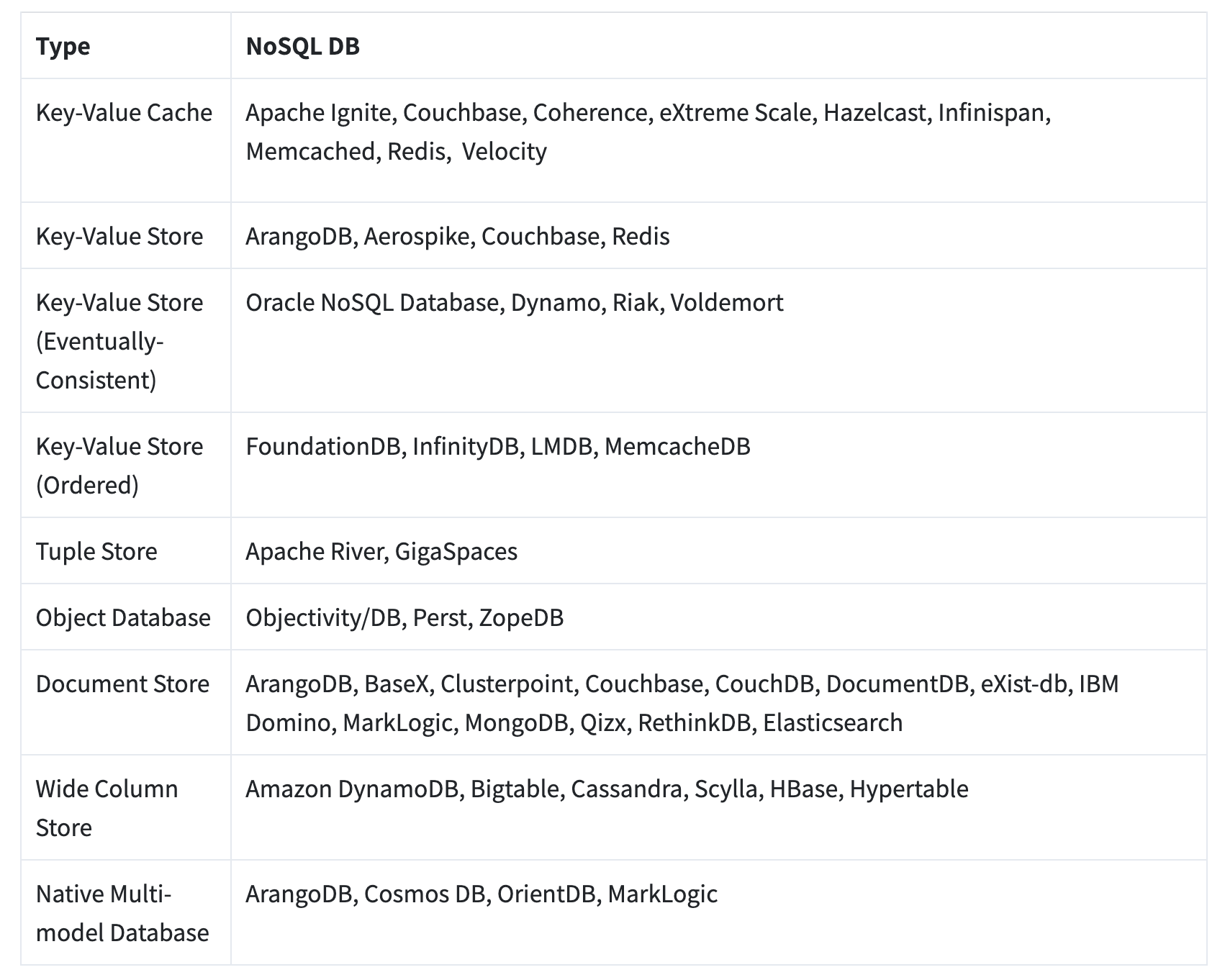
NoSQL 데이터베이스는 크게 네 가지 모델로 나눌 수 있다.
Key-value
Document
Column-family
Graph
이 중 그래프 모델을 제외한 나머지 세 모델은 집합-지향(Aggregate-oriented) 모델이다.
key - value
키 값(Key-value) 저장소는 가장 단순한 형태의 NoSQL으로, 수평적 확장이 용이하다. 또한 아주 간단한 API만을 제공하기 때문에 배우는 것이 어렵지 않다. 하지만 값의 내용을 사용한 쿼리가 불가능하다는 단점이 있다. 사용자는 키를 사용해 값을 읽어들인 뒤, 어플리케이션 레벨에서 적절히 처리해야 한다.
키-값 저장소는 데이터가 키와 값의 쌍으로 저장된다. 키는 값에 접근하기 위한 용도로 사용되며, 값은 어떠한 형태의 데이터라도 담을 수 있다. 심지어는 이미지나 비디오도 가능하다. 또한 간단한 API를 제공하는 만큼 질의의 속도가 굉장히 빠른 편이다.
Key-value 모델을 사용하는 NoSQL 데이터베이스로는 Memcached, Riak, Redis, Amazon Dynamo DB, LevelDB 등이 있다.
document
키-값 모델에서 한층 진화한 모델로 생각할 수 있다. 데이터는 키와 도큐먼트(Document)의 형태로 저장된다. 키-값 모델과 다른 점이라면 Value가 계층적인 형태인 도큐먼트로 저장된다는 것이다. 객체지향에서의 객체와 유사하며, 이들은 하나의 단위로 취급되어 저장된다. 다시 말해 하나의 객체를 여러 개의 테이블에 나눠 저장할 필요가 없어진다는 뜻이다. 또한 Document 모델에서는 도큐먼트 내의 item을 이용한 쿼리가 가능하다. 다만 이를 위해서는 Xquery나 다른 도큐먼트 질의 언어가 필요하다.
주요한 특징으로는 객체-관계 매핑이 필요하지 않다. 객체를 도큐먼트의 형태로 바로 저장 가능하기 때문이다. 또한 검색에 최적화되어 있는데, 이는 키-값 모델의 특징과 동일하다. 단점이라면 사용이 번거롭고 쿼리가 SQL과는 다르다는 점이다. 도큐먼트 모델에서는 질의의 결과가 JSON이나 xml 형태로 출력되기 때문에 그 사용 방법이 RDBMS에서의 질의 결과를 사용하는 방법과 다르다. 또한 질의 언어가 SQL과 다르기 때문에 사용에 익숙해지기까지 다소 어려움이 있을 수 있다.
Document 모델을 사용하는 NoSQL 데이터베이스로는 MongoDB, CouchDB, MarkLogic 등이 있다.
column-family
컬럼-패밀리(Column-family) 모델은 위의 두 모델과는 다소 차이가 있지만 집합-지향 모델로 간주된다. 이전의 모델들이 키-값 쌍 중 값을 이용해 필드를 결정했다면, 특이하게도 이 모델은 키에서 필드를 결정한다. 키는 Row(키 값)와 Column-family, Column-name을 가진다. 연관된 데이터들은 같은 Column-family 안에 속해 있으며, 각자의 Column-name을 가진다. 관계형 모델로 설명하자면 어트리뷰트가 계층적인 구조를 가지고 있는 셈이다. 이렇게 저장된 데이터는 하나의 커다란 테이블로 표현이 가능하며, 질의는 Row, Column-family, Column-name을 통해 수행된다.
이러한 특징 덕에 컬럼-패밀리 모델은 클러스터링이 쉽게 이뤄지며, Time stamp가 존재해 값이 수정된 히스토리를 알 수 있다. 또한 값들은 일련의 바이너리 데이터로 존재하기 때문에 어떤 형태의 데이터라도 저장될 수 있다.
다만 위의 두 모델들과는 다르게 Blob 단위의 쿼리가 불가능하며, Row와 Column의 초기 디자인이 중요하다. Schema-less이긴 하지만 새로운 필드를 만드는 데 드는 비용이 크기 때문에 사실상 결정된 스키마를 변경하는 것이 어렵다.
Column-family 모델을 사용하는 NoSQL 데이터베이스로는 HBase, Cassandra, Hypertable 등이 있다.