NoSQL
RDBMS는 보통 “관계형 데이터베이스”라고 하며 반면 NOSQL은 “비관계형 데이터베이스”이다. 보통 NOSQL은 키-밸류나 컬럼, 문서 형식의 데이터 모델을 이용한다.
(RDBMS가 아닌 다른 형태로 데이터를 저장하는 기술이라고 생각하면 된다.)
NOSQL: Not Only SQL, 비관계형 데이터베이스
NOSQL을 쓰는 목적 : 아주 많은 양의 데이터를 효율적으로 처리가 필요할 때, 데이터의 분산처리, 빠른 쓰기 및 데이터의 안정성이 필요할 때 사용한다. 특정 서버에 장애가 발생했을 때에도 데이터 유실이나 서비스 중지가 없는 형태의 구조이기 때문에, NOSQL을 사용한다.
데이터 영속성
논리적인 데이터를 대표하는 객체는 물리적인 메모리 공간에 생성되어져서 다루어 집니다. 이런 데이터는 언젠가는 메모리에서 내려오게 되지요. 영원할 수 없다는 것이지요. 객체가 파괴되면 객체의 속성들은 모두 사라집니다. 그러나 객체의 속성을 어딘가에 저장해 놓으면 나중에 객체를 다시 생성했을 때 객체가 파괴되기 전의 상태로 되돌아 갈 수 있는데 이러한 속성을 영속성(persistence)이라고 합니다.
Nginx
Nginx는 웹서버 입니다. 간단하게 웹서버는 클라이언트로 부터 요청이 발생했을 때 요청에 맞는 정적파일을 보내 주는 역할을 합니다. Nginx는 규모가 작은 서비스이면서 정적 데이터 처리가 많은 서비스에 적합합니다.
Nginx는 일반적인 HTTP의 웹서버의 역할 외에도 proxy, reverse proxy 서버의 역할 또한 가능합니다. 양대산맥인 Apache와 두드러지게 다른 특징을 가지고 있는데요. Apache는 MPM(multi Processing Module: 다중 처리 모듈) 방식을 사용하는 반면, Nginx는 Event driven 방식을 통해 구동 됩니다. Event driven은 Node.js에서도 사용하는 방식이다. 이러한 장점은 메모리를 좀 더 효율적으로 운용할 수 있는 결과를 가져옵니다
Look Aside(=Lazy Loading)
Look Aside 방식은 캐시서버를 옆에 두고 필요할 때만 데이터를 캐시에서 로드하는 캐싱 전략입니다.
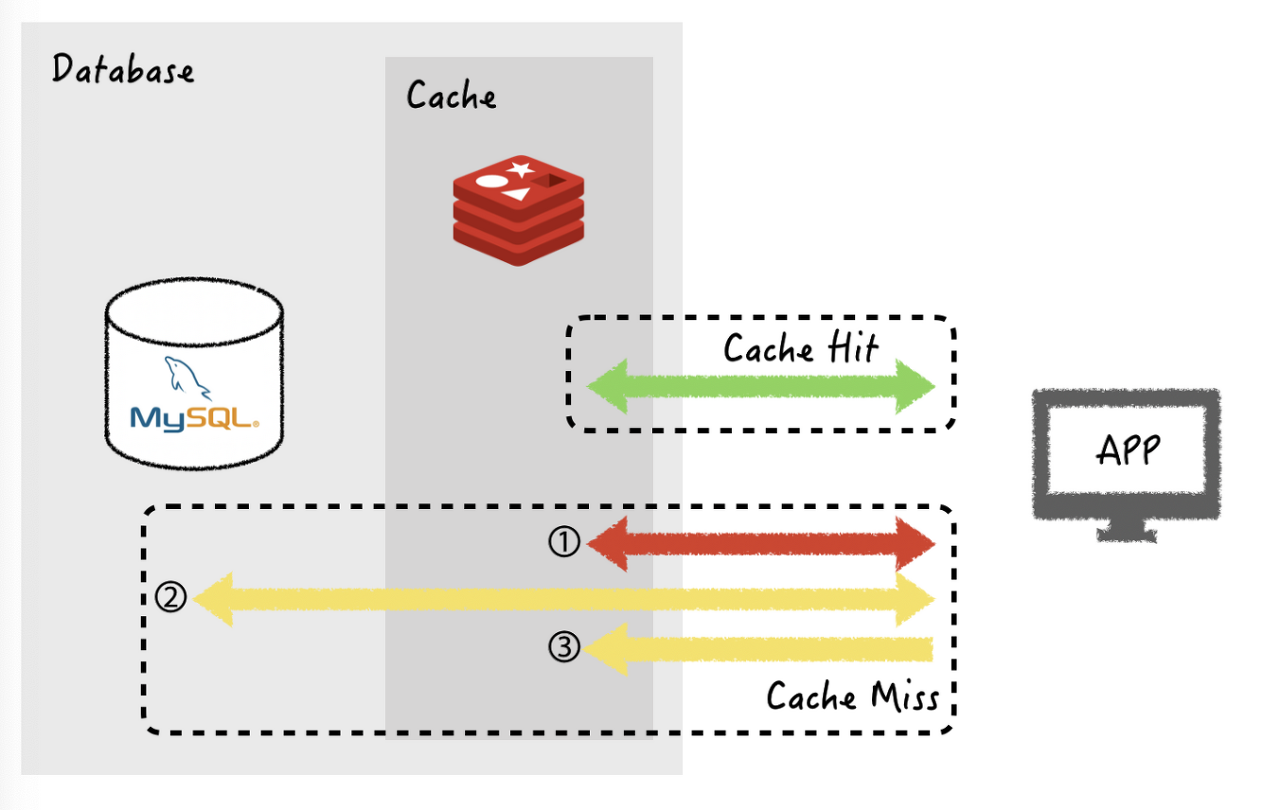
2-1. 캐시에 데이터가 있는 경우(cache hit) 해당 데이터를 사용합니다.
2-(2). 캐시에 데이터가 없는 경우(cache miss) 데이터베이스에서 데이터를 가져옵니다.
- 2-(2)에서 가져온 데이터를 캐시에 저장합니다.
Lazy Aside의 특징은 "실제로 사용되는 데이터만 캐시한다", "레디스의 장애가 어플리케이셔에 치명적인 영향을 주지 않는다" 입니다.
하지만 캐시 미스가 발생한 경우 데이터 쿼리에 대한 시간이 오래 걸리거나, 최신 데이터로의 동기화 문제가 생길 수 있습니다.
액터 모델(Actor Model)
액터 모델은 “모든 것은 액터다(Everything is an actor)”라는 기본 철학을 가지고 갑니다. OOP에서의 “모든 것은 객체다(Everything is an object)”라는 철학과 비슷하지만, 객체 지향 소프트웨어는 기본적으로 순차적 실행을 하지만 액터 모델은 본질적으로 동시성을 제공하는 점이 다릅니다.
그러면 액터(Actor)란 무엇이냐 라는 질문이 나올 수 있습니다. 액터는 비동기적으로 메세지를 처리할 수 있는 computational entity로 다음과 같은 특징이 있습니다:
다른 액터에게 유한한 개수의 메세지를 보낼 수 있습니다.
유한한 개수의 새로운 액터를 만들 수 있습니다.
다른 액터가 받을 메세지에 수반될 행동(behavior)을 지정할 수 있습니다.
실제 사람과의 커뮤니케이션을 상상하면 좀 더 이해하기 편합니다. 사람들은 초능력이 존재하지 않기에 타인과 머릿속 생각을 직접 공유하지 못하고, 대화(message)를 통해 대화를 주고받습니다.
액터 또한 똑같습니다. 메세지를 주고받아 다른 액터와 상호작용을 합니다. 액터가 차지하는 메모리 공간은 독립적이며, 다른 스레드나 액터가 접근할 수 없습니다. 다시 말하면, 메모리 공유 없이 메세지 전달만을 사용하기에 공유 메모리로 인한 교착 상태 등의 골치 아픈 상황들을 피할 수 있습니다.
이러한 액터 모델을 구현한 라이브러리 중에서 대표적으로 Akka가 있습니다. Akka는 JVM 상에서 동작하며 JAVA와 Scala 언어를 사용하는 고도의 동시(concurrent) 및 분산(distributed) 응용 프로그램을 빌드하기 위한 툴킷 및 런타임입니다
CSR, SSR
(렌더링을 어디서 하냐의 차이이다)
ssr : 서버 사이드 렌더링
블로그 페이지 같은것들, 해당 페이지를 구글이나 외부 크롤링에서 검색되게 하기 위해서이다.
완전하게 만들어진 html 파일을 받아오고 rendering하게 된다.
웹 서버에 요청할 때마다 browser 새로고침이 일어나고 서버에 새로운 페이지에 대한 요청을 하는 방식
장점 : 초기 로딩 속도가 빠르기 때문에 사용자가 컨텐츠를 빨리 볼 수 있다.
모든 검색엔진에 대한 seo(검색 엔지 최적화)가 가능하다.
단점 : 매번 페이지를 요청할때마다 새로고침 되기 때문에 사용자 ux가 다소 떨어진다.
서버에 매번 요청을 하기 때문에 트래픽, 서버 부하가 커진다.
seo에 대한 이슈는 구글은 크롤러안에 자바스크립트 엔진이 있어서 상관없지만, 네이버나 다음은
자바스크립트를 해석할 수 있는 엔진이 없어서 빈페이지로 인식할 수 도 있다.
이점에서 사람들에게 검색되는 페이지는 ssr을 많이 고려한다
—— —— —— —— —— —— —— —— —— —— — —— —— —— —— — —— — —— — —— —
csr : 클라이언트 사이드 렌더링
처음에 웹서버에 요청할때 데이터가 없는 문서를 반환한다.
첫로딩에 html과 static 파일들을 요청하고 전부 로드되면 javascript를 통해 동적으로 렌더링을 한다.
모바일앱 - 매번 모바일 쇼핑몰 html 전문을 받아오기엔 시간이 오래걸리기 때문이다.
도메인에 해당하는 ip에서 html 문서 및 기타 문서를 가져올것이다.
장점 : 첫 로딩에 html과 static 파일들만 다 받으면 동적으로 빠르게 rendering 하기 때문에 사용자 ux가 뛰어나다.
서버에 요청하는 횟수가 훨씬 적기 때문에 서버 부다이 덜하다
단점 : 모든 html과 static 파일이 로드될떄까지 기다려야 한다.
—— —— —— — — — — — — — —— ——— ——— ——— ——— ———
SPA vs MPA (페이지를 하나쓰냐 여러개쓰냐의 차이)
SPA(single page application)
단 하나의 페이지로 이루어진 어플리케이션
단 하나의 html 파일을 기반으로 javascript를 이용해 동적으로 화면을 이리저리 컨텐츠를 바꾸는 방식의 웹 어플리케이션이다.
MPA(multiple page application)
화면마다 html파일이 존재하고, 사용자가 그 화면을 요청할떄마다 웹서버가 필요한 데이터와 html로 파싱해서 보여주는 방식의
웹 어플리케이션이다.
spa는 csr방식이고 mpa는 ssr방식인것은 아니다.
spa는 서버로부터 처음에만 페이지를 받아오고 이후에는 동적으로 dom을 구성하여 rendering 되는 화면이 바뀌게한다.
여기서 동적으로 dom을 구성하여 rendering 되는 화면이 바뀌게 하는 부분이 csr이다,.
spa는 처음에만 페이지를 받아아고 이후에는 받아오지 않는데, 이럼에도 데이터가 수정되고 조회되게 하고 싶어서
csr이라는 방식을 채택한것이다.
같은 맥락으로 mpa는 동적이지 않은 페이지를 상황에 맞게 클라이언트에 뿌려주기 떄문에 ssr방식을 채택한것이다.
JPA, Hibernate, Spring Data JPA
https://suhwan.dev/2019/02/24/jpa-vs-hibernate-vs-spring-data-jpa/
Redis
