지난 시간 복습
관계설정을 하는 이유는 정규화와 관련이 있다.
정규화, 무결성
join 처리를 하려면 table 과 table 의 연관관계가 주어져야 원하는 data를 잘 뽑을 수 있다.
참조하려면 참조해주는 쪽이 유일한 값이어야 가능
삭제할 때에도 참조해주는 제약조건을 먼저 삭제해줘야 함.
Data Modeler 브라우저 확인
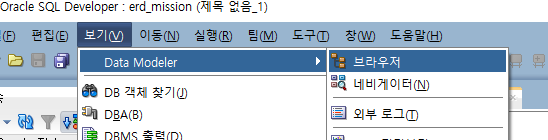
보기 - data modeler - 브라우저
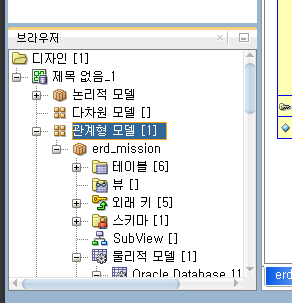
좌측 하단 브라우저 - 관계형 모델 - 새로만들어서 우클릭 - 표시
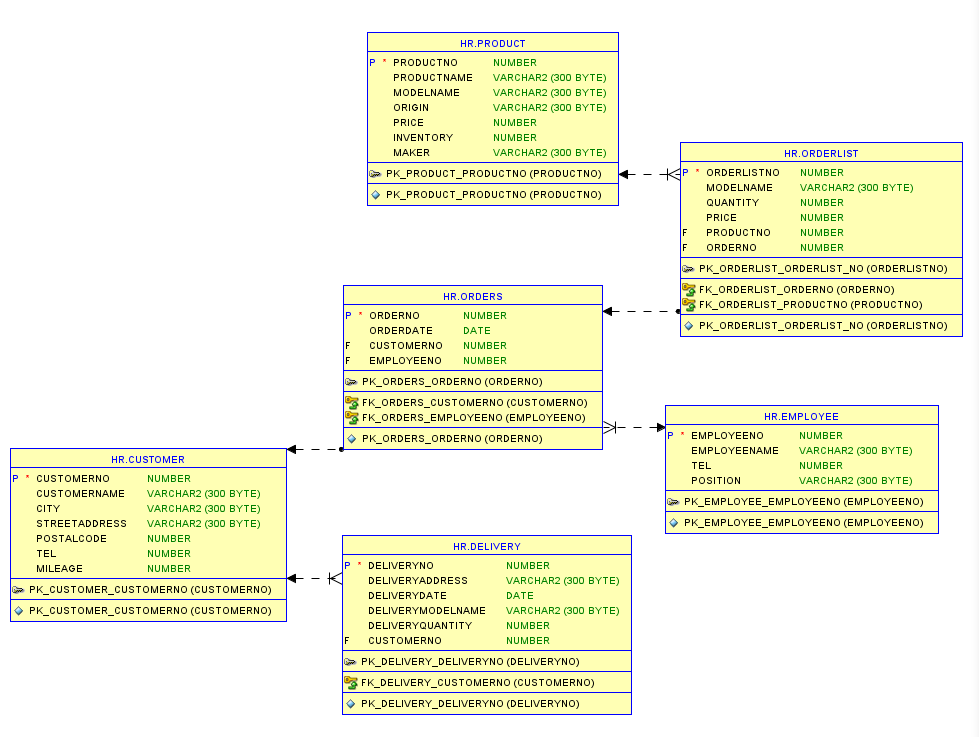
그 후 각 테이블을 드래그 앤 드롭으로 끌어다 두면 이렇게 관계형 모델을 볼 수 있다.
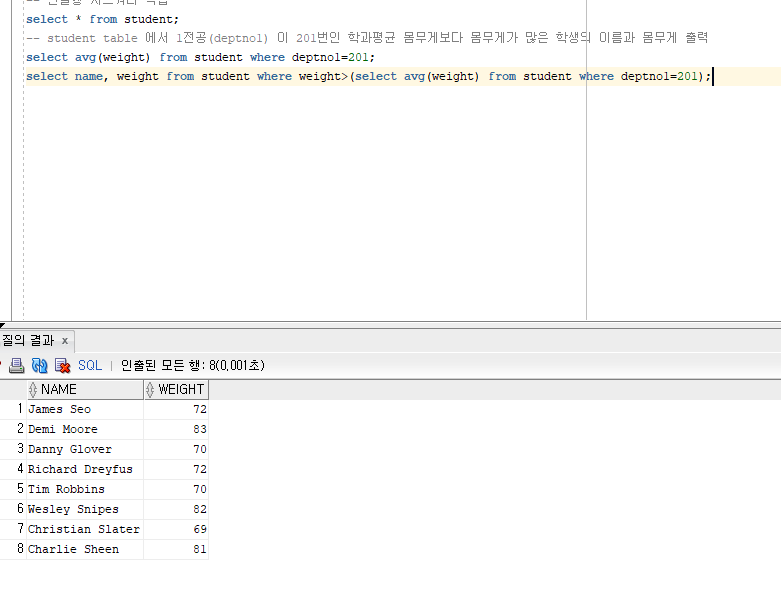
student table 에서 1전공(deptno1) 이 201번인 학과평균 몸무게보다 몸무게가 많은 학생의 이름과 몸무게 출력
다중행 Subquery
결과가 2행 이상
in : 결과를 메인에서 모두 검색
exists : 값이 있으면 다음 동작, 없으면 x
>any : 최소값보다 큰
<any : 최대값보다 작은
>all : 최대값보다 큰
<all : 최소값보다 작은
emp2 table과 dept2 table 을 참조하여 근무지역이 (dept2 table의 area column) 이 'Pohang Main Office' 인 모든 사원들의 사번과 이름, 부서번호를 출력하세요.
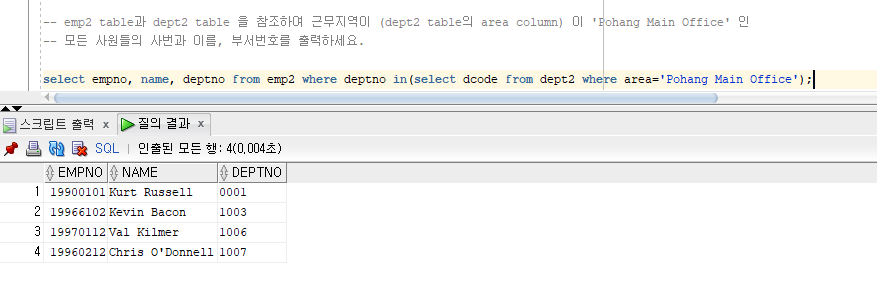
in 연산자 사용
emp2 table 에서 전체 직원 중 "Section head" 직급의 최소 연봉자보다 연봉이 높은 사람의 이름과 직급, 연봉을 출력
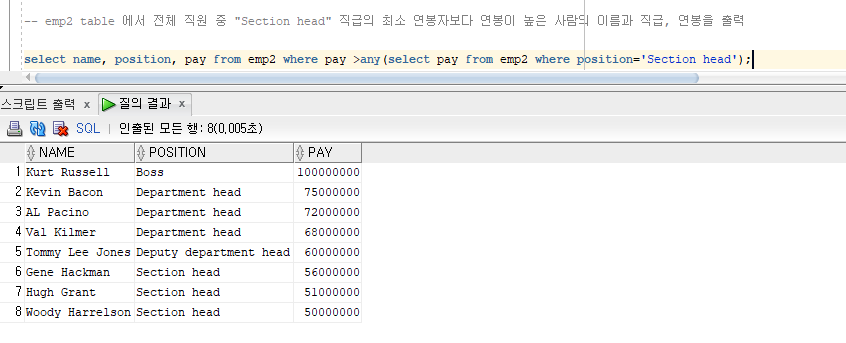
>any 연산자 사용
반대 개념 (최대값보다 작은)
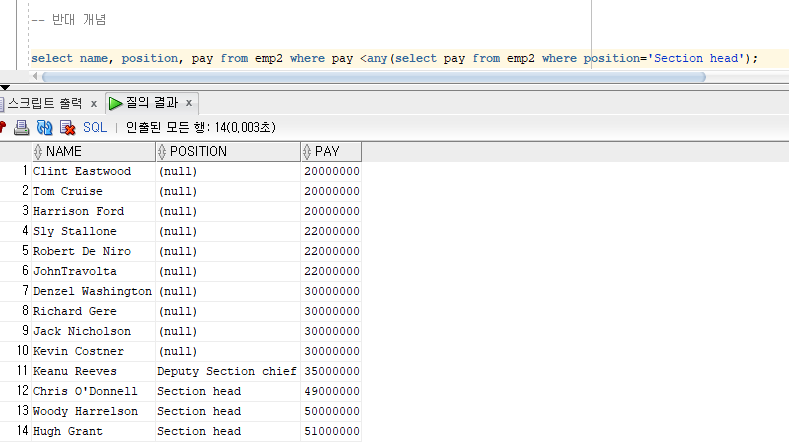
<any 연산자 사용
또 다른 개념 (최소값보다 작은)
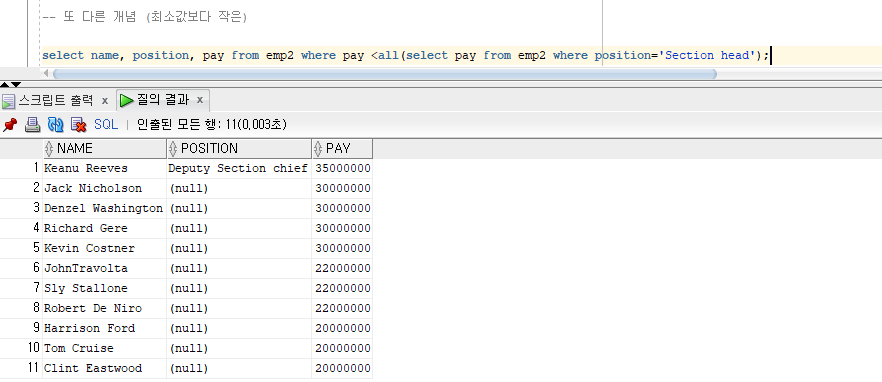
<all 연산자 사용
또 다른 개념 (최대값보다 큰)
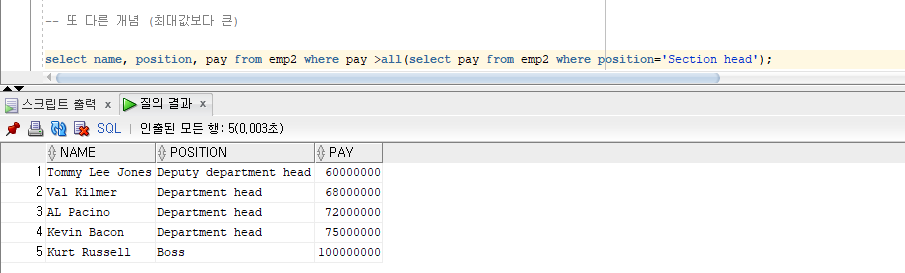
>all 연산자 사용
exists 활용
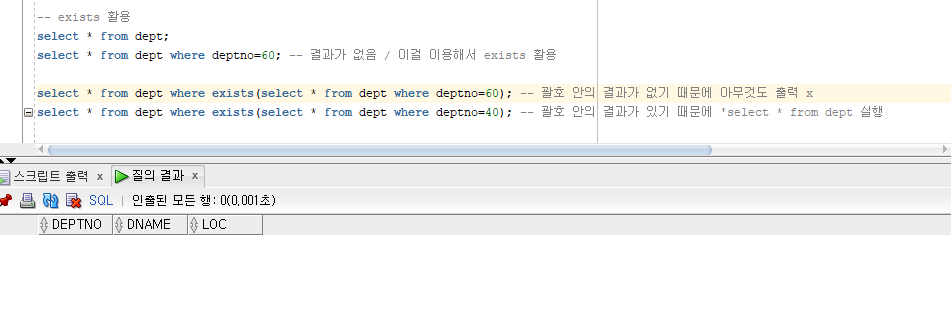
괄호 안의 결과가 없기 때문에 아무것도 출력 x
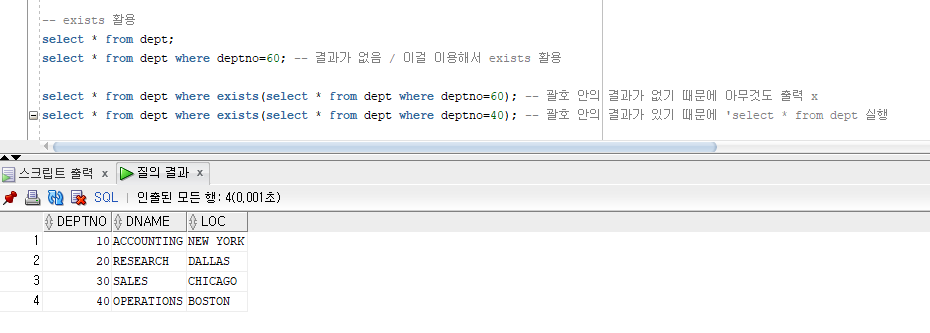
괄호 안의 결과가 있기 때문에 'select * from dept' 실행
다중 Column Query
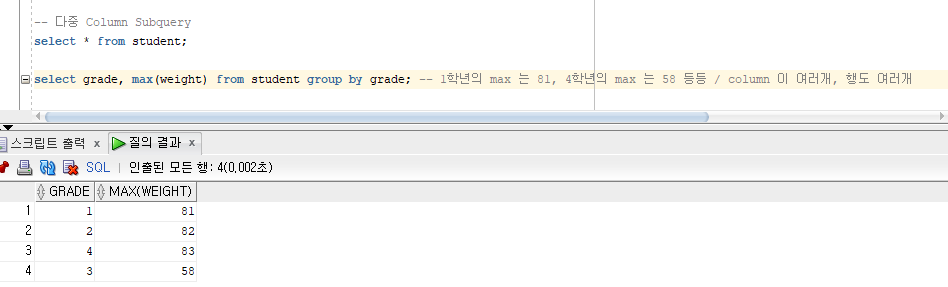
1학년의 max 는 81, 4학년의 max 는 58 등등 / column 이 여러개, 행도 여러개
학년별로 몸무게가 제일 많이 나가는 학생의 학년, 이름, 몸무게 출력
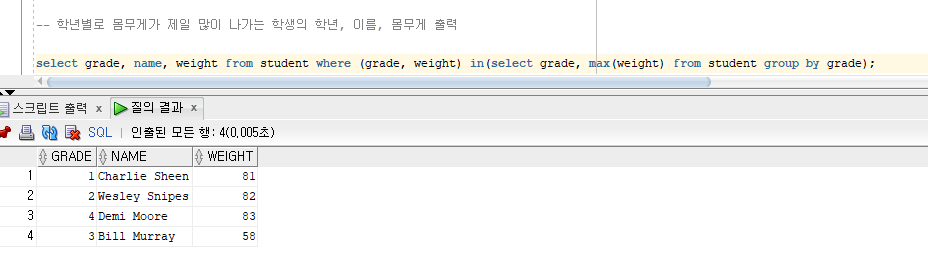
'in(select grade, max(weight) from student group by grade)' 의 Column이 2개이기 때문에 where 에서 비교하는 값도 2개를 비교 해야 함
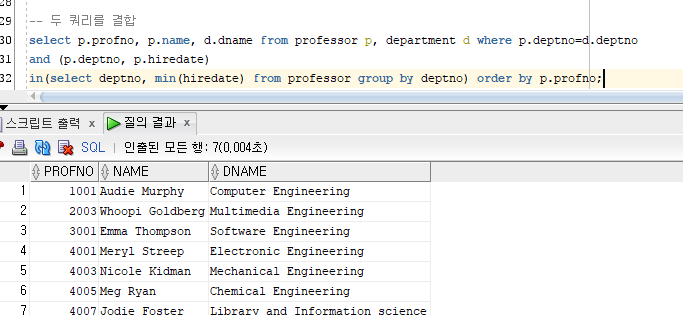
professor, department table에서 학과별로 입사일이 가장 오래된 교수의 교수번호와 이름, 학과명 출력
정규화
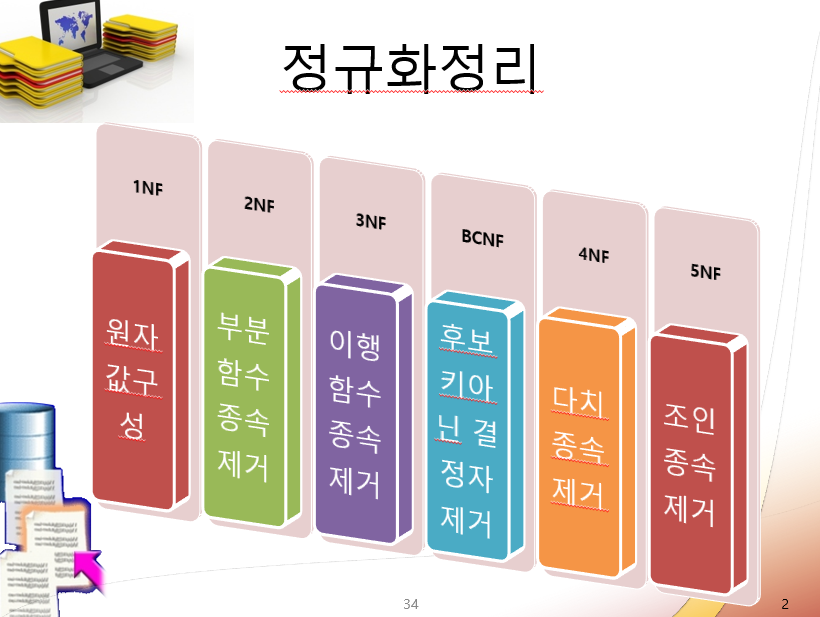
NF : Normalization Form
1차 : 원자값 구성
2차 : 부분함수 종속 제거
3차 : 이행함수 종속 제거
BC (Boyce-Codd) : 보이스 코드 정규형, 후보 키아닌 결정자 제거
4차 : 다치종속 제거
5차 : 조인종속 제거
일반적으로 3차, 조금 더 나아가 BCNF 까지 함.


Sql 사용자 생성, 권한 설정, 사용자 삭제
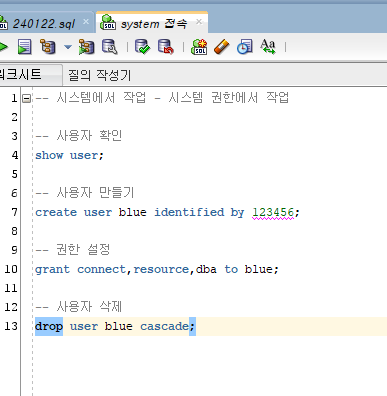
삭제할 때 관계설정해두면 제약이 있을 수 있어서 cascade 옵션 사용
View
view : 가상 table 을 의미, 원래 table 은 data 가 들어있지만 view 는 data 가 없음. 원본 table 에서 data 를 불러오는 query 만 존재함. 일반적으로 data 를 조회할 목적으로 사용
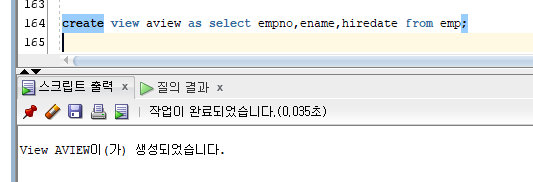
AVIEW 생성
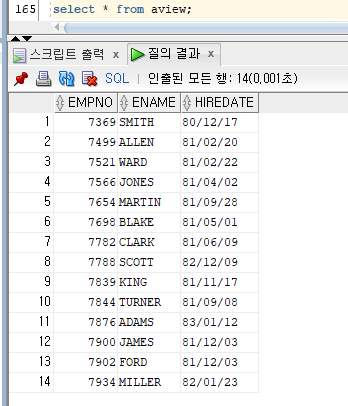
AVIEW 출력

View table 이 생성됨
view 삭제
View Detail
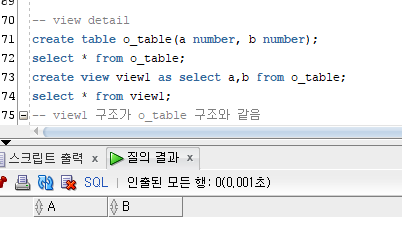
view1 구조와 o_table 구조가 같음.
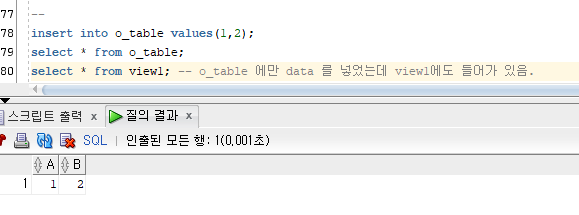
o_table 에만 data 를 넣었는데 view1에도 들어가 있음.
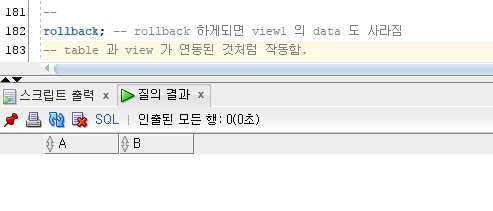
rollback 하게되면 view1 의 data 도 사라짐
table 과 view 가 연동된 것처럼 작동함.
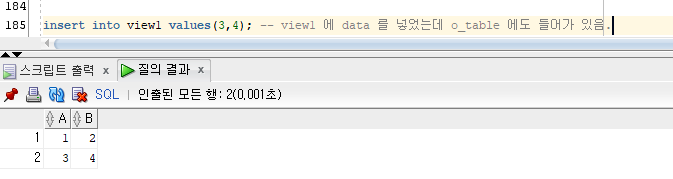
view 에 data 를 넣었는데, o_table 에도 들어가 있음.
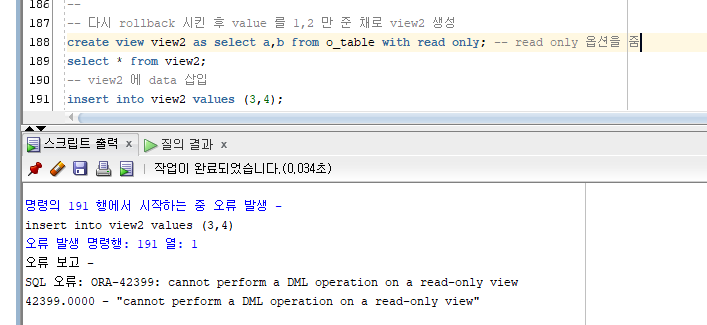
view2 는 read only 옵션을 가지고 있기 때문에 data 삽입 불가
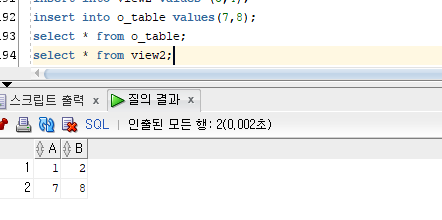
o_table 에 data 를 삽입하면 view2 에서 '읽기'만 가능함.
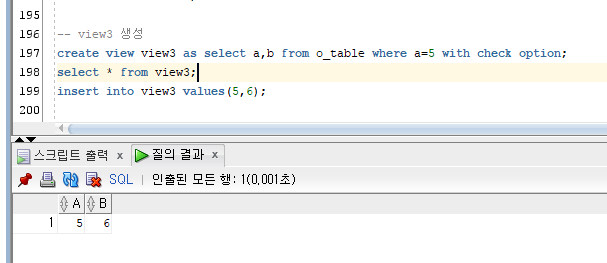
a=5 만 보이게 하는 옵션을 줬기 때문에 view3 에는 (5,6) 만 보인다.
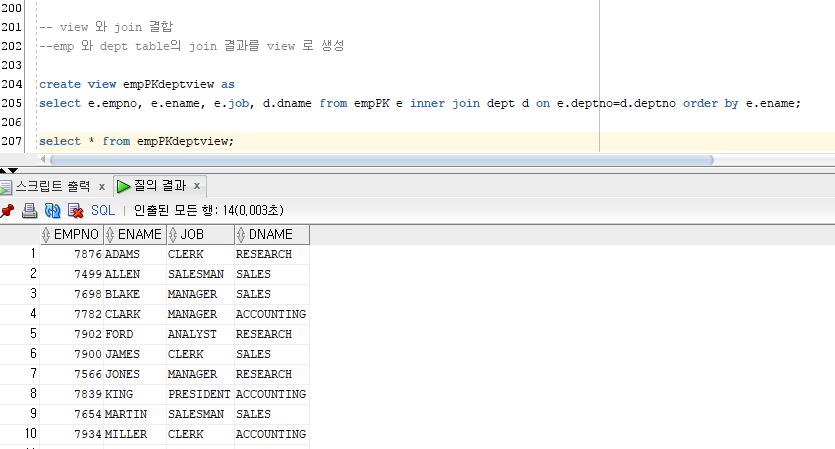
View 와 Join 결합
emp 와 dept table의 join 결과를 view 로 생성
Sequence
sequence : 자동 증가
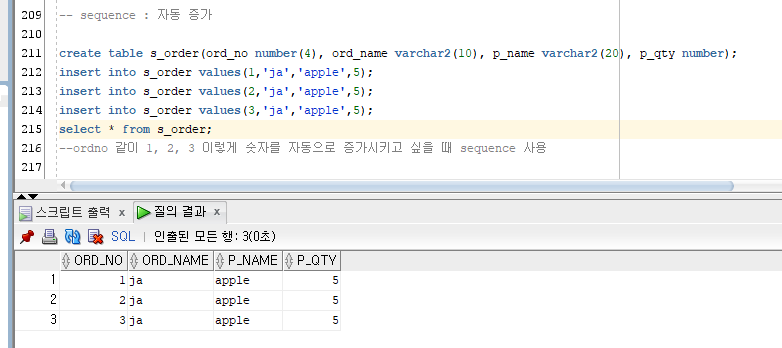
ordno 같이 1, 2, 3 이렇게 숫자를 자동으로 증가시키고 싶을 때 sequence 사용
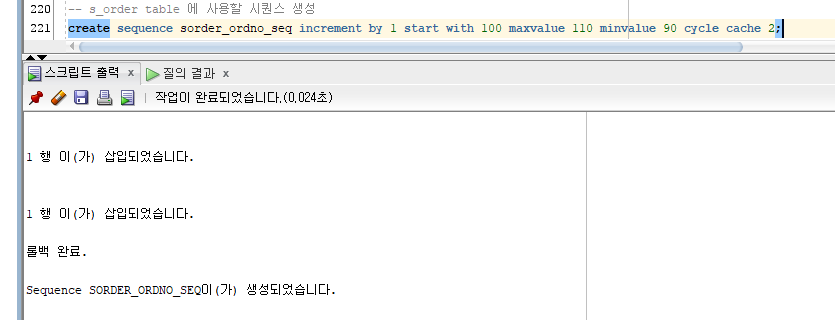
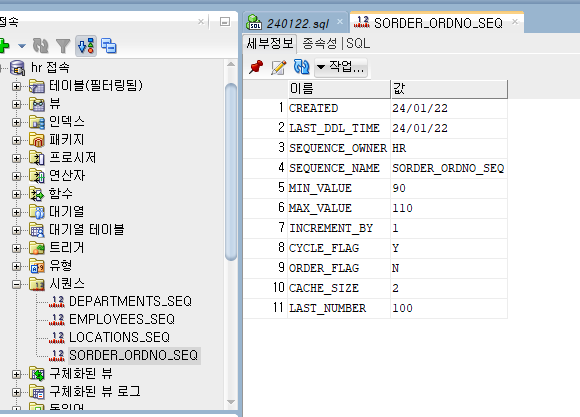
sequence 생성됨.
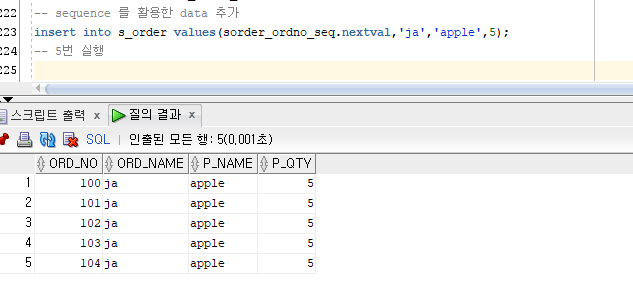
sequence 를 활용한 data 추가
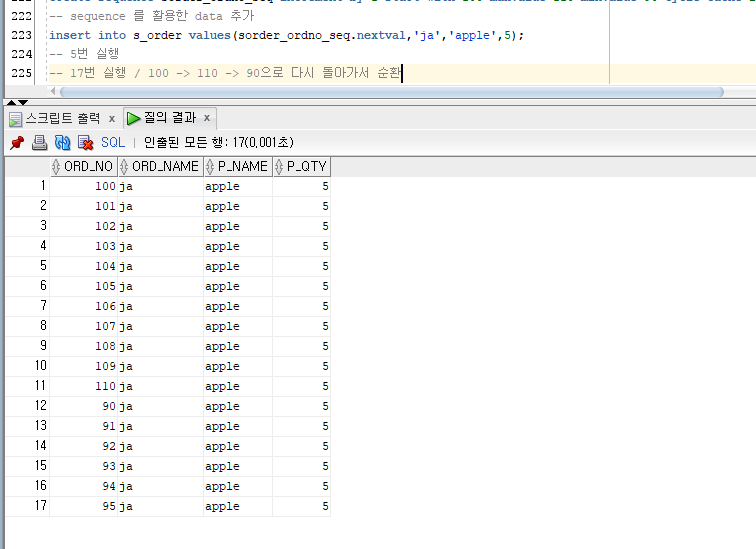
설정해둔 범위 내에서 순환
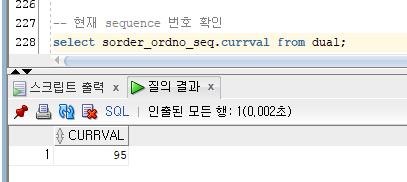
현재 sequence 번호 확인
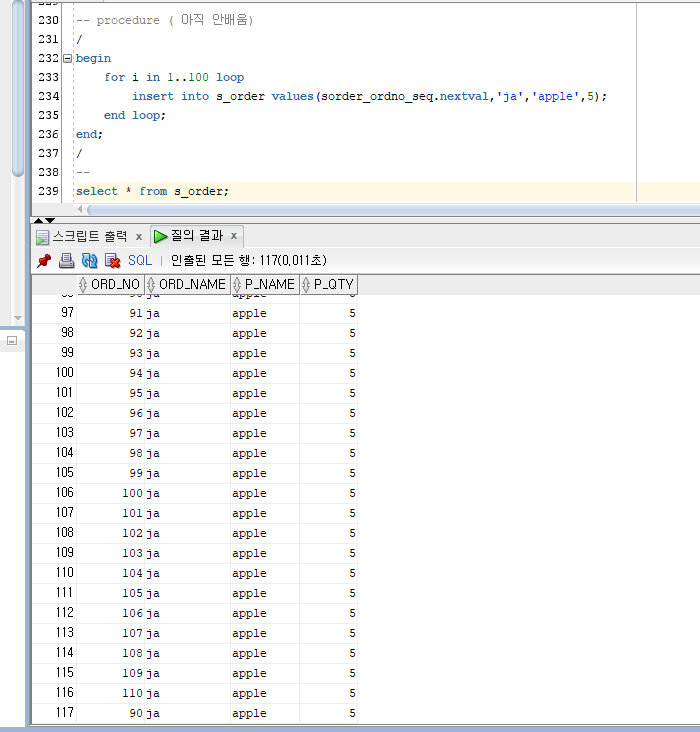
Procedure 이용
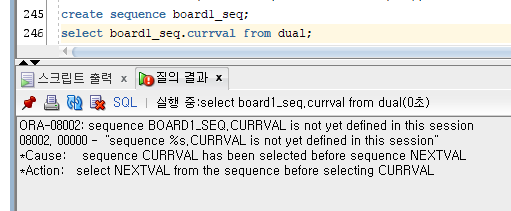
sequence 를 한번 이상 돌려야 현재값을 알 수 있다.
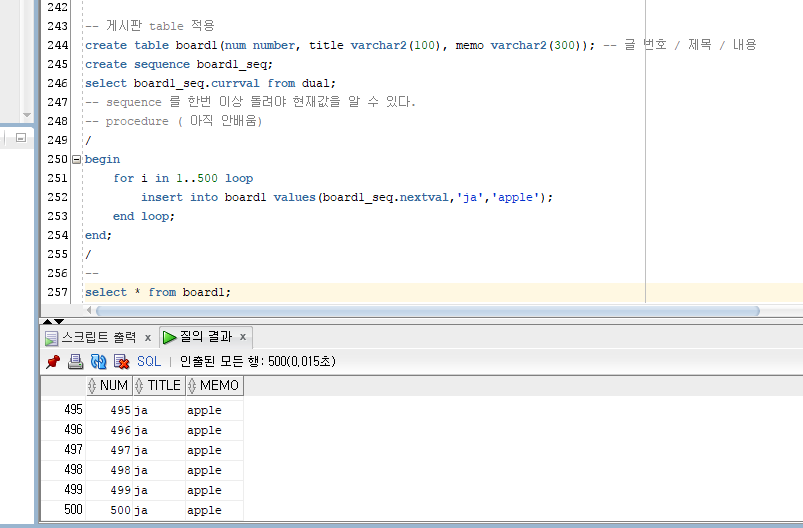
오전 수업 끝
