std::thread가 값을 반환하지 못하는 이유
std::thread는 하위 레벨의 운영체제 스레드를 직접 다루는 객체입니다. 스레드가 생성되어 함수를 실행하고 나면, 그 결과값을 어디에 저장해야 할지 std::thread 자체는 알 방법이 없습니다.
비동기성: 스레드는 자기가 할 일을 다 하고 언제 끝날지 모릅니다. 호출한 쪽(Main)에서 결과값을 받으려 할 때, 스레드가 이미 종료되어 메모리가 사라졌을 수도 있죠.
인터페이스: std::thread 객체의 생성자는 어떤 인자든 받을 수 있게 가변 인자 템플릿으로 되어 있지만, 결과적으로 실행하는 내부 구조는 void를 지향합니다.
-> 그래서 우리가 promise, future, packaged_task를 쓴 것이다.
스레드가 직접 값을 못 돌려주기 때문에, 우리는 "우회로"를 만든 것입니다.
std::promise: "스레드야, 너 함수 끝나면 여기에 결과값 좀 써줘." (입구)
std::future: "난 여기서 기다렸다가 그 결과값이 들어오면 가져갈게." (출구)
std::packaged_task: (오늘의 핵심) 이 녀석이 바로 "반환값이 있는 함수를 받아서, 내부적으로 void형 함수로 변신시킨 뒤, 결과를 future에 채워주는" 마법의 상자입니다.
Vector/ push_back , emplace_back 차이
push_back (복사 또는 이동)
방식: 함수 외부에서 이미 생성된 객체를 인자로 받습니다.
과정: 1. 임시 객체가 생성됨.
2. push_back이 호출되면서 벡터 내부 공간으로 객체를 복사(Copy)하거나 이동(Move)함.
3. 외부의 임시 객체는 소멸됨
emplace_back (직접 생성)
방식: 객체 자체가 아니라, 객체를 생성하는 데 필요한 인자들만 받습니다.
과정:
벡터가 내부적으로 관리하는 메모리 공간에서 직접 생성자를 호출함.
복사나 이동 과정이 아예 발생하지 않음 (완벽한 최적화).
왜 emplace_back이 더 좋은가요?
성능 최적화: 불필요한 복사 생성자와 소멸자 호출을 방지합니다. 특히 객체의 크기가 크거나 스레드 풀의 Task처럼 이동이 복잡한 경우 차이가 큽니다.
가변 인자 템플릿: emplace_back은 우리가 스레드 풀에서 봤던 것처럼 Args&&...를 사용하기 때문에, 생성자의 인자가 몇 개든 상관없이 대응할 수 있습니다.
항상 emplace_back이 정답일까?
무조건 emplace_back이 좋은 것은 아닙니다.
가독성: 이미 만들어진 객체 변수가 있다면 push_back(std::move(obj))를 쓰는 게 의도가 더 명확할 수 있습니다.
explicit 생성자: explicit 키워드가 붙은 생성자는 push_back에서 암시적 변환이 안 되어 에러를 잡아주지만, emplace_back은 이를 무시하고 강제로 생성해 버릴 수 있어 예기치 못한 타입 변환이 일어날 수 있습니다.
lock_guard unlock 시점
lock_guard나 unique_lock 같은 RAII 객체들은 파괴되는 시점(소멸자 호출)에 락을 풀기 때문에, 개발자가 의도적으로 중괄호({ })를 사용해 락의 수명을 강제로 조절하는 기법을 아주 많이 씁니다.
이를 전문 용어로 "Scope-based Locking" 또는 "Lock Granularity(락의 세밀도) 조절"이라고 부릅니다.
왜 이렇게 범위를 쪼개야 하나요?
만약 중괄호가 없다면 어떻게 될까요?
성능 저하: 만약 task() 실행이 10초 걸린다면, 그 10초 동안 락이 계속 잡혀 있게 됩니다.
병목 현상: 다른 스레드들은 큐에서 일감을 꺼내오고 싶어도 락 때문에 아무것도 못 하고 10초 동안 줄줄이 대기하게 됩니다. 멀티스레드를 쓰는 의미가 사라지죠.
데드락 위험: 락을 오래 잡고 있을수록 다른 락과 꼬여서 프로그램이 멈출 확률이 높아집니다.
람다 캡처 방식
1. 값 복사 캡처 ([=], [x])
변수의 현재 값을 복사해서 람다 내부로 가져옵니다.
언제 쓰면 좋을까?
비동기/멀티스레드 작업: 람다가 실행되는 시점에 원래 변수가 이미 파괴되었을 가능성이 클 때 사용합니다. (가장 안전한 방법)
작은 데이터 타입: int, float, bool 처럼 복사 비용이 매우 저렴한 경우입니다.
함수형 프로그래밍: 외부 상태에 영향을 주지 않고 독립적인 계산을 수행하고 싶을 때 적합합니다.
주의점
무거운 객체(큰 std::vector 등)를 복사하면 성능 저하가 발생합니다.
람다 내부에서 값을 수정하려면 mutable 키워드가 필요합니다.
2. 참조 캡처 ([&], [&x])
변수의 주소(참조)를 가져와 원본에 직접 접근합니다.
언제 쓰면 좋을까?
즉시 실행되는 함수: std::sort, std::for_each 처럼 해당 라인에서 바로 실행되고 끝나는 알고리즘 함수에 넘길 때 최적입니다.
대용량 객체: 복사 비용이 큰 객체를 다룰 때 성능을 위해 사용합니다.
원본 수정 필요: 람다 내부에서 외부 변수의 값을 직접 바꿔야 할 때 사용합니다.
주의점 (매우 중요)
Dangling Reference(허공의 참조): 비동기 작업(std::thread 등)에서 참조 캡처를 썼는데, 람다가 실행되기도 전에 원본 변수가 스코프를 벗어나 사라지면 프로그램이 Crash 납니다.
이동 캡처 (C++14 이상)
복사하기엔 너무 무겁고, 참조하기엔 수명이 걱정될 때 쓰는 이동(Move) 캡처입니다. 우리가 스레드 풀에서 packaged_task를 다룰 때와 같은 원리입니다.
std::result_of<F(Args...)>::type
"함수 F에 인자 Args...를 넣고 호출했을 때 나올 최종 결과물의 타입"이 무엇인지 컴파일러에게 물어봐서 알아낸 그 타입 자체를 반환합니다.
왜 F(Args...) 형태인가요?
여기서 F(Args...)는 실제 함수 호출이 아니라, 함수 서명(Signature)을 흉내 내는 것입니다.
F: 호출 가능한 대상 (함수 포인터, 람다, Functor 등)
Args...: 그 함수에 전달할 인자들의 타입들
현대 C++에서의 변화
std::result_of는 C++11부터 쓰였지만, C++17부터는 std::invoke_result로 대체되었습니다. 기능은 같지만 이름이 훨씬 명확해졌고 사용법도 살짝 바뀌었습니다.
C++11/14: std::result_of<F(Args...)>::type
C++17/20: std::invoke_result<F, Args...>::type Packaged_task
future와 packaged_task는 동일한 내부 메모리(Shared State)를 공유하는 짝꿍입니다.
packaged_task는 쓰기 전용 포인터를 가짐.
future는 읽기 전용 포인터를 가짐.
ThreadPool enqueue_job에서 해당 스코프를 벗어나도 실행이 가능한 이유(shared_ptr)
과거 방식: 일반 포인터 (*)
일반 포인터는 메모리 주소만 들고 있을 뿐, "누가 나를 쓰고 있는지"에 관심이 없습니다.
문제점: EnqueueJob 함수가 끝나서 지역 변수가 파괴되어도, 큐에 들어간 람다는 여전히 그 주소만 붙들고 있습니다.
결과: 워커 스레드가 나중에 그 주소를 찾아가면? 이미 OS에 반납된 메모리라 Crash가 납니다.
해결책: 이걸 막으려면 질문하신 것처럼 별도의 '전역 컨테이너'나 '메모리 풀'을 만들어서, 모든 작업이 끝날 때까지 수동으로 메모리를 관리하고 하나씩 지워줘야 했습니다. (관리가 지옥 같았죠.)
현대 방식: shared_ptr + 람다 캡처
shared_ptr는 "참조 횟수(Reference Count)"라는 장부를 내장하고 있습니다.
혁신: 람다가 [task]를 통해 shared_ptr를 복사해서 큐로 들어가는 순간, 이 장부의 숫자가 올라갑니다.
자동화: EnqueueJob 함수가 끝나도 큐 안의 람다가 여전히 1점을 쥐고 있기 때문에, 별도의 컨테이너 없이도 메모리가 스스로 살아남습니다.
정리: 작업이 끝나고 람다가 소멸하면 장부가 0이 되고, 그제야 메모리가 스스로 사라집니다.
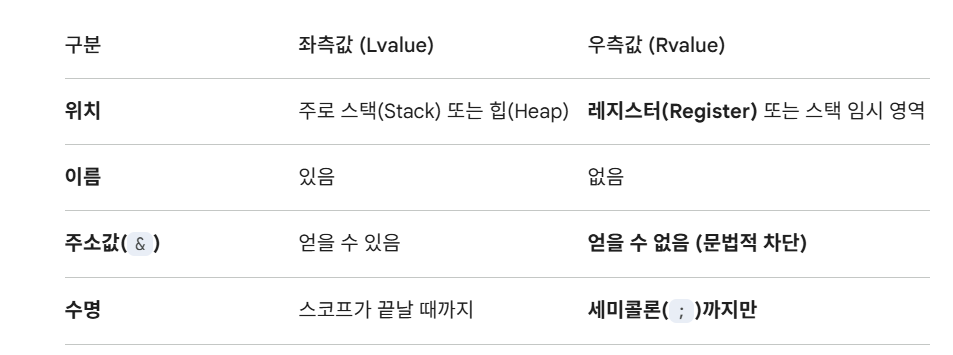
move vs forward

좌측값, 우측값 메모리 위치