Hive Sort by, Distribute by, Cluster by 활용도

Hive에서 제공하는 기능중에서 일반 SQL 에서는 볼 수 없는 기능들 중, 리듀서에 보내는 데이터를, 분류할 수 있는 아래 3가지에 대해 알아보도록 하자.
- Sort by
- Distribute by
- Cluster by
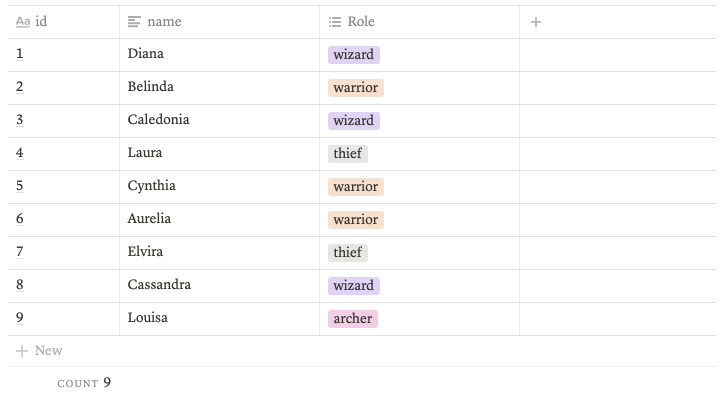
실험데이터
game_account
Sort by

얼핏 order by 와 느낌이 비슷해 보인다. 하지만, order by 는 Map-Reduce가 끝난 뒤 최종적으로 모인 하나의 리듀서에서 정렬을 하기때문에 정확히 정렬된 결과를 받을 수 있다.
order by id 작업시
select *
from game_account
order by id limit 9;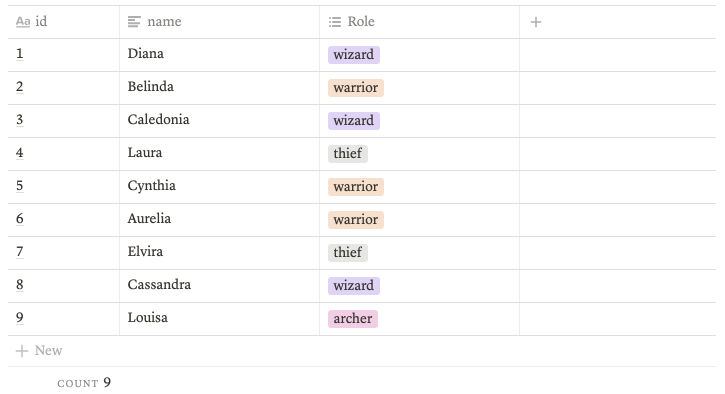
Sort by
Sort by는 최종 데이터가 모이기 전, 각 리듀서 내에서 정렬하는 역할을 한다. 때문에 sort by가 적용되면 각 리듀스 내 데이터끼리 정렬하게 된다.
2개의 리듀서 사용해 예시를 보자.
set mapred.reduce.tasks=2;
select *
from game_account
sort by id;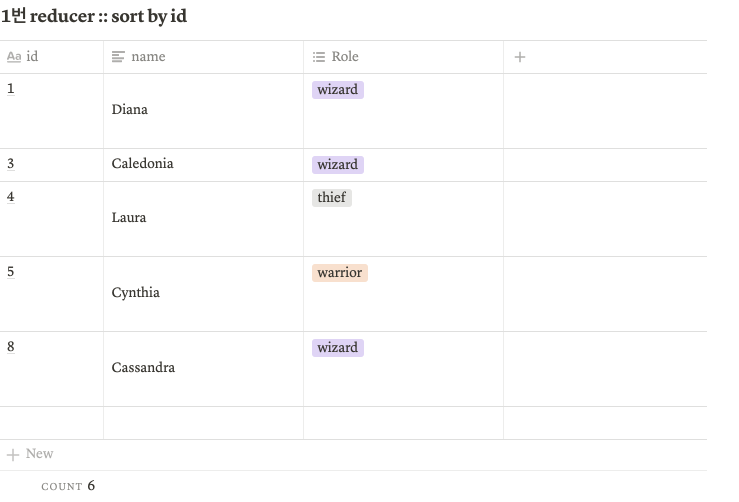

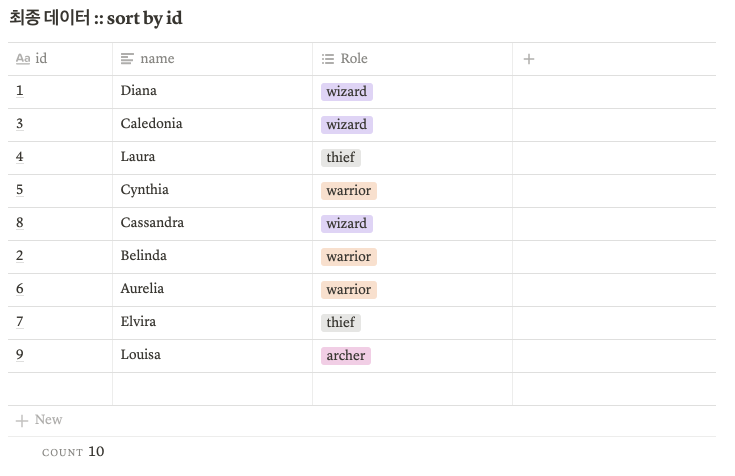
리듀서 별로 정렬된 데이터가 그대로 붙어서 결과로 나왔다. 정렬된 데이터로 사용할 수 없다.
그런데, 만약 리듀서 갯수를 설정을 통해 강제로 1개로 만들고 sort by를 진행하면 어떻게 될까?
set mapred.reduce.tasks=1결과는 order by와 동일하다 😲
정리
특징: 데이터를 저장시에 파일별로 데이터를 정렬시킬 수 있다.
장점: 리듀서의 수가 많아서, order by보다 속도가 빠르다.
단점: 최종 데이터가 정렬되지 않아 정렬용도로 사용이 불가능, select 시에는 용도가 불분명🤔
Distribute by
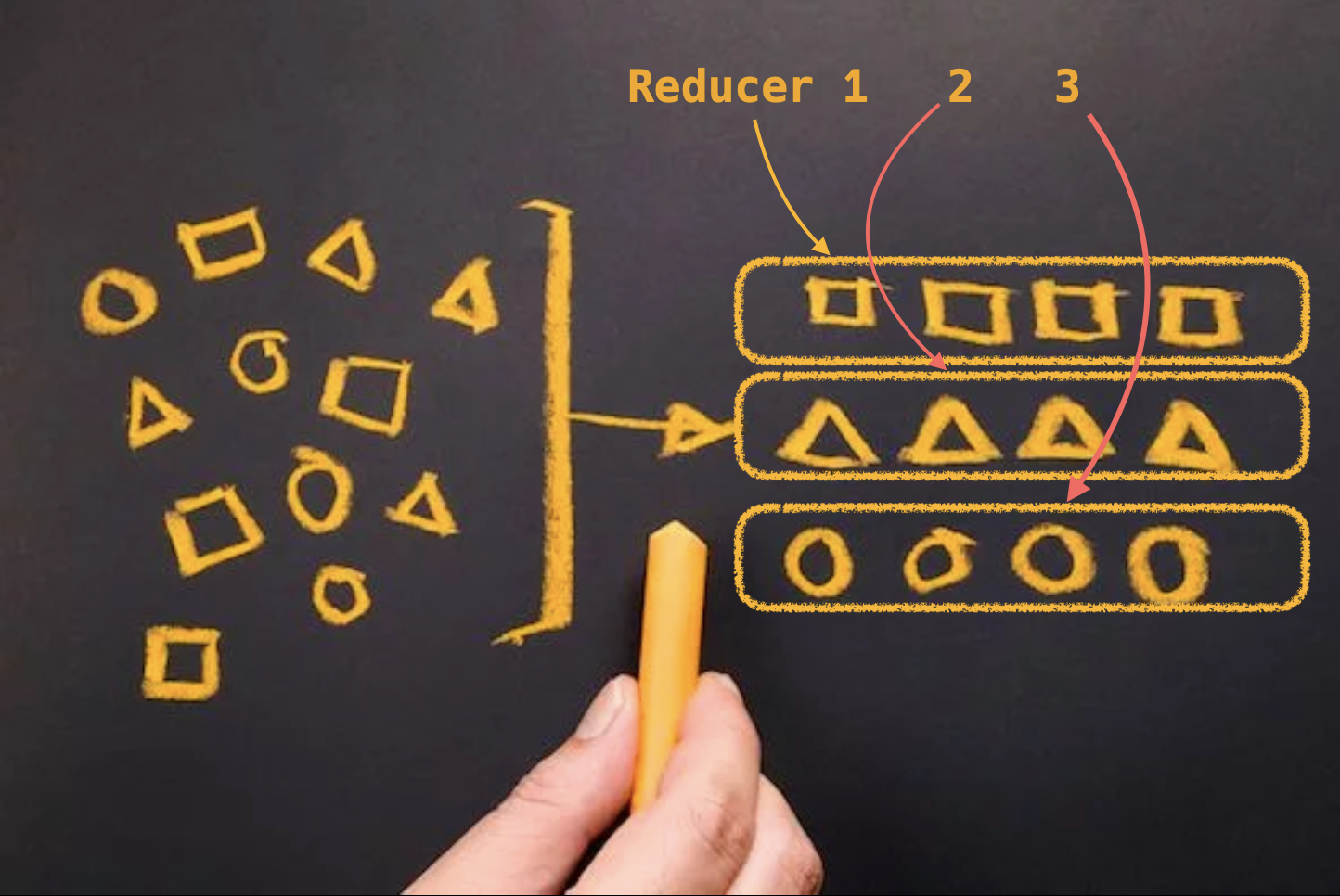
column의 값을 기준으로 distribute by 를 reducer별로 같은값이 들어가게 된다.
Distribute by는 group by 로 상상하여 접근하면 쉽다.
map 상태에서 리듀서로 데이터가 넘어갈때, 같은 column값인 데이터들끼리 묶어서 같은 reducer로 보내게 된다. (그림처럼)
만약, 한국사람들만을 모아두고 distribute by 국가 로 분류하게 되면 최종적으로 하나의 reducer 에 데이터가 몰리게 되고 저장시 하나의 큰 파일만 생성된다.
실습 예시
select *
from game_account
distribute by Role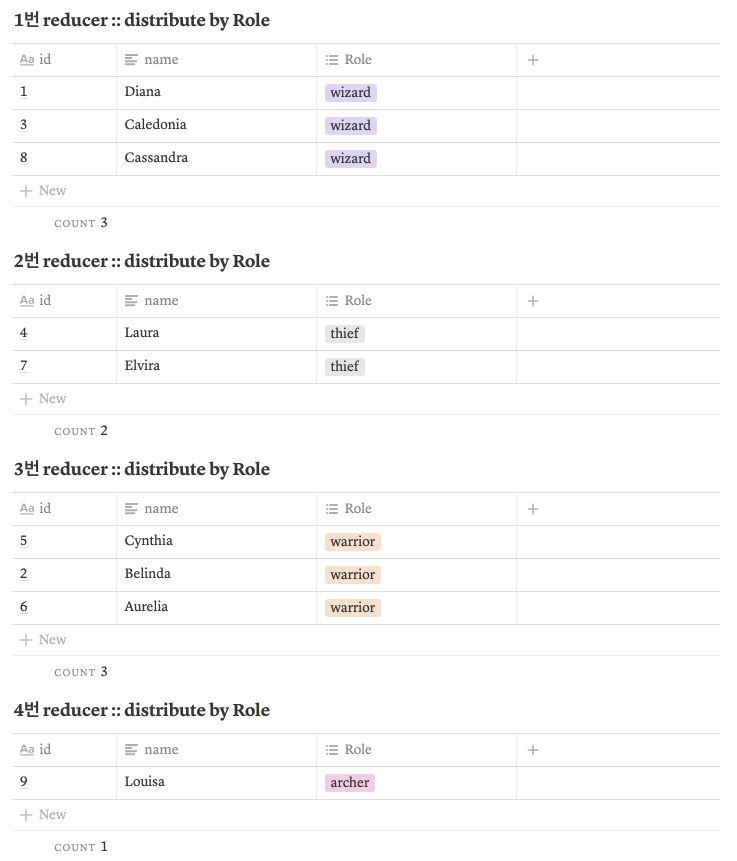
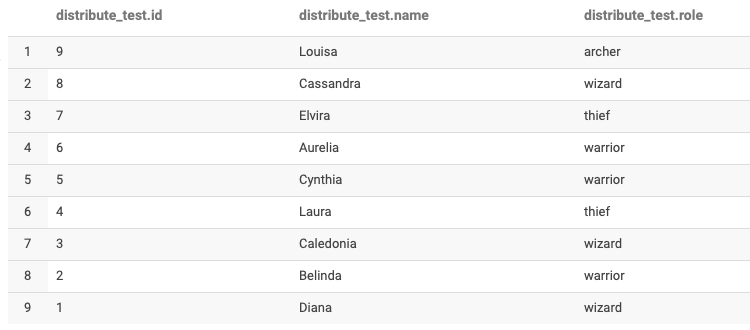
최종데이터
- 각 reducer의 파일이 각각 저장된다.
- (실제로 이렇게 작은 파일은 합쳐져 저장됨)
- select 시에는 결과가 합쳐져 나오게 된다.
정리
특징:
- 리듀서(파일) 별로 같은 column의 값만 가지도록 분류할 수 있다.
- 생년월일처럼 다양한 값으로 분류하게되면 작은 용량의 파일이 여러개 생기게 된다.
장점:
- 생성되는 리듀서(파일)의 갯수를 기준에 따라 지정할 수 있다
- 하둡에 저장된 파일을 열어보면 같은 column의 데이터들이 모여있다(장점?)🤔
- dynamic partition 을 사용할 경우 파일이 심하게 쪼개지는것을 방지해 준다.
- 파일이 심하게 쪼개질 경우 HDFS NN에 너무 많은 Transaction을 발생시켜 NN에 성능 이슈를 일으킴.
단점:
- 리듀서에 정확하게 기준별로 나뉘어 저장됨을 보장할 수 없다.
- 기준을 명확하게 세우지 않으면 리듀서 별 데이터량의 편차가 심하다.
기능의 예외:
- 생년월일처럼 다양하면 그만큼 파일갯수가 생기지 않았음을 확인했음.
- 리듀서 갯수의 제한 옵션 등이 그 이유라고 추측하였다.
- 너무 작은 데이터 본 예시와 같이 10줄도 안되는 데이터의 경우 파일이 쪼개져 저장되지 않는다.🤯
Cluster by
Cluster by 는 매우 쉽게정리할 수 있다.
Distribute by 와 sort by 를 둘다 사용하는 것이다.
- Distribute by로 기준 column을 두어 여러개의 reducer로 데이터를 나누어 보낸다.
- 여러개의 reducer에서 각자 sort by를 시행한다.
Ref
