
목차
- Step1. sample값은 바뀔 수 있다
- Step 2. 왜 sample값은 왜 바뀔까
- Step 3. 결론
조건
- pyspark 기준으로 실험, 결과를 작성하였습니다만, 최대한 spark 전반적으로 통용되는 내용을 기록합니다
- 본 문서에서의 sample() API는 dataframe 기준으로 이야기합니다
Step1. sample값은 바뀔 수 있다
문제정의
언제 샘플링을 사용할까?
Spark를 활용하여 대용량의 데이터를 다루다보면, 필요에 의해 데이터의 샘플링을 진행할 경우가 다수 발생한다. 아래 2가지 예시 포함 다양한 이유로 샘플링을 사용한다.
- 1) A/B테스트 등을 위해 모수를 중복없이 여러개의 샘플로 나눌때
- 2) 모델 학습을 위한 학습 / 테스트셋 분리를 위한 샘플링 등
pyspark 에서 제공하는 sample 함수 살펴보기
샘플링을 위해 Spark에서 많이 사용되는 API는 sample(), randomSplit() 정도가 있다. 이 문서에서는 sample()에 대해서 지원하는 기능을 살펴본다.
- sample() API는
3가지 파라미터를 입력받을 수 있으며, 모두 optional 하다
- withReplacement : 복원추출 여부. 기본설정이 False
- fraction: 추출할 sample의 비율을 지정하며, 0.0 ~ 1.0 사이의 값을 입력받음. (가장 많이 쓰이는 파라미터)
- seed: 샘플링에 활용되는 seed값. 미력입시 랜덤으로 적용되어, 출력때마다 다른 값이 나온다.
sample() API에 당연하게 기대하는 기능은 무엇일까?
-
fraction 비율에 딱 맞는 sample개수
-
sample() 을 통해 뽑힌 df_sample은 고정된 row 들을 보유하고 있다.
# df -> id=[0,1,2,3,4,5,6,7,8,9] 10개 # df_sample -> id=[1,3] 2개 # ex. row 10개 일때 frac=0.2 이면, 항상 2개가 나와야해 df_sample = df.sample(fraction=0.2) # ex. df_sample -> id=[1,3]이니까, tb_test에도 id=[1,3]이 담겨있을거야 # tb_test -> id=[1,3] 2개 ? df_sample.write.saveAsTable("tb_test")
하지만, 이 API만 믿고 사용하다가는, A/B 테스트등의 샘플링을 활용한 실험에서 실수를 범할수도 있다.
sample값이 항상 다른지 실험해보자
데이터 준비
- 어떤 로그 테이블에서 id로 활용하기위해
unique_key값을 생성하였고, 그 수는 약 2.75억개이다
q = """
select *
from tb_test
where log_type_code='...' and date_id='2022-09-01'
"""
df = spark.sql(q)
df = df.select("time_id","user_id","item_id").distinct()
df = df.withColumn("unique_key",f.concat_ws("_","time_id","user_id","item_id"))
print(f"{df.count():,}") # 275,791,779
sample 개수 확인
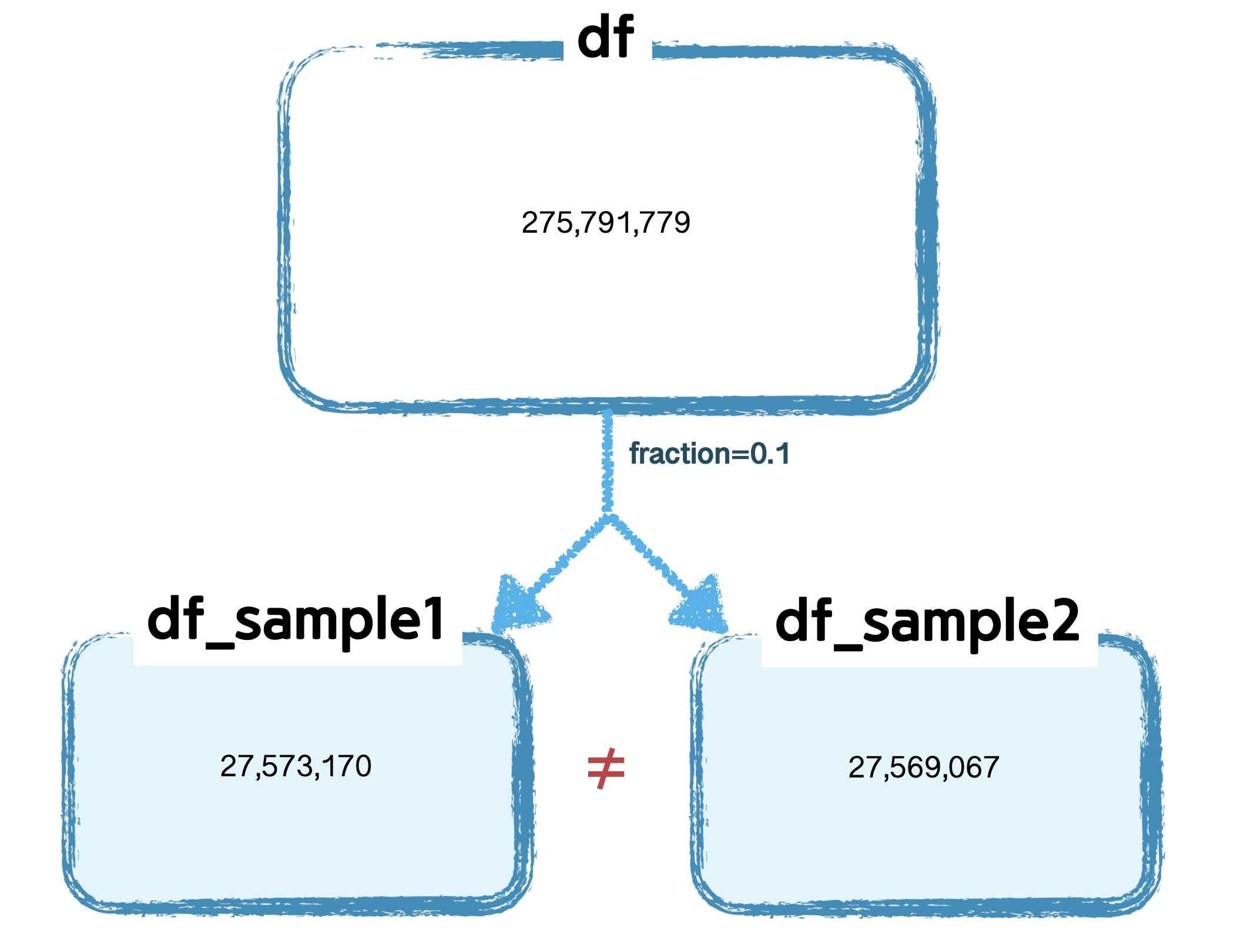
- 동일하게 fraction을 0.1만큼 sample 비율로 취하고 그 값을 확인해 보면, 서로 다른 값이 나옴을 확인할 수 있다
- 이상적으로는 약 27,579,177 개가 뽑혀야 하지만, 아래 val1, val2 값 모두 이보다 적은 수가 추출되었다.(더 많이 나올수도 있다)
- 이로써 ‘
fraction 비율에 딱 맞는 sample개수’는 보장되지 않음을 확인할수있다
val1 = df.sample(fraction=0.1).count()
val2 = df.sample(fraction=0.1).count()
print(f"{val1:,}") # 27,573,170
print(f"{val2:,}") # 27,569,067
seed 고정 후 sample 개수 재확인
- 설명
- 앞의 실험을 보면 sample() 결과는 값이 유지되기는 커녕, 개수(row count)조차 달랐음
- seed값을 부여하면, 같은 개수의 고정된 값을 가질수 있을까?
- sampling 후 테이블에 저장
- seed 값을 고정하고 sampling 을 진행한
df_sample을 테이블 2개에 저장함 - 저장한 2개 테이블을 읽어, 각각 df_v1, df_v2를 생성
- 테이블 save & load를 하는 이유는 - sample 결과를 파일로 고정시켜두기 위함
- seed 값을 고정하고 sampling 을 진행한
- 테이블 v1, v2 row count 비교
- 두 테이블이 동일한지 정합성을 확인
- 같은 df이므로,
row count도 같고, 포함된unique_key가 같아야 할것이라 예상해본다. - 비교결과
- row count 수는 동일하지만, 두 테이블의 unique_key 가 동일한 값은 약 10% 밖에 되지않음
- 같은 df로 만든 2개의 테이블이지만, 값이 서로 다르다
- 코드에는 없지만, 원본 df_sample 과 비교해도 정합성은 맞지 않는다.
########### 1. sampling 후 테이블에 저장 ###########
df_sample = df.sample(0.1,seed=10)
print(f"{df_sample.count():,}") # 27,576,224
tb_name_v1 = "user_rupert.z_tmp_spark_random_seed_test_v1"
tb_name_v2 = "user_rupert.z_tmp_spark_random_seed_test_v2"
df_sample.write.mode("overwrite").saveAsTable(tb_name_v1)
df_sample.write.mode("overwrite").saveAsTable(tb_name_v2)
df_v1 = spark.sql(f"select * from {tb_name_v1}")
df_v2 = spark.sql(f"select * from {tb_name_v2}")
########### 2. 테이블 v1, v2 비교 ###########
val1 = df_v1.count() # 27,576,224
val2 = df_v2.count() # 27,576,224
########### 2-1. 테이블 v1, v2 교차량 비교 ###########
# 차집합 (v1 - v2, v1테이블에만 있는 개수)
# 24,792,477
n_only_in_v1 = df_v1.join(df_v2,on="unique_key",how="left_anti").count()
# v1 ⋂ v2 교집합 개수
# 2,783,747
n_intersection = df_v1.join(df_v2,on="unique_key",how="left_semi").count()
# 차집합 (v2 - v1, v2테이블에만 있는 개수)
# 24,792,477
n_only_in_v2 = df_v2.join(df_v1,on="unique_key",how="left_anti").count()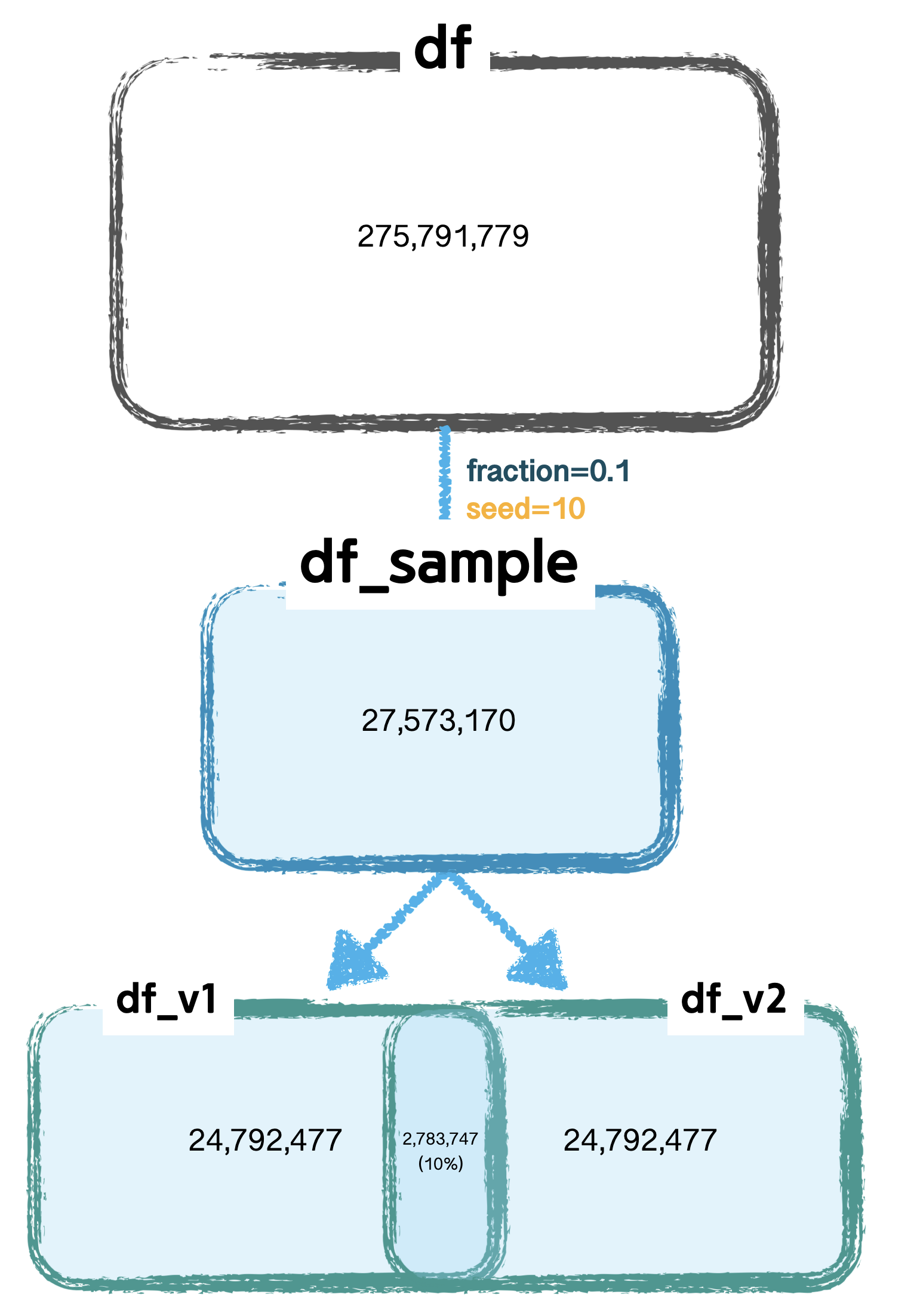
실험결과
fraction 비율에 딱 맞는 sample개수는 보장되지 않는다- seed를 고정하여도, sample() 을 통해 뽑은
sample에 담기는 row가 바뀔수 있다
Step 2. 왜 sample값은 왜 바뀔까
문제정의
- Step1 의 실험결과인 2가지의 원인을 파악하기 위해 아래의 것을 확인해본다
- sample() API의 동작방식
- Lazy Evaluation
sample() API의 동작방식
1. 베르누이 샘플러
- sample() API는 2가지 sampler 를 사용함
- 비복원추출 (withReplacement=False) → BernoulliCellSampler()
- 복원추출 (withReplacement=True) → PoissonSampler()
- 지금은 비복원추출의 경우에 대해 다루고 있으니, 베르누이 샘플링 방식에 대해 간단히 다룸 (sampler에 따라 동작방식이 달라짐)
- 베르누이 샘플링을 이해하면 쉽게 Step1 의 실험결과를 납득할 수 있다
- 그밖의 spark의 sampler class 목록 , 푸아송샘플러 예시
1-1. 베르누이 샘플링 방식
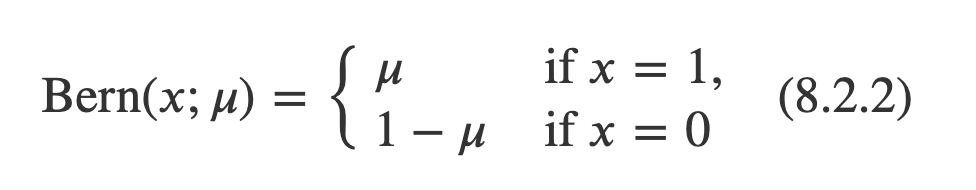
- 참조: datascienceschool
- 베르누이 시행: 결과가 두 가지 중 하나로만 나오는 실험이나 시행을 베르누이 시행(Bernoulli trial)이라고 한다. 예를 들어 동전을 한 번 던져 앞면(H:Head)이 나오거나 뒷면(T:Tail)이 나오게 하는 것도 베르누이 시행이다.
- 1이 나올 확률( 𝜇 ) : 동전 앞면이 나올 확률
- ex) 동전 앞면이 나올 확률이 (𝜇=0.5) 일때, 100번 던졌을때 ‘
기대값에 따르면 50번 앞이 나올 확률’이 가장 높지만, 50번보다 더 나올수도 덜 나올수도 있음.
2. sample() api 다시 살펴보기
- step 1에서 sampling 실험을 위한 코드의 physical plan을 살펴본다
- Sample 뒤로, 1) 확률 구간 2) 복원추출여부 3)seed값 파라미터가 부여됨
- 확률 구간을 기억하며,
1-1의 동전던지기를 생각해보자. 0~1 사이의 랜덤값이 나오는 상황에서 𝜇=0.1 로 설정하고 각각의 row가 독립적인 random 값을 부여받고, 확률구간(0.0 ~ 0.1)에 포함되면 sample에 포함! 이라고 판단함 ex) 앞면이 나올 확률이 𝜇=0.1 인 동전을 10명이 각자 던져서, 앞면이 나온 사람이 뽑힌다
df.sample(0.1,seed=10).explain()
# output
== Physical Plan ==
*(2) Sample 0.0, 0.1, false, 10
+- *(2) HashAggregate(keys=[time_id#6, user_id#7L, item_id#26], functions=[])
+- Exchange hashpartitioning(time_id#6, user_id#7L, item_id#26, 200)
+- *(1) HashAggregate(keys=[time_id#6, user_id#7L, item_id#26], functions=[])
+- *(1) Project [time_id#6, user_id#7L, item_id#10 AS item_id#26]
+- Scan hive tb_test [log_info#10, time_id#6, user_id#7L], HiveTableRelation `tb_test`, org.apache.hadoop.hive.serde2.columnar.ColumnarSerDe, [time_id#6, user_id#7L, ...]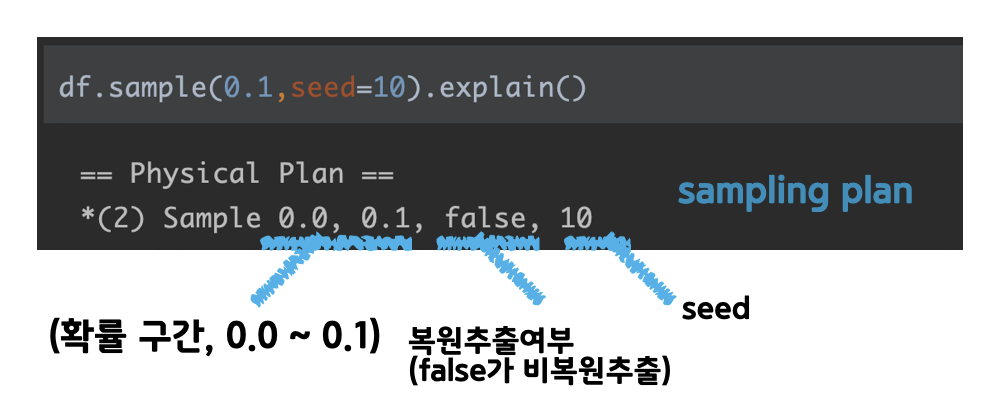
2-1. 베르누이 샘플러 예시
- 아래 예시는
sample 0.0, 0.5, false, 11로 plan 되어있다고 생각할 수 있음(𝜇=0.5) - 파티션(파일) 2개 데이터에 대해 베르누이 샘플링이 수행됨
- 총 14개의 숫자 중, 8개 row의 랜덤값이 0.5미만으로 나와서 sample()로 선택되었음
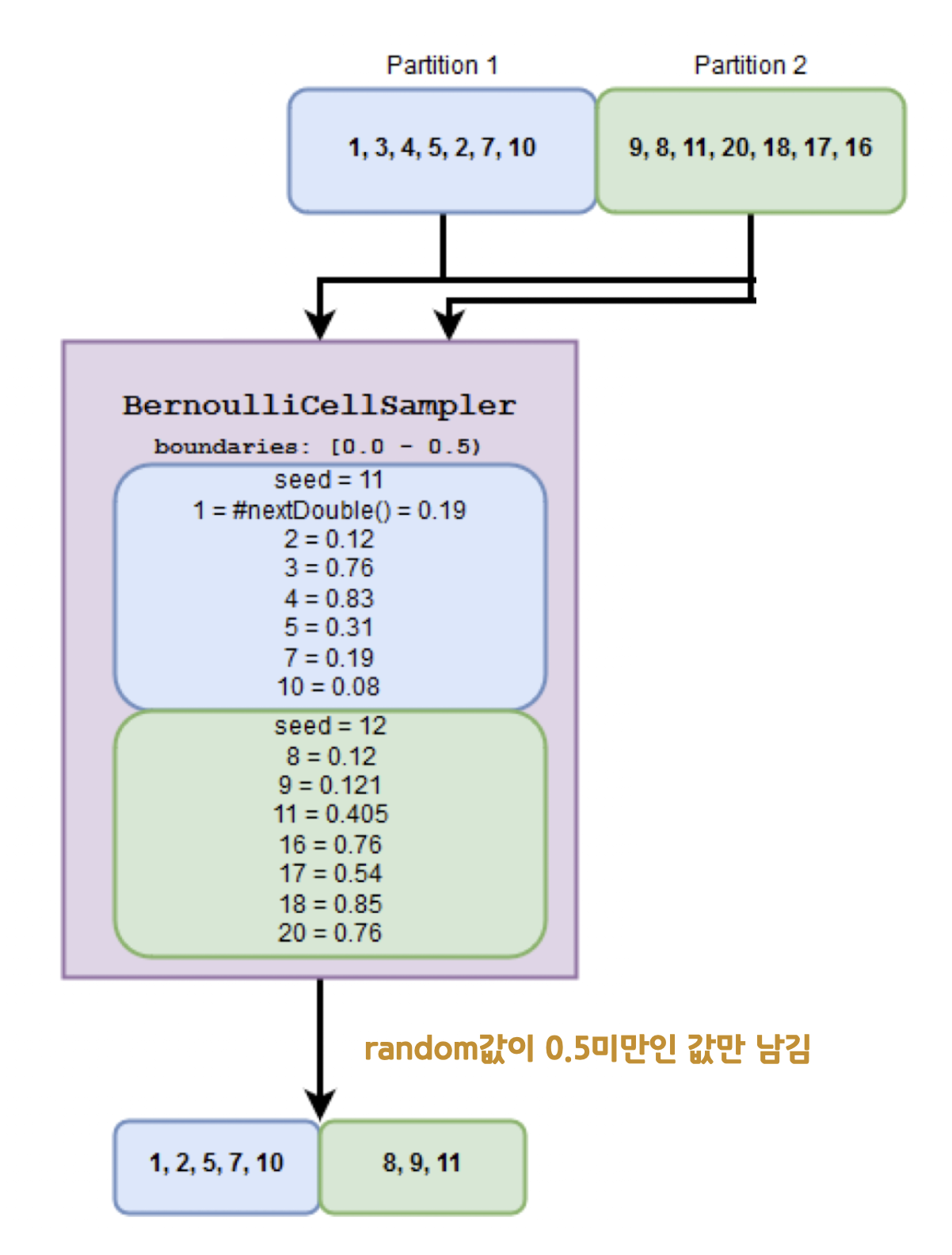
https://www.waitingforcode.com/apache-spark-sql/randomsplit-implementation-apache-spark-sql/read
Lazy Evaluation
같은 df_sample로 만들었지만, 결과가 다르다
- 1개의 df_sample로 테이블을 2번 만들었지만, v1 ⋂ v2는 정확히 일치하지 않았음
- 그 원인은 write (action) 이 수행될때마다, sample()이 다시 이뤄는 spark의 Lazy Evaluation 특성때문
########### 1. sampling 후 테이블에 저장 ###########
df_sample = df.sample(0.1,seed=10)
print(f"{df_sample.count():,}") # 27,576,224
df_sample.write.mode("overwrite").saveAsTable("user_rupert.z_tmp_spark_random_seed_test_v1")
df_sample.write.mode("overwrite").saveAsTable("user_rupert.z_tmp_spark_random_seed_test_v2")
df_v1 = spark.sql("select * from user_rupert.z_tmp_spark_random_seed_test_v1")
df_v2 = spark.sql("select * from user_rupert.z_tmp_spark_random_seed_test_v2")
Step 3. 결론
sample() API에 당연하게 기대하는 기능을 어떻게 쓸까
- fraction 비율에 딱 맞는 sample개수
- sample() 값을 고정시키기
fraction 비율에 딱 맞는 sample개수
- 1000만개 row 중 정확히 100만개를 추리고 싶다면, 여유있게 fraction 값을 주고, limit() 으로 잘라 사용할 수 있다
import pyspark.sql.functions as f
df.sample(0.15,seed=10).sort(f.rand(seed=10)).limit(1_000_000)sample() 값을 고정시키기
- 메모리에 올라가 있는 dataframe에 랜덤요소(sample)가 부여된 이후엔, 파일로 저장전까지 바뀔수 있다고 생각하는게, 다루기에 용이함
- 간단히 고정하는 방법은 캐싱(cache(), persist()) 를 사용하는것
- 하지만, 캐시가 풀릴 수 있으니 1개의 테이블(파일) 로 저장하고 다시 read해서 쓰는것을 개인적으로 추천
########## 방법 1 ###########
df_sample = df.sample(0.1,seed=10).cache() # 한번 action이 되면, df_sample값이 고정됨
df_sample.count() # 단순히 action 수행목적
df_v1 = df_sample
df_v2 = df_sample
########## 방법 2 ###########
df_sample = df.sample(0.1,seed=10)
df_sample.write.mode("overwrite").saveAsTable("user_rupert.v1")
df_sample = spark.sql("select * from user_rupert.v1") # 파일로 쓰고, 이후엔 그걸 사용함
df_v1 = df_sample
df_v2 = df_sample
ETC
그 외 랜덤값 사용사례
- 사용자도 모르는 사이 고정되지 않는 랜덤값이 사용될때가 많은데, 그 중 하나는 window 함수를 사용할때임.
- 예를들어 컬럼의 순서를 정하는
row_number()사용할때 발생할 수 있음
references
- https://medium.com/udemy-engineering/pyspark-under-the-hood-randomsplit-and-sample-inconsistencies-examined-7c6ec62644bc
- https://www.waitingforcode.com/apache-spark-sql/randomsplit-implementation-apache-spark-sql/read
이미지 출처
- Photo by Alexander Grey on Unsplash
- Photo by Andriyko Podilnyk on Unsplash

hi there