
5. 기타 현업
이건 회사에서 배운 개념인데 코드 리팩터를 진행할 때 api들을 관리하는 방법에 대해 간략히 남겨봅니다. (물론 사람마다 회사마다 방식이 당연하게도 다를 수 있다.)
기본적인 파일 참조 관계(서버)
app.js ← router ← api ← service ← handler + a(자신만의 규칙, 약속을 담은 constant, fcn 파일 등)
5.1. handler
handler는 반복되는 동작에 관한 함수들을 하나의 파일에 묶어 모듈 처럼 사용하는 개념이다.
예를들어 dynamoDB에 데이터를 추가, 삭제, 편집, 쿼리, 읽기 등의 작업을 하고 싶다면(자세한 파일 구조와 로직은 적을 수 없다. ㅠ_ㅜ)
const dynamoDB = require('./../dynamoDB'); // dynamoDB 매서드를 담고있는 파일
// const mySQLDB = require('./../mySQLDB'); - mySQL 매서드를 담고있는 파일
const dynamoTest = async () => {
const data = [
{ id: 1, name: 'lee', age: 25},
{ id: 2, name: 'kim', age: 30},
{ id: 3, name: 'choi', age: 35},
];
// 쿼리 조건문, 임의의 약속은 상기 임포트파일에 규칙화되어 있다.
const queryParams = {
KCE: '#k1 = :key1 and #k2 = :key2',
EAN: { '#k1': 'key1', '#k2': 'key2' },
EAV: { ':key1': myKey1, ':key2': myKey2},
}
// push : 테이블 > 항목 생성
const result1 = await dynamoDB.push(data);
// delete : key1 = myKey1 & key2 = myKey2인 데이터를 해당 dynamoDB테이블 > 항목에서 삭제한다.
// 테이블의 특정은 역시 상기 임포트파일에 규정되어 있다.
await dynamoDB.delete(queryParams);
// set : key1, key2를 기준으로 쿼리한 데이터의 내용을 'data'에 정의된 내용으로 업데이트한다.
await dynamoDB.set({
Key : {
key1 = myKey1,
key2 = myKey2
}
data
});
// query : 쿼리조건을 만족하는 데이터를 쿼리해온다.
const data1 = await dynamoDB.query(queryParams);
// get : 쿼리조건을 만족하는 데이터를 가져온다.
const data2 = await dynamoDB.get(queryParams);
const result2 = data1 === data2 ? true : false;
}dynamoDB와 연결이 되었는데, 뭔가 찜찜한점이 있습니다. 다음 다룰 내용은,,
5.2. cdn(캐시)
바로 cdn 인 redis를 사용하지 않았다는 점! 현업에서 규모 있는 기업들(유저 수가 많고 제공하는 서비스가 다양한)의 경우
[앱] → [클라이언트 클릭(요청)] → [DB] → [클라이언트 화면노출(응답)]
과 같이 DB를 바로 거치는 방법은 지양하며 cdn를 거쳐 클라이언트에게 응답하게 된다.
AWS s3 : 이미지파일, 일부 json형식 → cdn : cloudFront → client
AWS dynamoDB : NoSQL data → cdn : redis → client
cdn란?
노르웨이산 연어를 구매하기 위해 현지 생산공장에 주문하여 상품을 바다건너 받을 것인지, 나같은 노르웨이 연어 소비자가 있을것이라 예상한 수산 도매업자가 미리 수입해 들여온 연어를 국내 주문하여 쿠팡배달 받을 것인지의 차이이다. 쿠팡이 족히 몇배는 빠를 것.
클라이언트의 요청은 백엔드 서버 → 저장소(DB 등) 요청으로 이어지는데 실제 DB까지 방문 후 데이터를 긁어와 클라이언트에게 내려주는 과정은 시간상 비효율적. CPU는 기본적으로 메모리에 저장된 데이터를 가져와 일을 처리하는데 이 때 CPU - 메모리(저장소)간 거리(물리적 거리가 아닙니다!)를 줄여주기 위해 중간장치 역할을 하는 것이 캐시(cdn)이며 예측되는 클라이언트 요청에 대한 데이터를 미리 쿼리하여 캐시데이터로 저장 → 사용자의 요청에 해당하는 데이터를 get from 캐시. 이러한 캐시는 대게 용량이 작지만 매우 빠릅니다.
(redis 와 같은 캐시데이터베이스를 inMemoryDB라고 부릅니다)
redis hash, value
redis에서 DB에 저장된 데이터를 내려받아 올 때 hash를 생성 → 해당 hash값 삭제 시 value(값) 갱신
따라서 소스에
- hash 생성(매 db를 load할 때 마다)
- hash 삭제(생성, 삭제, 업데이트 시)
코드를 작성해 주어야 합니다.
5.3. package.json
노드를 사용하다보면 package.json 이라는 파일이 보일 겁니다 (+ package.lock.json 까지!)
생성 : npm init
별도 수정하고 싶은 내용이 없다면 enter~
생성된 package.json 파일(default)
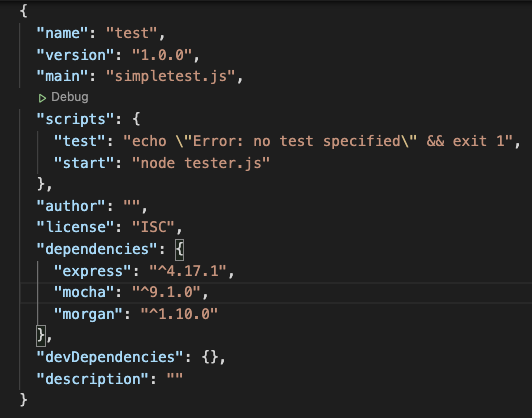
-scripts
단축키를 설정하는 프라퍼티
-autohor
당신의 이름
-dependencies
설치한 npm 모듈들을 보여주고 있습니다. 해당 모듈들은 해당 서버를 구동하기 위해 필수적인 모듈들입니다. 설명을 더하자면 하나의 모듈은 보통 다수의 모듈들에 의존하는 관계인데 이에 대한 관계를 전부 풀어낸 파일이 package.lock.json 파일입니다.
-devDependencies
개발용으로만 설치한 모듈들을 담고있는 프라퍼티 입니다. 만약 Github에 퍼블릭으로 공유한 모듈이나 서버파일이 있다면 다운로드 후 npm i 커맨드를 입력해 의존모듈들을 다운로드 받더라도 이 dev 프라퍼티에 존재하는 모듈들은 설치되지 않으며 당연히 기능적으로 영향을 주지 않습니다.
-eslint
소스코드 작성 법을 규칙화하는 장치로 확장파일을 설치해야 합니다. 취향껏 받아 쓰실 수 있길. 에디터마다 확장파일 설치법이 다르니 구글에 잘 찾아보고 하시길~~
5.4. package.lock.json
앞서 설명대로 package.json 파일에 저장된 모든 의존모듈들이 2차, 3차, 4차 ~~차 로 의존하고 있는 모듈들을 중복을 제거하고 보여주는게 이 pacakge.lock.json 파일입니다. 해당 모듈들의 버전은 고정(lock)되어 있어 모듈들이 업데이트, 삭제되어 충돌하는 문제를 어느정도 예방할 수 있습니다.(버전 충돌방지)
그냥 너무 많다. 짱짱 많다.
5.5. cronServer
크론서버는 시간예약, 지정등을 전담하는 서버이다.
회사에선 푸쉬메시지 예약발송 용도로 많이 사용하고 있다. 최근 데이터베이스 연동이슈로 새로이 로직을 만들며 공부를 많이한 것 같다.
cronTime
?? ?? ?? ?? ?? ?? = 초 분 시 일 월 요일
00 30 03 01 09 * : 9월 1일 오후 12시 30분 00초
요런 식으로
' - ' : 범위
' * ' : every
' ? ' : 미정
' */ ' : 매 ~ 마다
를 활용해서 cronTime을 설정한다.
그렇다면 cronTime을 설정함은 무얼 의미하는가
cronTime에(반복설정이라면 ~마다) 해당 파일이 컴파일된다고 생각하면 편하다.
예를들어 pushMsg.js 파일의 cronTime을 12시로 설정하고 미리 노드서버를 돌려주면(당연히 서버가 돌아가야 크론이 예약된 시간에 맞춰 돌게된다.) 12시에 맞춰 pushMsg.js 파일의 소스가 컴파일되는 것. pushMsg.js파일의 소스 내용이 "유저에게 푸쉬메시지를 보냄" 이라면 CronServer를 구동함으로써 12시에 유저에게 푸쉬메시지를 보내게 되는것이다.
5.6. CronServer DB 연결
DB연결은 핸들러를 구축해 두었다면 핸들러의 사용만으로 가능하다.
위 서버에서 DB연결과 마찬가지로 진행하여 준다.
메시지 전송파일을 작성한다 치면
pushMsg.js
conTime = * * * * * *;
/*
1. DB연결
2. DB로부터 데이터 쿼리
3. 쿼리한 데이터를 메시지 전송 매서드의 인자로 적용
4. 2,3을 포함한 매서드를 cronTime에 콜백 매서드로 설정해줌.
*/[메시지 전송 동작 순서]
cronServer 구동→ cronTime에 DB쿼리 - 해당데이터 메시지 전송 소스를 담고있는 매서드를 콜백으로 등록
→ cronTime에 도달 시 콜백함수 호출
→ 해당 데이터 메시지 전송
5.7. Token 방식과 Topic방식
메시지 전송 대상을 지정할 때 그룹 유저에게 전송 vs 단일유저에게 전송 방법에 대해 매서드를 분리할 필요가 있다. 대게 단일유저에게 메시지를 보내는 경우는 특수한 경우(당첨 / 경고 / 포인트획득) 등의 경우인데 이 떄 유저의 아이덴티티가 메시지 내용에 포함돼야 할 수 도 있기 때문이다. 반면 그룹유저에게 전송하는 메시지는 단체메시지의 성격이기 때문에 유저 정보가 들어갈 일이 없다.
단일 : Token방식
다수 : Topic방식
유저 정보는 SQL인 Mysql에 저장하여 다루는 것이 타당하기 때문에 Mysql에서 유저정보를 쿼리하여 가져온다면, 쿼리의 기준이 되는 key값이 필요하다.
여기서 중요한점은...
Token : Mysql 에서 데이터를 쿼리해 와 send매서드에 인자로 삽입한다.
Topic : 유저 계정 혹은 디바이스에 할당 된 토픽(고유 그룹 번호)이 있으며 그저 send에 토픽을 태워주기만 하면 자동으로 메시지를 뿌려준다. 쿼리하거나 가져올 데이터가 없는 것이다!
const DynamoHandler = require('...');
const MysqlHandler = require('...');
// 별도 DB연동이 필요하지 않다.
const keyForGroup = topics/000 // 000토픽(그룹)에 포함된 유저
const msg = makeMsg(keyForGroup, ...); // 메시지 생성(by group key)
sendMsg(msg); // 메시지 전송
// 푸쉬할 메시지 정보를 담고있는 dynamoDB에서 지정된 유저 정보(키 : 데이터)중 데이터를 빼내와 해당 데이터를 이용해 mysql에서 데이터를 쿼리해 온다.
const queryParams = {
...
};
const msg = await DynamoHandler.query(queryParams);
const { ...userCode... } = msg;
// mysql에서 유저 특정
const user = await MysqlHandler.get({ where: {code: userCode}});
const msg = makeMsg(user, ...); // 메시지 생성(by user token)
sendMsg(msg); // 메시지 전송내가 작업한 상세내용
- 크론서버 > push파일 > 데이터베이스 연동
- 크론서버 > push파일 > 크론타임 설정
- 크론서버 > push파일 > topic / token 키값 수정 관리
