✒️ 서론
일전에 MVC와 MVVM 등의 아키텍처 패턴을 공부하며 이 글에서 클린 아키텍처에 대해 가볍게 다룬 적이 있다.
이번에 새로 사이드 프로젝트에 참여하게 되었는데, MVI + Clean Architecture 패턴을 사용하는 프로젝트였기 때문에 클린 아키텍처에 대해 다시 한번 공부하고자 해당 글을 보니 무슨 소리인지 모르겠어서 다시 제대로 정리를 해보려고 한다.
🧠 핵심 요약
클린 아키텍처는 소프트웨어 설계의 거장으로 불리는 로버트 C. 마틴(Uncle Bob)이 제안한 개념으로, 유지보수와 테스트가 쉽고, 기술 변화에 독립적인 시스템을 만드는 것을 목표로 한다.
클린 아키텍처의 가장 중요한 개념은 의존성 규칙(Dependency Rule)과 계층 분리(Layer)이다.
✅ 클린 아키텍처 개요
클린 아키텍처를 가장 쉽게 이해하는 방법은 양파 구조 또는 동심원 구조로 생각하는 것이다.
클린 아키텍처를 공부했다면 위와 같은 이미지를 많이 봤을텐데, 이것이 클린 아키텍처의 구조를 가장 잘 표현하는 이미지이다.
앞서 말했듯 가장 중요한 것은 의존성 규칙인데, 그림에서 Dependence가 표현하는 것이 의존성의 방향이다. 의존성은 항상 안쪽 방향으로만 향해야 하며, 안쪽 계층의 원은 바깥쪽 계층의 원의 존재를 알지 못해야 한다.
바깥쪽 원일 수록 구체적인 구현 기술(프레임워크, 데이터베이스, UI 등)을 관리하는 영역이고, 안쪽 원일 수록 추상적인 비즈니스 로직(핵심 규칙)을 담당하는 영역이 된다.
예전에는 이 개념이 잘 이해가 가지 않았는데, 코드로 표현하면 아래와 같다.
Controller(Presenter(UseCase(Entity)))즉, Controller는 Presenter를 소유하고 있고, Presenter는 UseCase를, UseCase는 Entity를 소유하고 있는 형식이다.
이 때,Entity는 모든 레이어에서 의존성을 가지고 있기 때문에 가장 변화가 적어야 하고, 바깥쪽 모든 레이어에 대해 아무것도 몰라야 한다.
이 규칙을 지키면, 가장 중요한 비즈니스 로직(안쪽 레이어)이 데이터베이스나 UI(바깥쪽) 같은 구체적인 기술적 세부 사항으로부터 독립된다.
이 덕분에 테스트 용이성이 증가되는 것이다.
✨ 주요 4개 계층 설명
클린 아키텍처는 일반적으로 네 개의 주요 계층으로 나뉘며, 안쪽에서 바깥쪽으로 나열된다.
1) Entities(엔티티) - 최상위 핵심
- 역할: 앱의 가장 핵심적인 비즈니스 규칙을 정의. 앱 전체에서 사용되는 데이터 구조와 그 데이터를 조작하는 로직을 포함한다.
- 특징: 가장 순수하며, 어떤 프레임워크나 외부 데이터베이스에도 의존하지 않는 순수한 Swift 객체(struct/class)로 구성된다.
2) Use Cases(사용 사례)
- 역할: 앱이 제공하는 특정 기능을 정의한다. 엔티티를 사용하여 앱의 고유한 비즈니스 로직을 구현한다.
- 특징: 이 계층은
protocol을 사용하여 다음 계층(Interface Adapters)과 통신한다. 어떤 데이터를 사용하고, 어떻게 처리할지에 대한 순수한 로직을 포함하고 있다.
3) Interface Adapters(인터페이스 어댑터) - 변환 계층
- 역할: Use Cases와 프레젠테이션 계층(View/ViewModel) 또는 데이터 영속성 계층(Repository) 간에 데이터 형태를 변환하는 역할을 한다.
- 특징: MVVM/MVI 패턴의 ViewModel/Presenter(Reactor)가 여기에 해당된다. UseCase의 결과를 UI가 이해할 수 있는 형태(ViewModel)로 변환하거나, UI 이벤트를 UseCase가 이해할 수 있는 형태로 변환한다.
4) Frameworks & Drivers(프레임워크 및 드라이버)
- 역할: 가장 외곽 계층으로, 외부 기술이나 인프라에 의존하는 모든 코드를 포함한다.
- 특징: 이 계층은 가장 많은 외부 의존성을 가진다.
UIView,CoreData,EventKit,Alamofire등의 구체적인 구현이 여기서 이루어진다.
🔄 의존성 역전 원칙(Dependency Inversion Principle, DIP)
의존성 규칙을 지키는 핵심적인 방법이 바로 의존성 역전 원칙이다.
이는 주로 UseCase에서 이뤄지는데, 아래 예시를 통해 알아보자.
문제: UseCase는 Data Layer의 저장 기능이 필요하다. 그러나 안쪽 계층인 UseCase는 바깥쪽 계층인 Data Layer를 직접 참조할 수 없다.
해결 방법: UseCase는 Data Layer에게 필요한 기능(저장, 조회 등)을
protocol로 정의한다. Data Layer의 구체적인 클래스는 이 때 만들어진protocol을 채택하여 구현한다.
이로써 "데이터 저장이 필요하다"는 추상적인 개념(프로토콜)이 "데이터를 저장하는 구체적인 코드(클래스)"보다 더 안쪽(Domain)에 위치하게 된다. 즉, 의존성의 방향이 역전되는 것이다.
텍스트로만 보면 이해가 어렵기 때문에 코드를 예시로 알아보자.
의존성 역전 원칙 예시
// Entity
struct ExampleEntity {
let id: UUID
let title: String
}위와 같은 엔티티가 정의되어 있고, 이를 코어데이터에 저장하는 방법을 구현해보자.
엔티티의 상위 레이어는 UseCase이지만, 새로운 값을 저장하기 위해서는 CoreData(Data Layer)에 접근해야 한다.
UseCase가 CoreData 관련 객체를 직접 소유하면 안되나? 싶을 수 있지만, 이는 의존성 규칙을 위반하는 행위이기 때문에 절대 있을 수 없다.
만약 UseCase에 CoreData 코드가 포함된다면 나중에 데이터베이스를 CoreData가 아닌 Realm, SQLite 또는 서버 API로 변경하려고 한다면 가장 중요한 비즈니스 로직(UseCase)를 통째로 수정해야 한다. 이는 클린 아키텍처의 목표인 유지보수 용이성을 완전히 잃게 되는 행위이다.
또, UseCase를 테스트할 때마다 CoreData를 설정하고 초기화해야 하므로, 테스트가 느려지고 복잡해지는 문제가 발생한다.
때문에 여기서 UseCase가 바깥쪽 레이어인 Data Layer(CoreData)와 소통하기 위해 protocol을 활용한다.
// Repository
protocol ExampleRepository {
func saveItem(item: ExapleEntity) -> Completable
}
// Data Layer: CoreData 구현은 오직 여기서만 일어남
final class ExampleRepositoryImpl: ExampleRepository {
func saveItem(item: ExapleEntity) -> Completable {
// CoreData의 NSManagedObject 생성 및 Context 저장 로직
}
}위 프로토콜을 사용하면 UseCase는 아이템을 저장하게 되는 데이터베이스가 CoreData인지 Realm인지 모른다.
즉, UseCase는 데이터 저장소가 무엇인지 신경 쓸 필요 없이 오직 비즈니스 로직만을 처리하면 되는 것이다.
// UseCase
final class ExampleUseCase {
private let repository: ExampleRepository // protocol에만 의존
func saveNewItem(title: String) -> Completable {
guard title.count > 0 else { return .error(ValidationError.emptyTitle) }
let id = UUID()
let entity = ExampleEntity(id: id, title: title)
// 데이터 저장 로직은 Repository에게 위임
return repository.saveItem(item: entity)
}
}이렇게 하면 UseCase는 Data Layer에 직접적으로 참조하지 않고도 데이터를 저장할 수 있다.
UseCase 객체를 정의할 때 Repository 프로토콜을 채택하는 객체를 정의하여 넘겨주면 의존성 역전 원칙을 통해 Data Layer에 직접 접근하지 않고도 데이터를 저장할 수 있기 때문이다.
📌 결론
클린 아키텍처... 오늘 제대로 공부해서 개념은 거의 이해를 마친 것 같다.
다만 아직 실제로 사용해본 적은 없기 때문에, 실제로 써보면서 시행착오를 겪어야 완전히 내 것으로 만들 수 있을 것 같다.
이번 프로젝트를 통해 클린 아키텍처를 완전히 정복할 수 있기를 바라고 있다.
- P.S
클린 아키텍처는 특히 폴더를 나누는게 너무 힘들어 보인다...
어떤 파일이 어떤 폴더에 들어가야할지 생각하는게 헷갈린다.
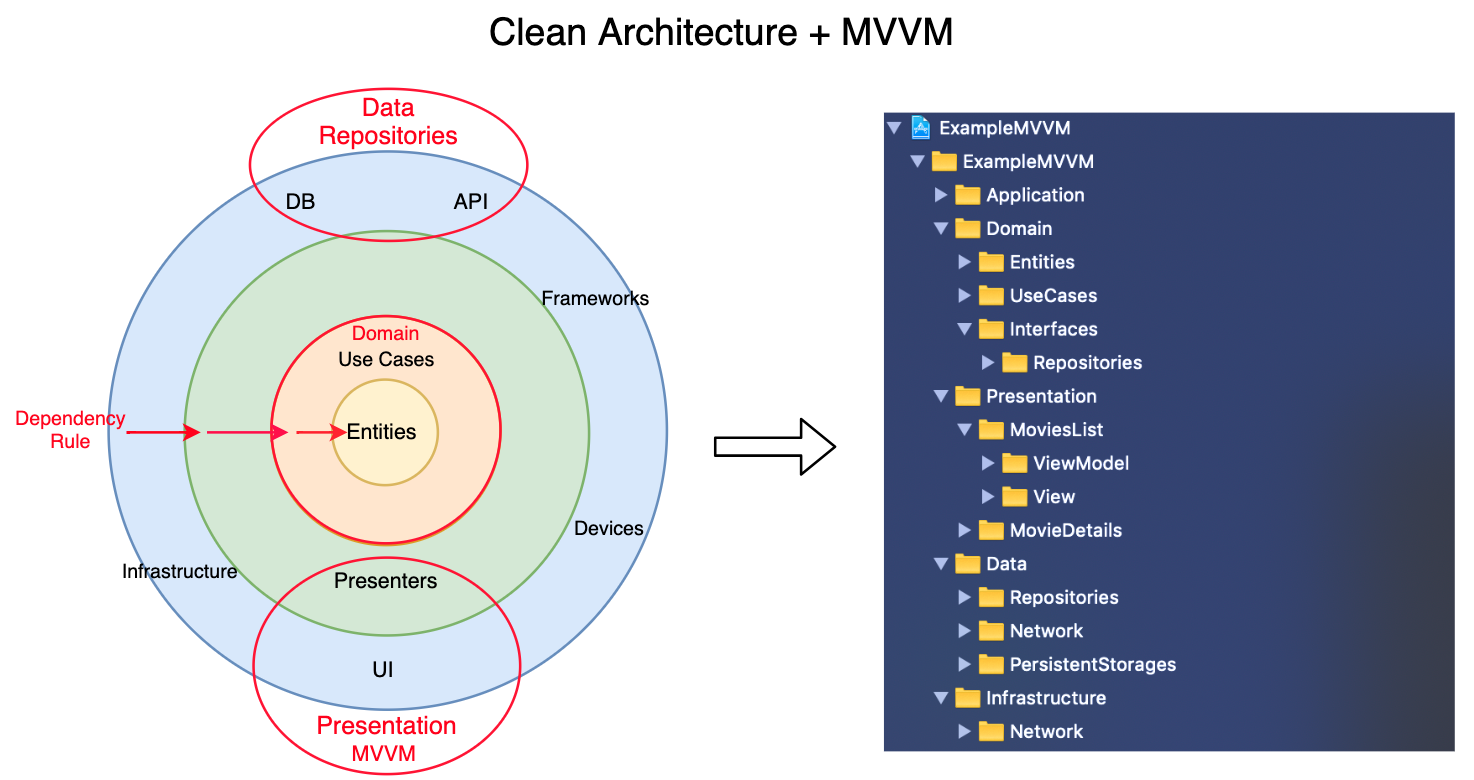
사진 출처: https://github.com/kudoleh/iOS-Clean-Architecture-MVVM
