SQL
1.[SQL]database & table 이해하기
table, index, 저장된 procedure 등 몇몇 구성물의 모음column과 row로 이루어진 이차원 구조database 안에 포함되는 개념
2.[SQL]where 문 활용하기(AND, OR, BETWEEN, IN, LIKE)
where문을 어떻게 활용할 수 있을지 알아봅시다.
3.[SQL]group by 활용하기
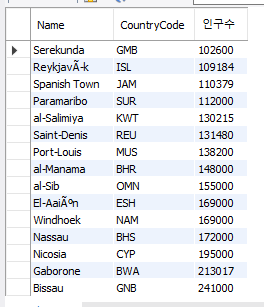
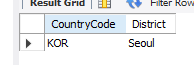
국가코드에 따른 인구의 최댓값, 그리고 해당 도시 이름을출력하되, 칼럼명을 '인구수'로 바꾸고 십만명 이상인 곳만 추출하고 오름차순으로 정리하고 15개 행만 출력
4.[SQL]문자열(string) 데이터 다루기, 간단 수식 연산
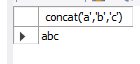
문자나 숫자를 디테일하게 다뤄 봅시다.없으면 0인덱스를 1부터 계산select format(100000000.123, 2); select floor(5.5), ceil(5.5), round(5.5);select sqrt(9), pow(2,2), exp(2), log(e
5.[SQL]날짜 데이터 다루기
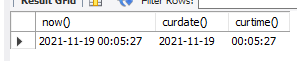
오늘 11월 19일 00시를 지나고 있네요. 날짜 실습을 진행해 봅시다.각각 현재 시간과 날짜, 날짜, 시간 반환달과 날짜의 이름을 출력주/달/년에서 몇번째 날?포맷에 맞게 출력!
6.[SQL]where, group by 실습1

insert into student_info values('20001001', '김유신', '남', '811007', 3000000, '마포', '011-617-1290')insert into student_info values('20001001', '김유신', '남'
7.[SQL] 키(key)와 무결성(integrity)
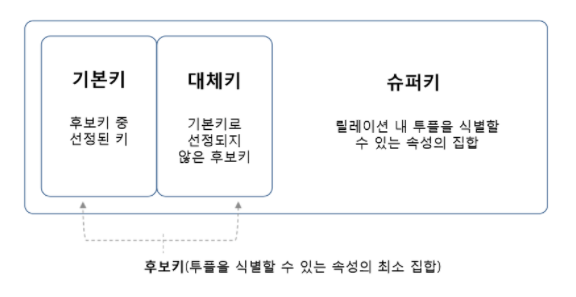
특정 튜플을 식별할 때 사용하는 속성 혹은 속성의 집합식별자이므로 튜플값마다 고유한 속성을 지녀야 함릴레이션 간 관계를 정의하는 데에도 이용됨무결성 : 데이터베이스에 저장된 데이터의 일관성과 정확성을 지키는 것출처: https://mangkyu.tistory.
8.[SQL]GROUP BY(열 2개, 열 3개, null값 처리와 having 활용)
database에 haksa_db 를 추가하고, dump.sql 에 해당하는 파일을 import한 후 실습 진행dump.sql 다운로드(우클릭 후 다른 이름으로 링크 저장)student 테이블에 있는 학생의 학년(grade)별 그룹과 인원을 출력하고 학년(grade)을
9.[SQL]JOIN 명령어 및 실습1(CROSS JOIN, EQUAL JOIN)
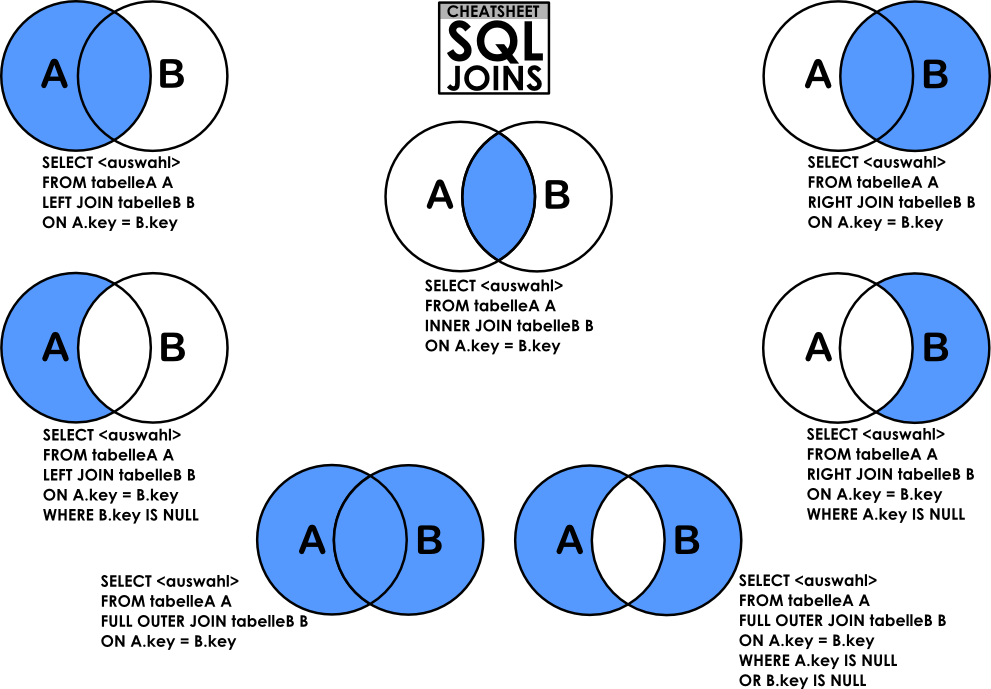
지난 groupby 실습에서 사용된 haksa_db 데이터베이스를 이용해서 실습이 진행됩니다.두 테이블 연결 또는 결합하여 데이터 출력일반적인 경우 PRIMARY KEY(PK) 나 FOREIGN KEY(FK) 값의 연관에 의해 JOIN이 성립https://op
10.[SQL]입양 시각 구하기2 (프로그래머스)
문제 풀기서브쿼리를 활용하는 문제시간별 집계는 자주 쓰일 듯 하니 알아두자.
11.[SQL]Hackerrank - New Companies
문제 풀기unique한 값을 셀 때는 distinct를 사용하여 countgroup by 할 때, 기준이 되는 두 칼럼이 각각 같은 key 값으로 대응되어도 상관없다. 중요한 것은 count, max 등의 연산이 들어간 칼럼을 제외한 칼럼들(여기서는 company_co
12.[SQL] join할때 on 과 where의 차이
on : join 전에 조건을 필터링 where : join 후에 조건을 필터링inner join 하면 둘다 차이 없음outer join 시 on으로 해야 원하는 결과를 얻을 수 있음(outer table에 null값 포함하여 행들이 다 살아있는 상태)on 명령어로 j
13.[SQL]CASE문과 BST(binary search tree)
데이터 범주화(categorical variable)약어나 코드를 읽기 쉬운 값으로 변경해 줌위의 형식 자체가 칼럼이 됨.(CASE~END)CASE WHEN 문을 활용하여 범주화.if 문 제어하듯, 순서가 결과에 영향을 미칠 수 있으니 주의(Root의 경우 맨 먼저 조
14.[SQL] Contest Leaderboard(hackerrank)
문제 풀기group by 와 서브쿼리 활용.대회에서 유저들이 여러 컨테스트에서 제출한 최고점수의 합계를 출력하는 문제.추가 조건(0이상인 것만 출력)을 걸어주어야 해서 좀 더 어려웠음.group by 를 여러번 해야 한다면 전체 select~ from 절을 하나의 ta
15.[SQL] 리트코드 1174. Immediate Food Delivery II
문제 링크WHERE IN 절에서 서브쿼리를 쓸때는, 칼럼들이 align되어야함. in 서브쿼리에서 customer_id와 order_date를 썼으므로, 앞에도 괄호의 형태로 맞춰줌 (customer_id, order_date)칼럼값별로 이진분류하여 그 비율을 계산할때
16.[SQL] 리트코드 550.Game Play Analysis IV
문제 및 정답 링크처음 접속한 날의 다음 날에도 접속한 유저의 비율을 반환하는 문제. 이틀 연속이 아니라 처음 접속한 날 기준이라는 것이 중요. 헷갈리면 안됨!DATE_SUB, DATE_ADD 함수 용법을 이해하고, 서브쿼리(또는 JOIN으로 풀수도 있을듯)로 첫날(p