Structure
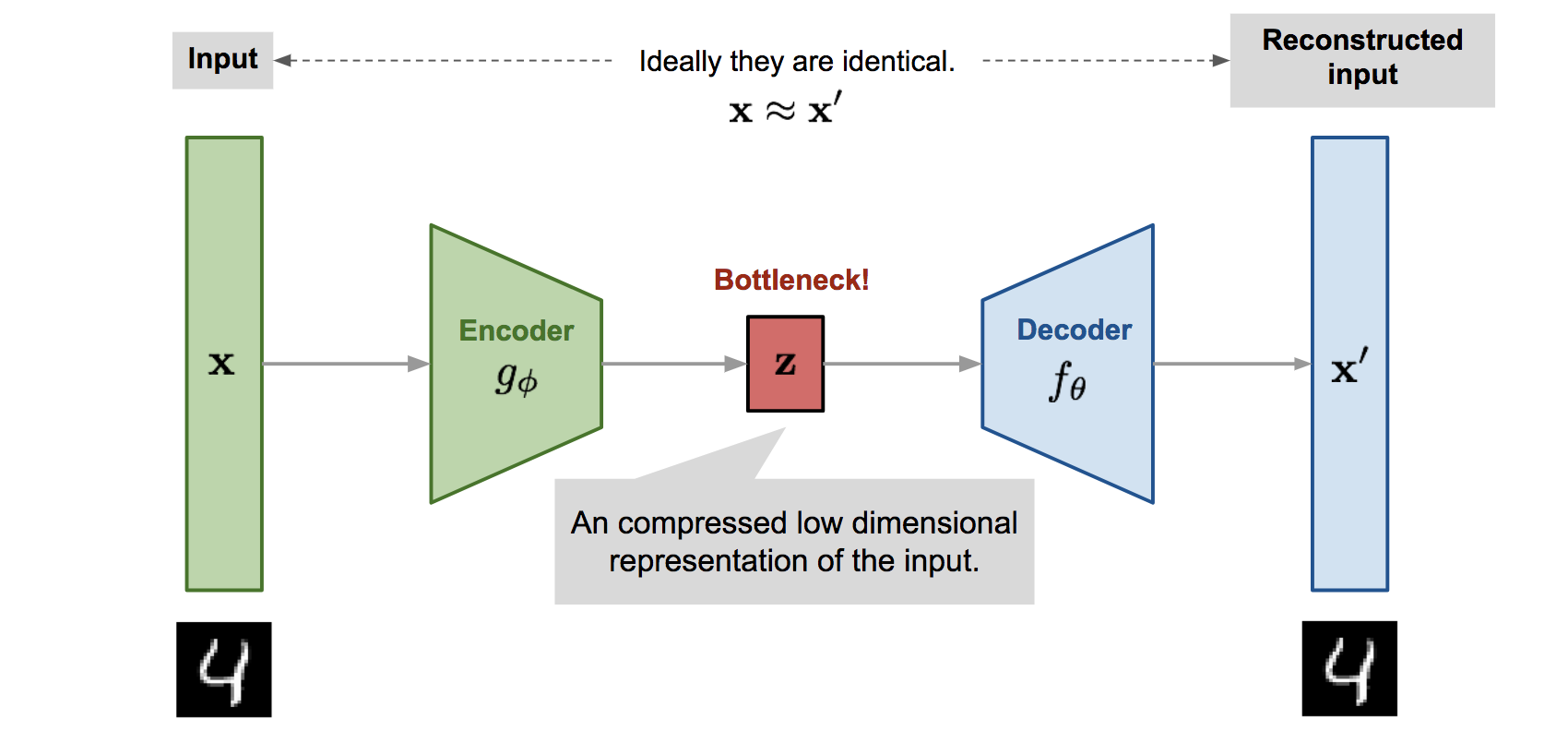
[https://velog.io/@jaehyeong/Autoencoder%EC%99%80-LSTM-Autoencoder]
- self-supervised(unsupervised) learning의 일종
- encoder와 decoder를 거쳐 입력 데이터 기반한 새로운 데이터를 생성함
- representation 벡터의 차원이 너무 높아지면 잘 생성이 안됨. 의미 있는 정보만 남겨서 추출해야 함
encoder
- 고차원 입력 데이터는 저차원 표현 벡터로 압축
decoder
- 주어진 표현 벡터를 원본으로 다시 압축 해제
Latent Space
- 원본 이미지가 저차원 벡터로 압축되는 공간
Representation vector
- 원본 이미지가 압축된 벡터
VAE
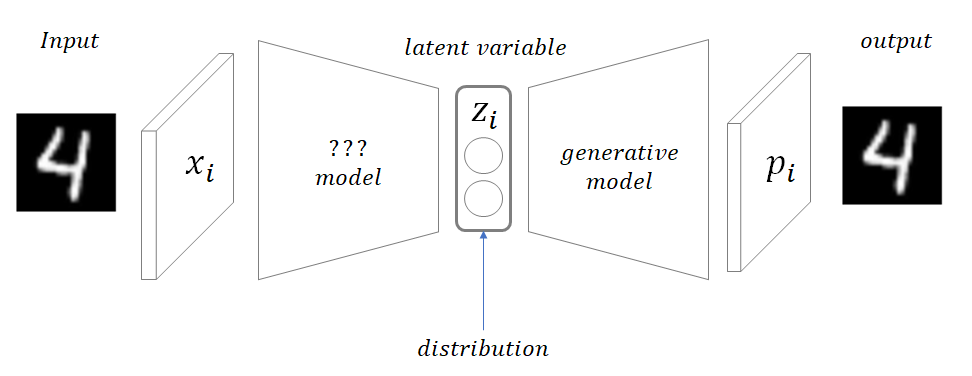
- encoder 구조에서 latent space의 deterministic한 한 점으로 매핑하지 않고, 정규분포의 확률값으로 매핑
- , 의 평균과 분산을 가지는 정규분포러부터 포인트 를 샘플링함
mu = 분포의 평균 벡터이자 가장 확률 높은 예측값
sigma = 해당 값에 대해 확신하는 정도
epsilon = 랜덤한 값
는 로 조작하여 코딩 진행
결과적으로, 인풋이 들어오면 와 로 정의되는 정규분포로부터 z를 샘플링하는 것입니다!!
장점
- 매핑된 예상지점()로부터 근처에 있는 값들이 생성되기 때문에, 2차원 공간에서의 거리 정보가 반영됨(가까울수록 비슷한 데이터 생성)

romantic ai developer