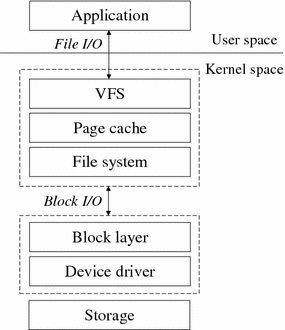
리눅스 스토리지 스택(Linux Storage Stack)은 애플리케이션의 데이터 요청을 물리적 저장 매체에 전달하고 기록하기까지의 과정을 관리하는 정교한 계층적 아키텍처를 기반으로 한다. 이 구조는 모듈성, 유연성, 확장성을 핵심 설계 원칙으로 삼아, 다양한 하드웨어와 소프트웨어 환경에 대한 광범위한 호환성을 제공한다. 스택의 최상단에는 애플리케이션이 사용하는 시스템 호출을 일관된 인터페이스로 변환하는 가상 파일시스템(Virtual Filesystem, VFS)이 위치한다. 그 아래에는 ext4, XFS와 같은 구체적인 파일시스템 구현체가 존재하며, 이는 다시 블록 디바이스를 관리하고 I/O 요청을 스케줄링하는 블록 계층(Block Layer)과 상호작용한다. 더 나아가, 논리 볼륨 관리자(Logical Volume Manager, LVM)는 물리적 디스크의 제약을 넘어선 유연한 볼륨 구성을 위한 추상화 계층을 제공한다. 최하단에는 물리적 하드웨어를 직접 제어하는 디바이스 드라이버가 위치하여 전체 스택을 완성한다.
 [출처: https://link.springer.com/article/10.1007/s10586-017-0776-9]
[출처: https://link.springer.com/article/10.1007/s10586-017-0776-9]
이러한 계층적 설계의 본질은 추상화에 있다. 각 계층은 상위 계층에 표준화된 인터페이스를 제공하면서 하위 계층의 복잡성을 은닉한다. 예를 들어, VFS는 ext4와 XFS의 구현 차이를 추상화하여 애플리케이션이 동일한 open(), read(), write() 시스템 호출을 사용하게 하며, 블록 계층은 다양한 종류의 디스크(HDD, SSD, RAID Array)를 일관된 블록 디바이스로 추상화한다. LVM은 이 추상화를 한 단계 더 발전시켜, 논리적 파티션을 물리적 디스크의 위치와 크기로부터 분리시킨다. 이처럼 각 계층에서 일관되게 적용된 추상화 원칙은 리눅스 스토리지가 NVMe와 같은 새로운 하드웨어나 btrfs와 같은 새로운 파일시스템을 기존 스택의 수정 없이 모듈 형태로 쉽게 통합할 수 있게 하는 근간이 된다.
물리적 저장 장치와 파티셔닝
디스크 구조 및 인터페이스
리눅스 시스템에서 저장 장치는 고정된 크기의 블록(block) 단위로 데이터를 읽고 쓰는 블록 디바이스(block device)로 인식된다. 이 장치들이 시스템과 통신하는 방식은 인터페이스와 프로토콜에 의해 결정되며, 이는 전체 스토리지 성능에 지대한 영향을 미친다.
SATA (Serial ATA) 인터페이스는 AHCI(Advanced Host Controller Interface) 프로토콜을 사용하여 통신한다. 이는 전통적인 하드 디스크 드라이브(HDD) 시대에 설계된 기술로, 단일 명령 큐(command queue)를 통해 한 번에 최대 32개의 명령을 처리할 수 있다. SATA III 표준의 최대 전송 속도는 약 600 MB/s로 제한된다. 이러한 구조는 기계적으로 헤드를 움직여 데이터를 찾는 HDD의 높은 지연 시간(latency) 환경에서는 충분했지만, 다수의 플래시 메모리 칩에 병렬로 접근할 수 있는 솔리드 스테이트 드라이브(SSD)의 잠재력을 완전히 활용하기에는 역부족이다. SSD를 SATA 인터페이스에 연결하면, SSD의 빠른 응답 속도와 병렬 처리 능력에도 불구하고 프로토콜의 순차적인 명령 처리 방식이 병목으로 작용하게 된다.
NVMe (Non-Volatile Memory Express) 인터페이스는 이러한 병목 현상을 해결하기 위해 SSD와 플래시 메모리 기술에 맞춰 처음부터 설계된 최신 프로토콜이다. NVMe는 CPU와 직접적으로 연결되는 고대역폭의 PCIe(Peripheral Component Interconnect Express) 버스를 사용함으로써 데이터 경로를 단축하고 지연 시간을 극적으로 감소시킨다. 가장 큰 아키텍처적 차이점은 최대 65,536개의 병렬 명령 큐를 지원하며, 각 큐는 65,536개의 명령을 담을 수 있다는 점이다. 이 구조는 다중 코어 CPU가 여러 스레드를 통해 스토리지에 동시 다발적으로 I/O 요청을 보낼 때, 각 요청이 독립적인 큐에서 병렬로 처리될 수 있게 한다. 결과적으로 NVMe는 SATA 인터페이스 대비 월등히 높은 IOPS(Input/Output Operations Per Second)와 처리량을 제공하며, PCIe 세대가 발전함에 따라 그 성능은 계속해서 향상된다. 이처럼 SATA에서 NVMe로의 전환은 단순한 속도 향상을 넘어, 스토리지 매체의 특성 변화(기계식에서 반도체로)에 따라 통신 프로토콜 아키텍처가 필연적으로 진화한 결과물이라 할 수 있다.
파티션 테이블: MBR과 GPT
파티션 테이블은 디스크의 논리적인 분할 구조를 정의하는 핵심 메타데이터이다. 현재 주로 사용되는 방식은 MBR과 GPT 두 가지이다.
 [출처: https://www.easeus.co.kr/partition-manager-software/convert-mbr-to-gpt-using-cmd.html]
[출처: https://www.easeus.co.kr/partition-manager-software/convert-mbr-to-gpt-using-cmd.html]
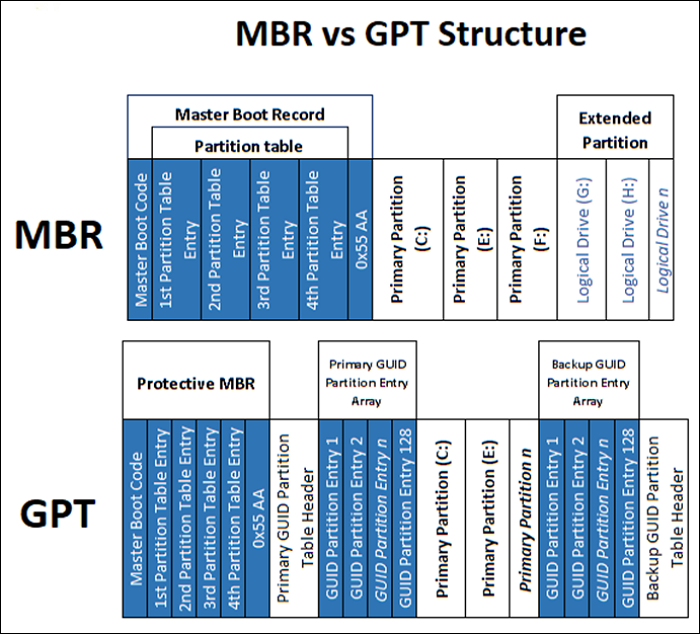
MBR (Master Boot Record)은 1983년에 도입된 전통적인 파티셔닝 방식으로, 디스크의 가장 첫 번째 섹터(512 바이트)에 위치한다. 이 작은 공간 안에 부팅에 필요한 부트 로더 코드, 최대 4개의 주 파티션(primary partition) 정보를 담는 파티션 테이블, 그리고 섹터의 유효성을 나타내는 시그니처(55 AA)가 모두 포함된다. 4개 이상의 파티션이 필요한 경우, 4개의 주 파티션 중 하나를 확장 파티션(extended partition)으로 지정하고 그 안에 여러 개의 논리 파티션(logical partition)을 생성해야 하는 구조적 복잡성이 있다. 또한, MBR은 32비트 주소 체계를 사용하므로 최대 2 TB 크기의 디스크까지만 인식할 수 있다는 명확한 한계를 가진다.
GPT (GUID Partition Table)는 MBR의 한계를 극복하기 위해 UEFI(Unified Extensible Firmware Interface) 표준의 일부로 개발된 현대적인 파티셔닝 방식이다. GPT의 구조는 데이터 무결성과 복원력에 중점을 두고 설계되었다.
-
Protective MBR (LBA 0): 디스크의 첫 번째 섹터에는 GPT를 인식하지 못하는 레거시 시스템과의 호환성을 위해 보호용 MBR이 존재한다. 이 MBR의 파티션 테이블에는 디스크 전체를 차지하는 단일 파티션이 EE 타입으로 기록되어 있어, 구형 유틸리티가 디스크를 비어있는 것으로 오인하고 데이터를 덮어쓰는 것을 방지한다.
-
GPT 헤더 (Primary & Backup): 디스크의 시작(LBA 1)과 끝에 각각 주 헤더와 백업 헤더가 위치한다. 헤더에는 파티션 엔트리의 위치와 개수, 디스크의 고유 식별자(GUID), 그리고 헤더 자체의 무결성을 검증하기 위한 CRC32 체크섬 값이 포함된다. 주 헤더가 손상될 경우, 시스템은 디스크 끝에 있는 백업 헤더를 사용하여 파티션 정보를 복구할 수 있다.
-
파티션 엔트리 배열 (Partition Entries): 각 파티션은 128바이트 크기의 엔트리에 의해 정의되며, 파티션 타입 GUID, 고유 파티션 GUID, 시작과 끝 LBA 주소, 속성 플래그, 그리고 UTF-16으로 인코딩된 파티션 이름 등의 상세 정보를 포함한다. 기본적으로 128개의 파티션을 생성할 수 있어 MBR의 4개 제한을 크게 상회한다.
MBR에서 GPT로의 전환은 단순히 더 큰 디스크를 지원하기 위한 변화를 넘어선다. MBR은 모든 중요 정보를 단일 섹터에 저장하여 손상에 매우 취약한 단일 장애점(single point of failure) 구조를 가진다. 반면, GPT는 파티션 테이블 전체를 디스크의 시작과 끝에 이중으로 저장하고, CRC32 체크섬을 통해 데이터의 무결성을 스스로 검증하는 메커니즘을 내장하고 있다. 이러한 구조적 견고함은 UEFI의 보안 부팅(Secure Boot)과 같은 현대적인 보안 기능이 신뢰할 수 있는 기반을 제공하며, 시스템 전반의 안정성과 데이터 복원력을 근본적으로 향상시킨다.
| 기능 (Feature) | MBR (Master Boot Record) | GPT (GUID Partition Table) |
|---|---|---|
| 최대 디스크 크기 | 2 TB | 9.4 ZB (Zettabyte) |
| 파티션 제한 | 4개의 주 파티션 또는 3개 주 + 1개 확장 파티션 | 128개 파티션 (운영체제 기본값) |
| 데이터 무결성 및 복구 | 단일 부트 섹터에 모든 정보 저장, 내장된 복구 메커니즘 없음 | 주/백업 헤더 및 파티션 테이블, CRC32 체크섬을 통한 무결성 검증 및 복구 지원 |
| 펌웨어 호환성 | Legacy BIOS | UEFI |
| 부트 정보 위치 | 디스크 첫 섹터에 부트 로더와 파티션 테이블 통합 | 별도의 EFI 시스템 파티션(ESP)에 부트 로더 저장 |
파티셔닝 도구 활용
리눅스에서는 디스크 파티션 테이블을 관리하기 위한 다양한 커맨드라인 유틸리티를 제공한다.
-
fdisk: MBR 파티션 테이블을 관리하는 데 사용되는 전통적인 대화형 도구이다. fdisk /dev/sda와 같이 장치명을 인자로 실행하면 대화형 모드로 진입한다. 이 모드에서 p (현재 파티션 테이블 출력), n (새 파티션 생성), d (파티션 삭제), t (파티션 시스템 ID 변경), w (변경 사항 저장 및 종료) 등의 단일 문자 명령어를 사용하여 파티션을 조작할 수 있다. 변경 사항은 w 명령을 실행하기 전까지 디스크에 적용되지 않는다. -
gdisk: GPT 디스크를 위해 설계된 fdisk의 현대적인 대안이다. fdisk와 매우 유사한 사용자 인터페이스를 제공하여 기존 fdisk 사용자가 쉽게 적응할 수 있다. gdisk /dev/sda로 실행하며, p, n, d, t, w 등 동일한 명령어를 사용한다. gdisk의 주요 장점은 MBR로 포맷된 디스크를 데이터 손실 없이 GPT로 변환하는 기능을 포함하고 있다는 점이다. -
parted: MBR과 GPT 파티션 테이블을 모두 지원하는 강력하고 유연한 도구이다. 대화형 모드뿐만 아니라, 스크립트에서 활용할 수 있는 비대화형 모드도 지원하여 자동화에 유리하다. parted /dev/sdb로 대화형 모드를 시작하며, mklabel gpt (디스크 레이블을 GPT로 설정), mkpart (파티션 생성), print (파티션 테이블 출력), rm (파티션 삭제) 등의 명령어를 사용한다. fdisk나 gdisk와 가장 큰 차이점은 parted의 대화형 모드에서 실행된 명령어는 즉시 디스크에 적용된다는 점이므로 사용에 각별한 주의가 필요하다.
파일시스템의 이해
파일시스템은 디스크 파티션 위에 생성되어, 데이터를 파일과 디렉터리라는 계층적 구조로 구성하고 관리하는 역할을 수행한다. 사용자와 애플리케이션은 파일시스템이 제공하는 추상화를 통해 물리적 블록 주소를 직접 다루지 않고도 데이터에 접근할 수 있다.
파일시스템의 내부 구조
리눅스 파일시스템은 데이터를 효율적으로 관리하기 위해 여러 핵심적인 자료 구조를 사용한다.
 [출처: https://www.easeus.co.kr/partition-manager-software/ext2-ext3-ext4-file-system-format-and-difference.html]
[출처: https://www.easeus.co.kr/partition-manager-software/ext2-ext3-ext4-file-system-format-and-difference.html]
-
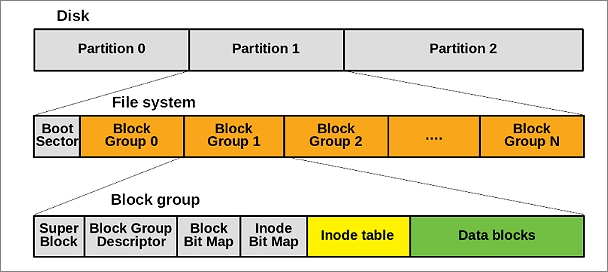
슈퍼블록 (Superblock): 파일시스템의 '마스터 정보'를 담고 있는 구조체이다. 여기에는 파일시스템의 전체 크기, 사용 가능한 블록 및 아이노드의 수, 블록 크기, 파일시스템 종류를 식별하는 매직 넘버(magic number), 그리고 파일시스템의 상태(마운트 여부 등)와 같은 전반적인 메타데이터가 기록된다. 시스템이 파일시스템을 마운트할 때 가장 먼저 이 슈퍼블록을 메모리로 읽어 들인다. 슈퍼블록이 손상되면 파일시스템 전체를 인식할 수 없게 되므로, 대부분의 파일시스템은 재해 복구를 위해 여러 개의 백업 슈퍼블록을 디스크 곳곳에 분산하여 저장한다.
-
아이노드 (Inode, Index Node): 파일시스템 내의 모든 파일과 디렉터리는 각각 하나의 아이노드를 가진다. 아이노드는 파일의 실제 데이터와 파일 이름을 제외한 모든 메타데이터를 저장한다. 여기에는 파일의 종류(일반 파일, 디렉터리, 심볼릭 링크 등), 접근 권한, 소유자(UID) 및 그룹(GID), 파일 크기, 생성/수정/접근 시간, 그리고 데이터가 저장된 데이터 블록의 주소를 가리키는 포인터 목록이 포함된다. 아이노드 내의 포인터는 작은 파일의 경우 데이터 블록을 직접 가리키고(Direct Pointers), 파일 크기가 커짐에 따라 포인터의 주소를 담은 블록을 가리키는 간접적인 방식(Single/Double/Triple Indirect Pointers)을 사용하여 매우 큰 파일까지 효율적으로 주소 지정이 가능하다.
-
덴트리 (Dentry, Directory Entry): 파일 이름과 그에 해당하는 아이노드 번호를 연결하는 역할을 하는 메모리 상의 자료 구조이다. 디렉터리는 본질적으로 파일 이름과 아이노드 번호의 매핑 테이블을 내용으로 하는 특수한 파일이다. 사용자가 /home/user/file.txt와 같은 경로로 파일에 접근할 때, 커널은 루트 디렉터리(/)부터 시작하여 각 디렉터리(home, user)를 순차적으로 탐색하며 해당 이름에 매핑된 아이노드 번호를 찾는다. 이 과정의 성능을 높이기 위해, 한 번 조회된 덴트리 정보는 덴트리 캐시(dentry cache)에 저장되어 후속 접근 시 디스크 I/O 없이 빠르게 경로를 해석할 수 있게 한다. 파일 이름이 아이노드와 분리되어 덴트리에 의해 관리되기 때문에, 여러 개의 다른 이름(다른 덴트리)이 동일한 아이노드를 가리키는 '하드 링크(hard link)' 기능이 구현될 수 있다.
-
데이터 블록 (Data Block): 파일의 실제 내용이 저장되는 디스크 상의 물리적인 공간이다. 아이노드에 저장된 포인터들이 바로 이 데이터 블록들을 가리킨다.
저널링과 데이터 일관성
파일 삭제와 같은 단일 논리적 작업은 실제로는 여러 단계의 물리적 쓰기 작업으로 이루어진다. 예를 들어, 파일 삭제는 (1) 디렉터리에서 파일 엔트리 제거, (2) 파일의 아이노드를 '사용 가능' 상태로 변경, (3) 아이노드가 가리키던 데이터 블록들을 '사용 가능' 상태로 변경하는 과정을 포함한다. 만약 이 과정 중간에 시스템 전원이 꺼지거나 장애가 발생하면, 파일시스템은 비일관적인(inconsistent) 상태에 놓일 수 있다. 예를 들어, 아이노드는 해제되었으나 데이터 블록이 해제되지 않으면 해당 공간은 영구적으로 유실된다(storage leak).
저널링(Journaling)은 이러한 문제를 해결하기 위한 기법으로, '미리 쓰기 로깅(Write-Ahead Logging)' 원칙을 따른다.
-
트랜잭션 시작: 파일시스템은 디스크의 메타데이터를 변경하기 전에, 수행할 작업의 내용을 '저널(journal)'이라는 별도의 로그 영역에 먼저 기록한다. 이 기록 단위를 트랜잭션(transaction)이라고 한다.
-
저널 커밋: 관련된 모든 변경 내용이 저널에 안전하게 기록되면, 저널에 '커밋(commit)' 레코드를 남긴다.
-
체크포인트 (실제 쓰기): 저널에 커밋된 내용을 바탕으로 실제 파일시스템의 메타데이터(슈퍼블록, 아이노드 등)를 수정한다.
-
복구 과정: 시스템 장애 후 재부팅 시, 파일시스템 검사 도구(
fsck)는 디스크 전체를 스캔하는 대신 용량이 훨씬 작은 저널 영역만 확인한다. 만약 저널에 커밋된 트랜잭션이 있지만 실제 파일시스템에 반영되지 않았다면, 저널의 내용을 재실행(replay)하여 작업을 완료한다. 커밋되지 않은 불완전한 트랜잭션은 무시하고 폐기한다. 이 과정을 통해 파일시스템을 빠르고 안정적으로 일관된 상태로 복구할 수 있다.
대부분의 현대 파일시스템은 다음과 같은 저널링 모드를 지원한다.
-
journal 모드: 데이터와 메타데이터의 모든 변경 사항을 저널에 기록한다. 가장 높은 수준의 데이터 보호를 제공하지만, 모든 데이터를 두 번씩 써야 하므로 성능 저하가 가장 크다.
-
ordered 모드: 기본값으로 가장 널리 사용된다. 메타데이터 변경 사항만 저널에 기록하되, 관련된 데이터 블록을 디스크에 먼저 기록한 후에 메타데이터 변경을 저널에 커밋한다. 이 순서 보장을 통해 시스템 장애 시에도 파일 데이터가 손상되는 것을 방지하면서 우수한 성능을 제공한다.
-
writeback 모드: 메타데이터 변경 사항만 저널에 기록하며, 데이터와 메타데이터의 쓰기 순서를 보장하지 않는다. 성능은 가장 빠르지만, 장애 발생 시 최근에 수정된 파일의 데이터가 예전 버전으로 남거나 손상될 수 있다.
주요 리눅스 파일시스템: ext4와 XFS
리눅스 환경에서는 다양한 파일시스템이 사용되지만, ext4와 XFS가 가장 대표적이다.
-
ext4 (Fourth Extended Filesystem): 오랜 기간 리눅스의 기본 파일시스템으로 사용되어 온 만큼 매우 안정적이고 성숙도가 높다. 다양한 워크로드에서 준수한 성능을 보이며, 특히 웹 서버나 개발 서버와 같이 작은 파일이 많고 메타데이터 관련 작업(파일 생성, 삭제, 조회 등)이 빈번한 환경에서 강점을 보인다. 대부분의 리눅스 배포판에서 기본적으로 지원하며, 호환성이 뛰어나다.
-
XFS (eXtents File System): 원래 Silicon Graphics(SGI)에서 대규모 컴퓨팅 환경을 위해 개발한 64비트 고성능 저널링 파일시스템이다. 대용량 파일(수 테라바이트 이상) 및 대규모 파일시스템(수백 테라바이트 이상) 관리에 최적화되어 있다. '할당 그룹(Allocation Groups)'이라는 내부 구조를 통해 메타데이터 작업을 병렬로 처리할 수 있어, 다중 코어 CPU 시스템에서 뛰어난 확장성(scalability)을 제공한다. 이러한 특성 때문에 데이터베이스, 미디어 스트리밍, 대용량 백업 서버 등 순차 I/O 성능과 병렬 처리 능력이 중요한 엔터프라이즈 환경에서 선호되며, Red Hat Enterprise Linux(RHEL) 및 그 파생 배포판에서 기본 파일시스템으로 채택되었다.
두 파일시스템의 주요 관리적 차이점 중 하나는 크기 조정 기능이다. ext4 파일시스템은 온라인 상태에서 확장이 가능하며, 오프라인 상태에서는 축소도 가능하다. 반면, XFS는 온라인 확장만 지원하고 파티션 크기 축소는 지원하지 않는다. 이러한 제약은 스토리지 설계 시 LVM과 같은 유연한 볼륨 관리 솔루션의 필요성을 더욱 부각시킨다.
| 항목 (Category) | ext4 | XFS |
|---|---|---|
| 주요 사용 사례 | 범용 웹 서버, 개발 서버, 데스크톱, 작은 파일 위주 환경 | 대용량 데이터베이스, 미디어 스트리밍/편집, 대규모 파일 서버 |
| 최대 파일/볼륨 크기 | 16 TB / 1 EB | 8 EB / 8 EB |
| 성능 특성 | 다수의 작은 파일 처리 및 메타데이터 작업에 우수 | 대용량 파일의 순차 I/O 및 병렬 I/O 처리에 우수 |
| 크기 조정 | 확장 및 축소 모두 가능 | 확장만 가능 (축소 불가) |
| 안정성 및 성숙도 | 매우 높음, 광범위하게 검증됨 | 매우 높음, 엔터프라이즈 환경에서 수십 년간 검증됨 |
파일시스템 생성 및 마운트
-
mkfs명령어: 포맷된 파티션 위에 파일시스템 자료 구조를 생성하는 명령어이다. 실제로는 mkfs.ext4, mkfs.xfs와 같이 파일시스템별로 특화된 유틸리티를 호출하는 프론트엔드 역할을 한다.-
사용 예시 및 주요 옵션:
-
ext4 파일시스템 생성:
sudo mkfs.ext4 /dev/sdb1 -
XFS 파일시스템 생성:
sudo mkfs.xfs /dev/sdb1 -
-L옵션은 파일시스템에 레이블(label)을 지정한다. 예:sudo mkfs.ext4 -L "DATA_PARTITION" /dev/sdb1 -
-i size(XFS) 또는-i bytes-per-inode(ext4) 옵션은 아이노드의 크기나 밀도를 조절한다. 작은 파일이 매우 많은 경우, 아이노드 수를 늘려 공간 부족 문제를 예방할 수 있다. 예:sudo mkfs.ext4 -N 500000 /dev/sdb2
-
-
-
mount명령어와/etc/fstab:mount명령어는 생성된 파일시스템을 리눅스 디렉터리 트리 내의 특정 지점(마운트 포인트)에 연결하는 역할을 한다. 시스템이 부팅될 때마다 파일시스템을 자동으로 마운트하려면/etc/fstab파일에 해당 정보를 등록해야 한다./etc/fstab파일은 한 줄에 하나의 마운트 정보를 기술하며, 각 줄은 6개의 필드로 구성된다 :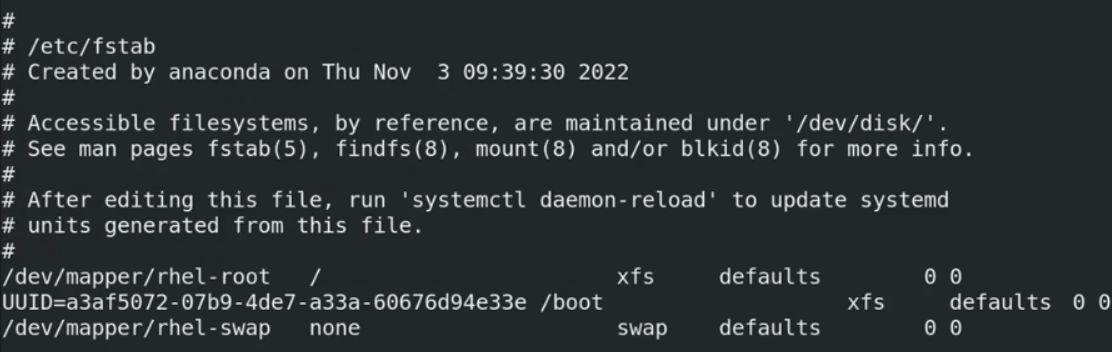
-
<device>: 마운트할 장치. -
<dir>: 마운트 포인트 디렉터리. -
<type>: 파일시스템 종류 (e.g., ext4, xfs). -
<options>: 마운트 옵션 (e.g., defaults, noatime). -
<dump>: dump 유틸리티 사용 여부 (보통 0). -
<fsck>:부팅 시 파일시스템 검사 순서 (루트는 1, 나머지는 2 또는 0).
-
-
UUID 사용의 중요성:
/etc/fstab에서 장치를 지정할 때/dev/sda1과 같은 장치 이름을 사용하는 것은 위험하다. 시스템에 디스크가 추가되거나 제거될 때 이 이름은 변경될 수 있으며, 이는 부팅 실패로 이어질 수 있다. 이를 방지하기 위해 각 파일시스템마다 부여되는 고유 식별자인 UUID(Universally Unique Identifier)를 사용하는 것이 강력히 권장된다. UUID는blkid또는lsblk -f명령어로 확인할 수 있으며, UUID="xxxxxxxx-xxxx-..." 형식으로/etc/fstab에 기재하면 장치 순서가 바뀌어도 항상 올바른 파티션을 정확하게 찾아 마운트할 수 있다. -
주요 마운트 옵션:
-
defaults: rw, suid, dev, exec, auto, nouser, async 옵션을 모두 포함하는 기본 설정이다.
-
noauto: 부팅 시 자동으로 마운트하지 않도록 설정한다.
-
nofail: 해당 장치가 존재하지 않더라도 부팅 과정에서 오류를 발생시키지 않고 계속 진행하도록 한다. 외장 하드나 네트워크 드라이브에 유용하다.
-
noatime: 파일에 접근할 때마다 접근 시간을 기록하는 작업을 생략하여 디스크 I/O를 줄이고 성능을 향상시킨다.
-
논리 볼륨 관리 (Logical Volume Management - LVM)
LVM은 물리적 저장 장치 위에 추상화 계층을 제공하여, 전통적인 파티션 방식의 한계를 극복하고 유연하며 동적인 스토리지 관리를 가능하게 하는 강력한 프레임워크이다.
LVM 아키텍처: PV, VG, LV
LVM은 세 가지 핵심 구성 요소를 통해 계층적 구조를 이룬다.
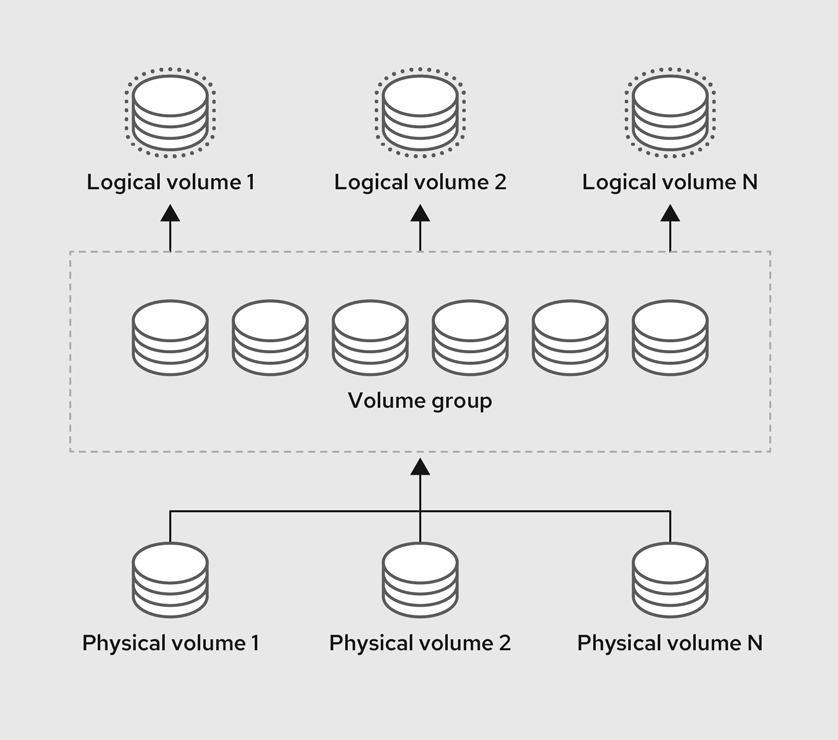 [출처: https://docs.redhat.com/ko/documentation/red_hat_enterprise_linux/9/html-single/configuring_and_managing_logical_volumes/index]
[출처: https://docs.redhat.com/ko/documentation/red_hat_enterprise_linux/9/html-single/configuring_and_managing_logical_volumes/index]
-
물리 볼륨 (PV - Physical Volume): LVM이 사용할 수 있는 기본 저장 단위이다. 이는 하드 디스크 전체가 될 수도 있고,
fdisk나gdisk로 생성된 일반 파티션일 수도 있다.pvcreate /dev/sdb1과 같은 명령어를 통해 특정 파티션이나 디스크를 LVM이 관리할 수 있는 PV로 초기화한다. -
볼륨 그룹 (VG - Volume Group): 하나 이상의 PV들을 하나로 묶어 생성하는 거대한 가상 스토리지 풀(pool)이다.
vgcreate my_vg /dev/sdb1 /dev/sdc1과 같이 여러 PV를 조합하여 하나의 VG를 만들 수 있다. 이를 통해 여러 디스크의 용량을 합쳐 단일의 큰 저장 공간처럼 사용할 수 있다. -
논리 볼륨 (LV - Logical Volume): VG라는 스토리지 풀에서 필요한 만큼의 공간을 할당받아 생성하는 가상 파티션이다.
lvcreate -L 10G -n my_lv my_vg와 같이 VG로부터 특정 크기의 LV를 생성한다. 사용자와 운영체제는 이 LV를/dev/sda1과 같은 일반 블록 디바이스처럼 인식하며, 그 위에 파일시스템을 생성하고 마운트하여 사용한다. -
물리적/논리적 익스텐트 (PE/LE - Physical/Logical Extent): VG는 익스텐트(Extent)라는 고정된 크기(기본 4MB)의 작은 블록들로 나뉘어 관리된다. PV를 구성하는 익스텐트를 PE(Physical Extent)라 하고, LV를 구성하는 익스텐트를 LE(Logical Extent)라 한다. LVM의 핵심은 LE와 PE 간의 매핑 테이블을 관리하는 것이다. 이 매핑 덕분에 LV는 물리적으로 연속되지 않은 PE들로 구성될 수 있으며, 이는 LV의 크기를 동적으로 조절하거나 데이터를 다른 PV로 이동시키는 등의 유연한 작업을 가능하게 하는 기반이 된다.
LVM의 동적 관리: 온라인 볼륨 확장
LVM의 가장 큰 장점 중 하나는 시스템 운영 중단 없이 파일시스템의 용량을 동적으로 확장할 수 있다는 것이다. 이는 전통적인 파티셔닝 방식이 파티션 크기 변경을 위해 시스템 재부팅이나 서비스 중단을 요구하는 것과 대조된다. 온라인 볼륨 확장 절차는 다음과 같다.
-
물리적 스토리지 추가: 시스템에 새로운 하드 디스크나 SSD를 장착하거나, 가상 환경에서 가상 디스크의 크기를 늘린다.
-
PV 생성: 새로 추가된 디스크(예:
/dev/sdd) 또는 파티션(예:/dev/sdd1)을pvcreate명령어를 사용하여 PV로 초기화한다.# pvcreate /dev/sdd1 -
VG 확장:
vgextend명령어를 사용하여 기존 볼륨 그룹(예: my_vg)에 새로운 PV를 추가하여 스토리지 풀의 전체 용량을 늘린다.# vgextend my_vg /dev/sdd1 -
LV 확장:
lvextend명령어를 사용하여 확장하고자 하는 논리 볼륨(예: my_lv)에 VG의 여유 공간을 할당한다. 특정 크기를 추가하거나(-L +50G), VG의 모든 남은 공간을 할당(-l +100%FREE)할 수 있다.# lvextend -l +100%FREE /dev/my_vg/my_lv -
파일시스템 크기 조정: LV의 크기는 확장되었지만, 그 위에서 실행 중인 파일시스템은 아직 이전 크기를 유지하고 있다. 파일시스템이 확장된 공간을 인식하고 사용할 수 있도록 온라인 리사이징을 수행해야 한다. 이 작업은 파일시스템을 마운트 해제할 필요 없이 실시간으로 가능하다.
- ext4 파일시스템의 경우:
resize2fs명령어를 사용한다.
# resize2fs /dev/my_vg/my_lv- XFS 파일시스템의 경우:
xfs_growfs명령어를 사용하며, 장치명이 아닌 마운트 포인트를 인자로 받는다.
# xfs_growfs /data - ext4 파일시스템의 경우:
이처럼 LVM이 제공하는 논리적 추상화와 최신 파일시스템의 온라인 리사이징 기능의 결합은, 스토리지 용량 관리를 위한 서비스 중단을 최소화하거나 완전히 제거할 수 있게 한다. 이는 24/7 운영이 필수적인 현대의 클라우드 및 DevOps 환경에서 요구하는 인프라의 민첩성과 고가용성을 지원하는 핵심 기술이다. 경직된 사전 용량 계획에서 벗어나 필요에 따라 유연하게 확장하는 'grow-as-you-go' 모델을 가능하게 한다.
LVM 고급 기능
스냅샷 (Snapshot)
LVM 스냅샷은 특정 시점(Point-in-Time)의 논리 볼륨 상태를 보존하는 기능이다. 이는 전체 데이터를 물리적으로 복사하는 것이 아니라, Copy-on-Write (CoW)라는 효율적인 메커니즘을 사용한다.
-
Copy-on-Write (CoW) 동작 원리:
-
원본 LV에 대한 스냅샷 LV를 생성하면, 초기에는 스냅샷이 별도의 데이터 공간을 차지하지 않는다. 대신 원본 LV의 데이터 블록을 그대로 가리키는 메타데이터만 생성된다.
-
이후 원본 LV의 특정 데이터 블록에 변경(Write)이 발생하려고 하면, LVM은 변경이 일어나기 직전의 '원본' 데이터 블록을 스냅샷을 위해 할당된 공간으로 먼저 복사(Copy)한다.
-
원본 데이터가 스냅샷 공간으로 백업된 후에야 원본 LV의 해당 블록에 새로운 데이터가 기록된다.
-
스냅샷을 통해 데이터에 접근하면, 변경되지 않은 블록은 원본 LV에서 직접 읽어오고, 변경된 블록은 스냅샷 공간에 백업된 '과거 시점'의 데이터를 읽어온다. 이를 통해 스냅샷은 생성 시점의 일관된 데이터 뷰를 제공할 수 있다.
-
씬 프로비저닝 (Thin Provisioning)
씬 프로비저닝은 스토리지 자원을 극도로 효율적으로 사용하기 위한 기술이다. 전통적인 방식(Thick Provisioning)에서는 LV를 생성할 때 요청한 크기만큼의 물리적 공간이 볼륨 그룹에서 즉시 할당되고 예약된다. 하지만 씬 프로비저닝은 LV를 생성할 때는 논리적인 공간만 할당하고, 실제 데이터가 기록될 때 필요한 만큼만 스토리지 풀에서 물리적 공간을 동적으로 할당한다.
-
구성 요소 및 동작:
-
먼저
lvcreate명령어로 씬 풀(Thin Pool)이라는 특별한 LV를 생성한다. 이 씬 풀이 실제 물리적 공간을 보유하는 스토리지 풀 역할을 한다. -
이후 생성된 씬 풀 내에서 하나 이상의 씬 볼륨(Thin Volume)을 생성한다. 씬 볼륨은 생성 시점에는 거의 공간을 차지하지 않는다.
-
사용자가 씬 볼륨에 데이터를 쓰면, 씬 풀이 보유한 여유 공간에서 필요한 만큼의 블록이 동적으로 씬 볼륨에 할당된다.
-
-
장점: 이 방식을 사용하면 씬 풀의 실제 물리적 크기보다 더 큰 총량의 논리적 볼륨을 생성하는 오버프로비저닝(Over-provisioning)이 가능하다. 예를 들어, 100 GB의 씬 풀 위에 각각 50 GB 크기의 씬 볼륨 4개(총 200 GB)를 생성할 수 있다. 각 볼륨이 실제로 사용하는 공간의 합이 100 GB를 넘지 않는 한 정상적으로 작동한다. 이는 가상 머신이나 컨테이너 환경에서 각 사용자에게 충분한 논리적 공간을 제공하면서도 실제 물리적 스토리지 비용을 절감하는 데 매우 유용하다. 또한, 씬 볼륨에 대한 스냅샷인 씬 스냅샷은 별도의 스냅샷 공간을 미리 할당할 필요 없이 씬 풀 내의 공간을 공유하므로 매우 빠르고 효율적으로 생성할 수 있다.
시스템 유지보수 및 복구
파일시스템 무결성 검사 및 복구
fsck(File System Consistency checK)는 예기치 않은 시스템 종료나 하드웨어 오류 등으로 인해 발생할 수 있는 파일시스템의 비일관성을 진단하고 복구하는 필수적인 유틸리티이다. fsck는 실제로는 파일시스템 유형에 따라 fsck.ext4, fsck.xfs 등 특정 도구를 호출하는 래퍼(wrapper) 프로그램이다. 중요한 점은 데이터 손상을 방지하기 위해 반드시 마운트되지 않은(unmounted) 파일시스템에 대해서만 실행해야 한다는 것이다.
특히 파일시스템의 핵심 메타데이터인 슈퍼블록이 손상되면 파일시스템을 마운트할 수 없게 된다. ext4와 같은 파일시스템은 이러한 상황에 대비하여 여러 개의 백업 슈퍼블록을 디스크에 저장해두며, 이를 이용해 복구를 시도할 수 있다.
ext4 슈퍼블록 손상 시 복구 절차는 다음과 같다:
-
대상 파티션 확인: 먼저
sudo fdisk -l명령을 실행하여 복구할 대상 파티션의 장치 이름(예: /dev/sdb1)을 정확히 확인한다. -
백업 슈퍼블록 위치 확인:
mke2fs또는dumpe2fs명령어를 사용하여 백업 슈퍼블록의 위치(블록 번호)를 조회한다.mke2fs의-n옵션은 파일시스템을 실제로 생성하지 않고 정보만 출력한다.# mke2fs -n /dev/sdb1 ... Superblock backups stored on blocks: 32768, 98304, 163840, 229376, 294912, 819200, 884736또는
dumpe2fs를 사용할 수도 있다.# dumpe2fs /dev/sdb1 | grep -i superblock -
백업 슈퍼블록을 이용한 복구:
e2fsck(또는fsck.ext4) 명령어에-b옵션으로 위에서 확인한 백업 슈퍼블록 중 하나의 블록 번호를 지정하여 복구를 시도한다.-y옵션을 추가하면 모든 복구 질문에 자동으로 'yes'로 응답하여 상호작용 없이 진행할 수 있다.# e2fsck -b 32768 -y /dev/sdb1 -
확인 및 재부팅: 복구가 성공적으로 완료되면, 시스템을 재부팅하거나
mount명령어를 통해 파일시스템이 정상적으로 마운트되는지 확인한다. 만약 첫 번째 백업 슈퍼블록으로 복구가 실패하면, 목록에 있는 다른 백업 슈퍼블록을 사용하여 3단계를 다시 시도할 수 있다.
