대부분의 사용자, 심지어 많은 개발자에게 중앙 처리 장치(CPU)는 일종의 '블랙박스'와 같다. 우리는 명령어를 입력하고 결과를 받지만, 그 내부에서 수십억 개의 트랜지스터가 어떤 방식으로 작업을 처리하는지 직접 목격하기는 어렵다. 그러나 이 블랙박스 내부를 들여다볼 수 있는 강력하고 정교한 도구가 존재하는데, 바로 하드웨어 성능 카운터(Hardware Performance Counter, HPC)이다.
HPC는 CPU의 가장 깊숙한 곳, 즉 마이크로아키텍처 수준에서 일어나는 활동을 측정하고 기록하기 위해 CPU 칩 자체에 내장된 특수한 장치이다. 비행기의 비행 데이터 기록 장치가 항공기의 모든 중요한 운항 정보를 기록하듯, HPC는 CPU의 실행 동작에 대한 핵심적인 데이터를 실시간으로 기록하는 CPU의 고유한 '계기판' 또는 '텔레메트리 시스템'이라 할 수 있다.
본래 HPC는 소프트웨어의 성능 병목 현상을 찾아내고 최적화하려는 개발자들을 위한 도구였다. 하지만 최신 CPU의 성능 최적화 기술이 역설적으로 새로운 보안 취약점의 문을 열면서, HPC는 이제 성능 분석 도구를 넘어 정교한 하드웨어 수준의 사이버 공격을 탐지하는 최전선의 보안 센서로서 중대한 역할을 수행하게 되었다.
하드웨어 성능 카운터(HPC)의 기본 원리
HPC란 무엇인가?
하드웨어 성능 카운터(HPC)는 현대 마이크로프로세서에 내장된 특수 목적 레지스터(special-purpose registers) 집합이다. 이 레지스터들은 CPU 내부에서 발생하는 다양한 하드웨어 관련 활동, 즉 '이벤트(event)'의 발생 횟수를 계산하는 역할을 한다. 이러한 기능은 성능 모니터링 유닛(Performance Monitoring Unit, PMU)이라 불리는 더 큰 하위 시스템의 일부로 작동하며, 소프트웨어 계층이 아닌 하드웨어 자체에서 직접 카운팅이 이루어지기 때문에 거의 제로에 가까운 오버헤드로 정밀한 측정이 가능하다.
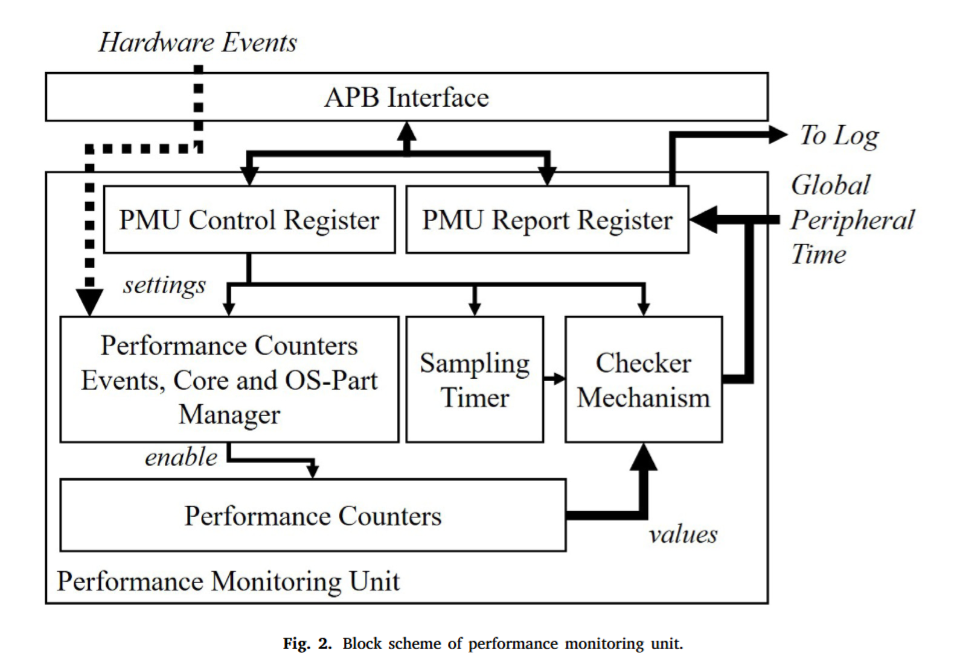 [출처: https://www.sciencedirect.com/science/article/pii/S014193312400098X]
[출처: https://www.sciencedirect.com/science/article/pii/S014193312400098X]
HPC가 측정할 수 있는 것들: 마이크로아키텍처 이벤트
HPC가 추상적인 개념에서 벗어나 구체적으로 이해되려면, 그것이 무엇을 셀 수 있는지를 아는 것이 중요하다. HPC가 모니터링할 수 있는 이벤트는 CPU의 마이크로아키텍처와 직접적으로 관련이 있으며, 주요 범주는 다음과 같다.
-
코어 실행 이벤트:
-
CPU_CYCLES: CPU가 소비한 총 클럭 사이클 수이다. -
INSTRUCTIONS_RETIRED: 성공적으로 실행이 완료된 명령어의 총 수이다. -
이 두 지표의 비율()은 CPU 효율성을 측정하는 핵심 척도이다.
-
-
메모리 하위 시스템 이벤트:
-
L1D_CACHE_REFILL: L1 데이터 캐시에서 원하는 데이터를 찾지 못해 상위 캐시나 메모리에서 데이터를 가져온 횟수(캐시 미스)이다. -
LLC_MISSES(또는L3_MISS): 마지막 레벨 캐시(Last-Level Cache)에서 발생한 캐시 미스 횟수이다. 이 수치가 높으면 DRAM 접근이 빈번했음을 의미하며, 이는 심각한 성능 저하의 원인이 된다. -
MEM_ACCESS: 캐시 적중 여부와 관계없이 발생한 총 메모리 접근(읽기 및 쓰기) 횟수이다.
-
-
분기 예측 이벤트:
-
BR_MISP_PRED: 분기 예측기가 프로그램의 다음 실행 경로를 잘못 예측한 횟수이다. 예측이 틀리면 파이프라인을 비우고 올바른 경로의 명령어를 다시 가져와야 하므로 큰 성능 손실을 유발한다. -
BR_PRED: 분기 예측기가 예측을 시도한 총 분기 명령어 수이다.
-
-
TLB(Translation Lookaside Buffer) 이벤트:
-
L1D_TLB_REFILL: L1 데이터 TLB에서 가상 주소에 해당하는 물리 주소를 찾지 못해 발생한 미스 횟수이다. -
ITLB_FLUSH: 특정 작업(예: 컨텍스트 스위칭)으로 인해 명령어 TLB의 내용이 무효화되고 비워진 횟수이다.
-
본래의 목적: 성능 공학
HPC는 처음부터 보안을 위해 설계된 기능이 아니었다. 그 주된 목적은 소프트웨어 개발자와 시스템 엔지니어가 코드의 성능을 극단까지 분석하고 튜닝할 수 있도록 돕는 것이었다. 개발자는 HPC 데이터를 통해 "왜 이 코드가 느린가?"라는 질문에 대한 답을 찾는다. 예를 들어, 특정 함수를 실행할 때 L1D_CACHE_REFILL 이벤트 수가 비정상적으로 높게 측정된다면, 이는 해당 함수의 데이터 지역성(data locality)이 나빠 캐시를 효율적으로 사용하지 못하고 있다는 명백한 증거가 된다. 개발자는 이 정보를 바탕으로 데이터 구조를 변경하거나 접근 패턴을 수정하여 성능을 개선할 수 있다.
다만, HPC에는 물리적인 한계도 존재한다. CPU에 내장된 카운터 레지스터의 수는 제한적이어서, 한 번의 실행으로 원하는 모든 이벤트를 동시에 측정하는 것은 불가능할 때가 많다. 이 경우, 여러 번 프로그램을 실행하며 각기 다른 이벤트 조합을 측정해야 하는 번거로움이 있다.
흥미롭게도, HPC의 이러한 본래 목적은 예상치 못한 방향으로 확장되었다. 성능 엔지니어를 위해 설계된 이 정밀한 진단 도구는 보안 연구자들에 의해 새로운 용도를 찾게 되었다. HPC는 CPU 마이크로아키텍처 상태에 대한 직접적이고 낮은 수준의 가시성을 제공한다. Spectre나 Meltdown과 같은 현대의 정교한 공격은 전통적인 소프트웨어 버그가 아닌, 캐시나 분기 예측기와 같은 마이크로아키텍처 상태 자체를 조작하여 정보를 탈취한다. 결과적으로 HPC가 성능 문제를 진단하기 위해 탐지하도록 설계된 '성능 이상 징후'(예: 과도한 캐시 미스)는 이러한 공격이 생성하는 '보안 이상 징후'와 정확히 일치하게 된다. 이로 인해 HPC는 설계자들이 원래 의도하지 않았던, 그러나 매우 효과적인 보안 센서로 재탄생하게 된 것이다.
HPC와 사이드 채널 공격
사이드 채널 공격(Side-Channel Attack)의 개념
사이드 채널 공격(SCA)은 프로그램의 논리적 결함이나 암호화 알고리즘 자체의 취약점을 직접 공격하는 대신, 시스템이 정보를 처리하는 과정에서 '부수적으로' 또는 '의도치 않게' 유출하는 물리적인 정보를 활용하는 공격 기법이다. 이는 자물쇠를 부수거나 열쇠를 복제하는 대신, 금고 다이얼을 돌릴 때 나는 미세한 소리를 듣고 비밀번호를 알아내는 것과 비유할 수 있다. 여기서 '소리'가 바로 사이드 채널이다.
이러한 공격에 사용되는 주요 사이드 채널 정보는 다음과 같다.
-
타이밍 공격 (Timing Attacks): 특정 연산을 수행하는 데 걸리는 시간을 측정한다. 입력값에 따라 연산 시간이 미세하게 달라지는 경우, 이 시간 차이를 분석하여 비밀 정보를 추론할 수 있다.
-
캐시 공격 (Cache Attacks): 여러 프로세스가 공유하는 CPU 캐시 메모리의 상태 변화를 이용한다. 공격자는 특정 메모리 영역의 캐시 적중(hit) 및 미스(miss) 시간을 측정함으로써, 피해자 프로세스가 최근 어떤 데이터에 접근했는지 알아낼 수 있다.
-
전력 분석 및 전자기파 공격 (Power Analysis & EM Attacks): 장치가 연산을 수행할 때 소비하는 전력량의 변화나 방출하는 전자기파를 분석하여 내부에서 어떤 작업이 이루어지고 있는지 추론하는 공격이다.
근본 원인: 성능 최적화라는 양날의 검
역설적이게도, 이러한 사이드 채널 취약점의 근본 원인은 현대 CPU를 더 빠르게 만들기 위해 도입된 고도의 성능 최적화 기술 그 자체에 있다.
-
예측 실행 (Speculative Execution): CPU는 다음에 실행될 명령어를 미리 '추측'하여 실행함으로써 메모리 접근 등으로 인한 대기 시간을 줄인다. 만약 예측이 틀렸다면 실행 결과를 폐기하지만, 그 과정에서 발생한 부수적인 효과(예: 특정 데이터가 캐시에 로드되는 것)는 완벽하게 되돌려지지 않을 수 있다. Spectre와 Meltdown 공격은 바로 이 예측 실행의 흔적을 악용하는 대표적인 사례이다.
-
공유 자원 (Shared Resources): 클라우드 환경이나 단일 운영체제 내의 다중 프로세스 환경에서는 마지막 레벨 캐시(LLC)와 같은 하드웨어 자원이 여러 프로그램 간에 공유된다. 이러한 자원 공유는 공격자가 다른 프로그램의 활동을 엿볼 수 있는 통로, 즉 사이드 채널을 생성하는 기반이 된다.
이는 '성능-보안의 역설'을 명확히 보여준다. 더 높은 CPU 성능을 향한 끊임없는 경쟁은 예측 실행, 깊은 캐시 계층 구조와 같은 복잡한 최적화 기술을 낳았다. 그리고 바로 이 기술들이 치명적인 사이드 채널 공격을 가능하게 만든 직접적인 원인이 되었다. CPU 설계자들은 IPC(Instructions Per Cycle)를 높이기 위해 프로그램의 흐름을 예측하고 메모리 지연 시간을 숨기는 기능들을 추가했다. 예측 실행이 그 대표적인 예로, '필요할지도 모르는' 코드를 미리 실행한다. 예측이 틀렸을 때 최종 결과인 '아키텍처 상태'는 수정되지만, 캐시 내용과 같은 '마이크로아키텍처 상태'는 완벽하게 원상 복구되지 않을 수 있다. 이 '공식적인' 상태와 '임시적인' 상태 간의 불일치가 바로 공격자가 관찰할 수 있는 사이드 채널을 만든다.
HPC를 이용한 사이드 채널 공격 대응 원리
핵심 원리: 공격의 '마이크로아키텍처 발자국' 탐지
사이드 채널 공격은 전통적인 악성코드처럼 파일 시스템에 흔적을 남기거나 네트워크 로그에 기록되지 않아 매우 은밀하지만, 결코 보이지 않는 것은 아니다. 이러한 공격은 CPU의 정상적인 작동 패턴을 교란시키며, 마이크로아키텍처 수준에서 탐지 가능한 '발자국(footprint)'을 남긴다. 하드웨어 성능 카운터(HPC)는 바로 이 발자국을 포착하는 데 가장 이상적인 도구이다.
대응의 핵심 원리는 시스템의 정상적인 동작 상태에 대한 기준선(baseline)을 설정하고, HPC를 지속적으로 모니터링하여 이 기준선에서 통계적으로 유의미하게 벗어나는 이상 징후를 탐지하는 것이다.
공격 유형과 HPC 이벤트의 연관성
특정 공격 기법은 예측 가능한 HPC 이벤트 패턴을 유발한다. 이를 통해 공격 유형을 식별하고 대응할 수 있다.
-
캐시 공격 (Flush+Reload, Prime+Probe): 이 공격들은 공격자가 피해자와 공유하는 캐시 라인을 반복적으로 조작하는 행위를 포함한다. 예를 들어, Flush+Reload 공격에서 공격자는 특정 캐시 라인을 비우고(flush), 피해자가 해당 메모리에 접근하기를 기다린 후, 다시 로드(reload)하는 시간으로 접근 여부를 판단한다. 이 과정은 피해자 입장에서 비정상적으로 높은 캐시 미스율을 유발한다. 따라서 MEM_LOAD_UOPS_RETIRED.L3_MISS와 같은 마지막 레벨 캐시 미스 카운터를 모니터링하면 공격 징후를 포착할 수 있다. 피해자는 보안에 민감한 데이터에 접근할 때마다 공격으로 인해 추가적인 캐시 이벤트를 겪게 되는 것이다.
-
Spectre 계열 공격: 이 공격의 핵심은 분기 예측기를 '오염'시켜 잘못된 예측을 하도록 유도하고, 이를 통해 정상적으로는 실행되지 않았을 코드 경로를 예측 실행하게 만드는 것이다. 이 과정은 필연적으로 분기 예측 실패율을 급증시킨다. 따라서 BR_MISP_EXEC.*와 같은 분기 예측 실패 관련 카운터를 모니터링하면 Spectre 공격의 징후를 효과적으로 탐지할 수 있다.
정교한 분석의 필요성: 머신러닝의 도입
단순히 "캐시 미스가 임계값 X를 넘으면 경고"와 같은 단순한 규칙 기반 탐지는 실제 환경에서 효과적이지 않다. 시스템 환경은 매우 '시끄럽고(noisy)', 데이터베이스나 컴파일러와 같은 정상적인 고성능 애플리케이션도 높은 캐시 미스나 분기 예측 실패를 유발할 수 있기 때문이다.
이러한 문제를 해결하기 위해 보안 연구자들은 머신러닝(ML) 기술을 도입했다. 정상적인 워크로드와 악의적인 공격 워크로드에서 수집한 방대한 HPC 데이터를 사용하여 SVM, LDA, CNN과 같은 머신러닝 분류기를 훈련시킨다. 이렇게 훈련된 모델은 실시간으로 수집되는 HPC 데이터 스트림을 분석하여, 시스템의 현재 상태를 '정상' 또는 '공격 의심'으로 높은 정확도로 분류할 수 있다. 이 접근 방식은 개별 카운터의 절대적인 값이 아니라, 여러 카운터 간의 복잡한 패턴과 상관관계를 분석하기 때문에 훨씬 더 정교하고 오탐이 적다.
이러한 탐지 기술의 발전은 공격자와 방어자 간의 끊임없는 '군비 경쟁'을 촉발했다. 초기 HPC 기반 탐지 기법이 공개되자, 공격자들은 이를 회피하기 위해 공격 코드를 수정했다. 예를 들어, 의도적으로 무해한 캐시 읽기를 중간에 삽입하여 명령어당 캐시 미스 비율을 낮추는 방식으로 탐지를 우회하려 시도했다. 이에 대응하여 방어자들은 문서화되지 않은 희귀한 HPC 이벤트를 모니터링하거나, 속이기 더 어려운 복잡한 머신러닝 모델을 개발하는 등 탐지 기술을 계속해서 고도화하고 있다.
Spectre와 Meltdown, 그리고 HPC
2018년에 공개된 Spectre와 Meltdown 취약점은 현대 프로세서 설계의 근간을 뒤흔든 사건이었다. 이 두 공격은 HPC가 보안 영역에서 얼마나 중요한 역할을 할 수 있는지를 명확히 보여주었다.
취약점 핵심 원리
-
Meltdown: 사용자 애플리케이션과 운영체제(OS) 커널 사이의 근본적인 메모리 격리를 무너뜨리는 취약점이다. 공격자는 비순차적 실행(out-of-order execution)의 허점을 이용하여, 권한이 없는 사용자 프로그램이 커널 메모리의 내용을 임의로 읽을 수 있게 한다. 이를 통해 시스템 전체의 비밀 정보(암호, 키 등)가 유출될 수 있다.
-
Spectre: 서로 다른 애플리케이션 간의 격리를 파괴한다. 공격자는 피해자 프로세스를 속여 정상적인 상황에서는 절대 실행되지 않았을 코드 조각(gadget)을 예측 실행하도록 유도한다. 이 예측 실행 과정에서 피해자 프로세스의 민감한 정보가 캐시 상태 등 사이드 채널에 흔적을 남기게 되고, 공격자는 이를 통해 정보를 탈취한다. Meltdown과 달리 Spectre는 특정 결함이 아닌, 예측 실행을 악용하는 광범위한 공격 기법들의 '집합'에 가까워 완화가 훨씬 더 어렵다.
HPC 기반 공격 탐지 전략
Spectre와 Meltdown의 각 변종은 고유한 마이크로아키텍처 발자국을 남기며, 이는 특정 HPC 이벤트를 통해 탐지될 수 있다. 각 공격 기법과 이를 탐지하기 위한 핵심 HPC 이벤트를 정리하면 다음과 같다.
Meltdown (TSX 기반) 탐지
이 공격 변종은 인텔의 TSX(Transactional Synchronization Extensions)를 악용하여 커널 메모리를 예측적으로 읽는 동안 발생하는 예외를 억제하는 방식을 사용한다. 이는 OS의 예외 처리 루틴을 거치지 않아 훨씬 빠르고 은밀한 공격을 가능하게 한다.
-
핵심 탐지 이벤트:
RTM_RETIRED.ABORTED이 카운터는 하드웨어 트랜잭션이 중단된 횟수를 직접 추적한다. 정상적인 프로그램은 높은 비율의 TSX 중단을 거의 유발하지 않으므로, 이 카운터 값의 갑작스럽고 지속적인 급증은 이 공격 변종의 매우 강력한 지표가 된다.
Meltdown (예외 기반) 탐지
이 방식은 전통적인 OS 예외 처리에 의존한다. 공격 코드가 커널 메모리를 예측적으로 읽으면 페이지 폴트(page fault)가 발생하는데, 예외가 완전히 처리되기 전에 캐시 상태가 변하는 부수 효과를 이용해 정보를 빼낸다.
-
핵심 탐지 이벤트:
TLB.ITLB_FLUSH및MEM_LOAD_UOPS_RETIRED.L3_MISS사용자 공간에서 보호된 커널 페이지에 접근하면 예외 처리 과정에서 TLB(Translation Lookaside Buffer) 플러시가 발생할 수 있다. 따라서 이 이벤트의 비정상적인 발생률은 공격 신호일 수 있다. 또한, 유출된 데이터를 추출하는 후속 캐시 사이드 채널 공격으로 인해 L3 캐시 미스 카운터도 함께 증가하는 패턴을 보인다.
Spectre (분기 대상 주입) 탐지
이 공격은 공격자가 분기 대상 버퍼(BTB)를 '오염'시켜, 피해자 프로세스가 자신의 주소 공간 내에 있는 악의적인 코드 가젯(gadget)으로 예측적으로 점프하도록 만드는 것이 핵심이다.
-
핵심 탐지 이벤트:
BR_MISP_EXEC.*(분기 예측 실패)공격의 핵심 원리가 강제로 분기 예측을 실패하게 만드는 것이므로, 특정 프로세스에서 예측 실패한 분기 횟수가 현저하게 증가하는 것이 가장 중요한 지표이다. 추가적으로 LBR(Last Branch Record) 기능을 활용하면, 예측 실패가 탐지되었을 때 최근 실행된 분기 기록을 분석하여 공격으로 인한 비정상적인 분기 패턴을 구체적으로 식별할 수 있다.
캐시 공격 (Flush+Reload, Prime+Probe) 탐지
이 기법들은 대부분의 Spectre/Meltdown 공격에서 예측 실행을 통해 알아낸 비밀 값을 실제로 빼내는 마지막 단계에 사용된다. 공격자는 캐시 상태를 조작하고 탐색(probe)하여 정보를 알아낸다.
-
핵심 탐지 이벤트:
MEM_LOAD_UOPS_RETIRED.L3_MISS(캐시 미스)공격자의 탐색 행위는 캐시 히트와 미스 간의 시간 차이에 의존하며, 이 과정 자체가 캐시를 준비(prime)하거나 비우고(flush) 탐색하는 작업을 반복하므로 대량의 캐시 미스를 생성한다. 따라서 별다른 계산 작업 없이 비정상적으로 높은 캐시 미스율을 보이는 프로세스는 매우 의심스럽다고 볼 수 있다.
이러한 탐지 전략의 효과를 극대화하기 위해서는 단일 HPC 이벤트에만 의존해서는 안 된다. 예를 들어, L3_MISS 카운터 값은 데이터베이스와 같은 정상적인 워크로드에서도 높게 나타날 수 있다. 마찬가지로 BR_MISP_EXEC 값은 복잡한 제어 흐름을 가진 컴파일러 같은 프로그램에서도 높을 수 있다.
하지만 만약 동일한 프로세스에서 분기 예측 실패와 L3 캐시 미스가 동시에 급증한다면 이는 매우 비정상적인 신호이다. 이 패턴은 Spectre 공격의 전형적인 특징(분기 예측 실패로 공격을 시작하고, 캐시 미스로 정보를 유출)과 강력하게 일치하기 때문이다.
따라서 HPC를 이용한 보안 분석의 진정한 힘은 개별 카운터 값이 아닌, 여러 카운터 간의 상관관계와 시계열 패턴을 분석하는 데 있다. 이것이 바로 복잡한 패턴을 찾는 데 탁월한 머신러닝 기반 접근법이 효과적인 이유이다.
Windows에서 HPC 확인 및 모니터링
Windows 운영체제는 '성능 카운터'라는 고수준의 추상화 계층을 통해 하드웨어 성능 정보를 제공한다. 이는 사용 편의성을 높이지만, 때로는 리눅스의 perf 도구처럼 세밀한 마이크로아키텍처 이벤트에 직접 접근하기는 어려울 수 있다.
Windows 성능 카운터의 기본 개념
Windows의 성능 모니터링 시스템은 다음과 같은 계층 구조를 가진다.
-
성능 개체 (Performance Object): 모니터링할 수 있는 리소스의 큰 범주이다. 예를 들어 "Processor", "Memory", "PhysicalDisk" 등이 있다.
-
카운터 (Counter): 특정 개체 내에서 측정되는 구체적인 지표이다. 예를 들어 "Processor" 개체에는 "% Processor Time" 카운터가 있고, "Memory" 개체에는 "Available MBytes" 카운터가 있다.
-
인스턴스 (Instance): 동일한 유형의 개체가 여러 개 있을 경우, 각각을 구별하는 이름이다. 예를 들어 쿼드 코어 CPU의 경우 "Processor" 개체에는 0, 1, 2, 3 및 _Total 인스턴스가 있을 수 있다.
perfmon.exe (성능 모니터) 사용법
-
성능 모니터 실행:
Win + R키를 눌러 실행 창을 열고 perfmon을 입력하거나, 시작 메뉴에서 "성능 모니터"를 검색하여 실행한다. -
실시간 모니터링에 카운터 추가:
-
성능 모니터 창에서 그래프 위의 녹색 '+' 버튼을 클릭한다.
-
'카운터 추가' 대화 상자에서 원하는 성능 개체(예: "Processor Information")를 확장한다.
-
목록에서 추적할 카운터(예: "% Processor Time")를 선택한다.
-
해당 카운터의 인스턴스(예: 특정 코어 또는 _Total)를 선택한 후 '추가' 버튼을 클릭한다.
보안 관점에서 모니터링할 만한 유용한 카운터로는 Process(프로세스명)% Processor Time, Memory\Available MBytes, PhysicalDisk\Avg. Disk sec/Read 등이 있다.
- 데이터 수집기 집합(Data Collector Set)을 이용한 로깅:
장기간의 데이터 수집 및 사후 분석을 위해서는 데이터를 파일로 기록하는 것이 필수적이다.
-
왼쪽 탐색 창에서 '데이터 수집기 집합' > '사용자 정의'를 마우스 오른쪽 버튼으로 클릭하고 '새로 만들기' > '데이터 수집기 집합'을 선택한다.
-
마법사에 따라 집합의 이름을 지정하고, '수동으로 만들기(고급)'를 선택한다.
-
'데이터 로그 만들기'에서 '성능 카운터'를 선택한다.
-
앞서 설명한 방법으로 원하는 카운터를 추가하고, 데이터 샘플 간격(예: 5초)을 설정한다.
-
로그 파일이 저장될 위치와 형식(분석이 용이한 '쉼표로 구분'(CSV) 권장)을 지정하고 마법사를 완료한다.
-
생성된 데이터 수집기 집합을 마우스 오른쪽 버튼으로 클릭하여 '시작' 또는 '중지'할 수 있으며, 속성에서 특정 시간 동안만 실행되도록 예약할 수도 있다.
Windows 성능 모니터는 시스템 전반의 상태를 파악하는 데 매우 유용한 도구이다. 하지만 % Processor Time과 같은 고수준의 추상화된 카운터를 제공하므로, BR_MISP_EXEC와 같은 특정 마이크로아키텍처 이벤트를 직접 측정하는 것은 직관적이지 않다. 이러한 세밀한 하드웨어 수준의 보안 분석을 Windows 환경에서 수행하기 위해서는, 인텔 VTune Profiler나 Performance Counter Monitor(PCM)와 같이 CPU 제조사에서 제공하는 전문적인 도구를 사용하는 것이 일반적이다. 이들 도구는 Windows의 표준 성능 카운터 추상화 계층을 우회하여 하드웨어에 직접 접근하는 기능을 제공한다.
Linux에서 HPC 확인 및 모니터링
Linux 환경에서는 perf라는 강력한 커맨드라인 도구 모음을 통해 하드웨어 성능 카운터에 직접적이고 정밀하게 접근할 수 있다. perf는 Linux 커널 소스 코드의 일부이며, PMU를 활용하는 표준적인 방법으로 인정받고 있다.
perf 도구 모음 소개
perf는 하드웨어 이벤트(PMC), 소프트웨어 이벤트(커널 카운터), 트레이스포인트(커널 코드에 내장된 정적 프로브) 등 다양한 종류의 이벤트를 추적할 수 있다. perf 사용 권한은 시스템 보안 설정에 따라 달라진다. /proc/sys/kernel/perf_event_paranoid 파일의 값을 조정하여 일반 사용자의 접근 수준을 제어할 수 있다. 값이 낮을수록 더 많은 권한이 허용된다.
perf 핵심 명령어 및 사용 예시
perf의 일반적인 작업 흐름은 list로 측정 가능한 이벤트를 확인하고, stat으로 간단한 통계를 얻거나, record/report를 통해 심층적인 프로파일링을 수행하는 것이다.
-
perf list: 측정 가능한 이벤트 확인가장 먼저 실행해야 할 명령어이다. 현재 시스템의 CPU와 커널에서 지원하는 모든 하드웨어, 소프트웨어, 트레이스포인트 이벤트를 나열해 준다.
- 사용법:
perf list
- 사용법:
-
perf stat: 간단한 통계 수집특정 명령어가 실행되는 동안 또는 지정된 시간 동안의 이벤트 발생 횟수를 집계하여 보여준다.
-
기본 사용법 (명령어 실행 동안):
perf stat <command> -
예시:
perf stat ls -R / -
시스템 전체 모니터링:
perf stat -a sleep 5(5초 동안 시스템 전체의 기본 이벤트를 측정) -
특정 이벤트 및 프로세스 모니터링 (보안 분석용):
perf stat -e cycles,instructions,cache-misses,branch-misses -p <PID>(특정 PID를 가진 프로세스의 지정된 이벤트들을 측정)
-
-
perf record: 상세 프로파일링 데이터 기록이벤트 데이터를 perf.data라는 파일에 기록하여 나중에 perf report로 분석할 수 있게 한다.
-
시간 기반 샘플링 (일반적인 CPU 프로파일링):
perf record -F 99 -a -g -- sleep 10- 의미: 10초 동안, 시스템의 모든 CPU(-a)를 초당 99번(99Hz) 샘플링하고, 호출 그래프(-g)를 함께 기록한다. 99Hz를 사용하는 이유는 100Hz와 같은 정수 주파수에서 발생할 수 있는 주기적인 시스템 작업과의 동기화를 피하기 위함이다.
-
이벤트 기반 샘플링 (정밀 보안 분석):
perf record -e L1-dcache-load-misses -c 10000 -ag -- <suspicious_command>- 의미:
<suspicious_command>를 실행하는 동안, L1 데이터 캐시 미스가 10,000번 발생할 때마다 한 번씩 샘플링한다. 이를 통해 비정상적인 캐시 미스가 코드의 어느 부분에서 집중적으로 발생하는지 정확히 찾아낼 수 있다.
- 의미:
-
-
perf report및perf script: 기록된 데이터 분석-
perf report: perf.data 파일을 읽어들여 대화형 텍스트 인터페이스(TUI)로 분석 결과를 보여준다. 어떤 함수에서 가장 많은 이벤트가 발생했는지(핫스팟) 쉽게 파악할 수 있다. -
perf script: perf.data 파일의 원시 이벤트 데이터를 시간 순서대로 텍스트로 출력한다. 다른 분석 도구나 커스텀 스크립트로 데이터를 처리하고자 할 때 유용하다.
-
