Explicit Free Lists
-
free block만으로 리스트를 유지하므로 메모리가 많이 찼을 때 implicit free list 방식보다 훨씬 빠르다.
[implicit ~ : 탐색 속도가 블록 개수에 비례 / explicit ~ free 블록 개수에 비례] -
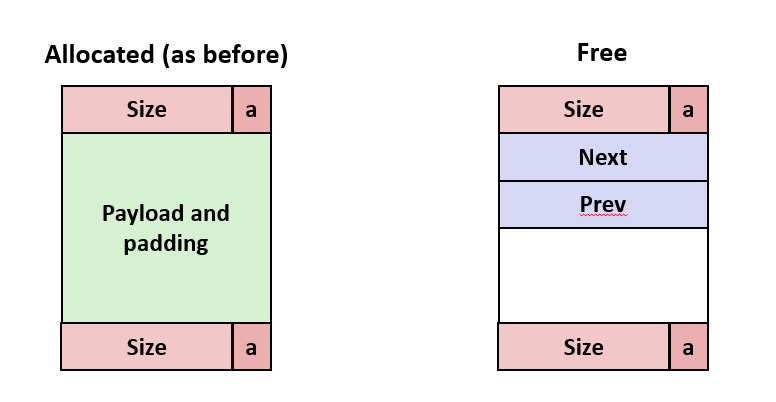
free 된 블럭만 Prev와 Next 포인터를 가지므로 Payload와 Padding을 저장하는 데는 문제가 없다.
-
header footer는 합치는 경우(coalescing)에 필요하다.
단점

Q. implicit free list방식보다 explicit free list방식에서 내부 단편화가 증가할까??
A. 증가한다. free블록들이 header, footer, prev, succ 포인터까지 포함해야돼서 최소 블록의 크기가 커지기 때문.
새롭게 free된 블록을 리스트의 어디에 넣을까??
-LIFO ✔
-address order
LIFO 방식을 선택해서 구현
Last-in Fisrt-Out : LIFO(후입선출) 방식 ✔
특징
- 가장 최근에 free된 block을 시작점에 둔다.
- find_fit() 함수를 first_fit방식에서 수정하지 않아도 블록을 처리하는 순서가 후입선출이기 때문에 next_fit방식과 같은 효율성이 있다.
장점: 단순, 간편. free block하는 시간이 상수시간이다. (바로 free)
단점: 단편화가 주소 순에 비해 나쁜(많은 편)
※ address order 방식과 비교
address order policy : 주소 순으로 정렬되도록 넣는다.
장점: 단편화가 LIFO에 비해 적은 편
단점: 넣을 자리를 찾는 검색이 필요함.
=> 주소 순으로 처리하기 때문에 적절한 pred를 찾는데 탐색이 필요하다.
address order방식은 first-fit방식과 적용했을 때 메모리 효율이 훨씬 좋다. (best-fit에 가까움)
구현 방식
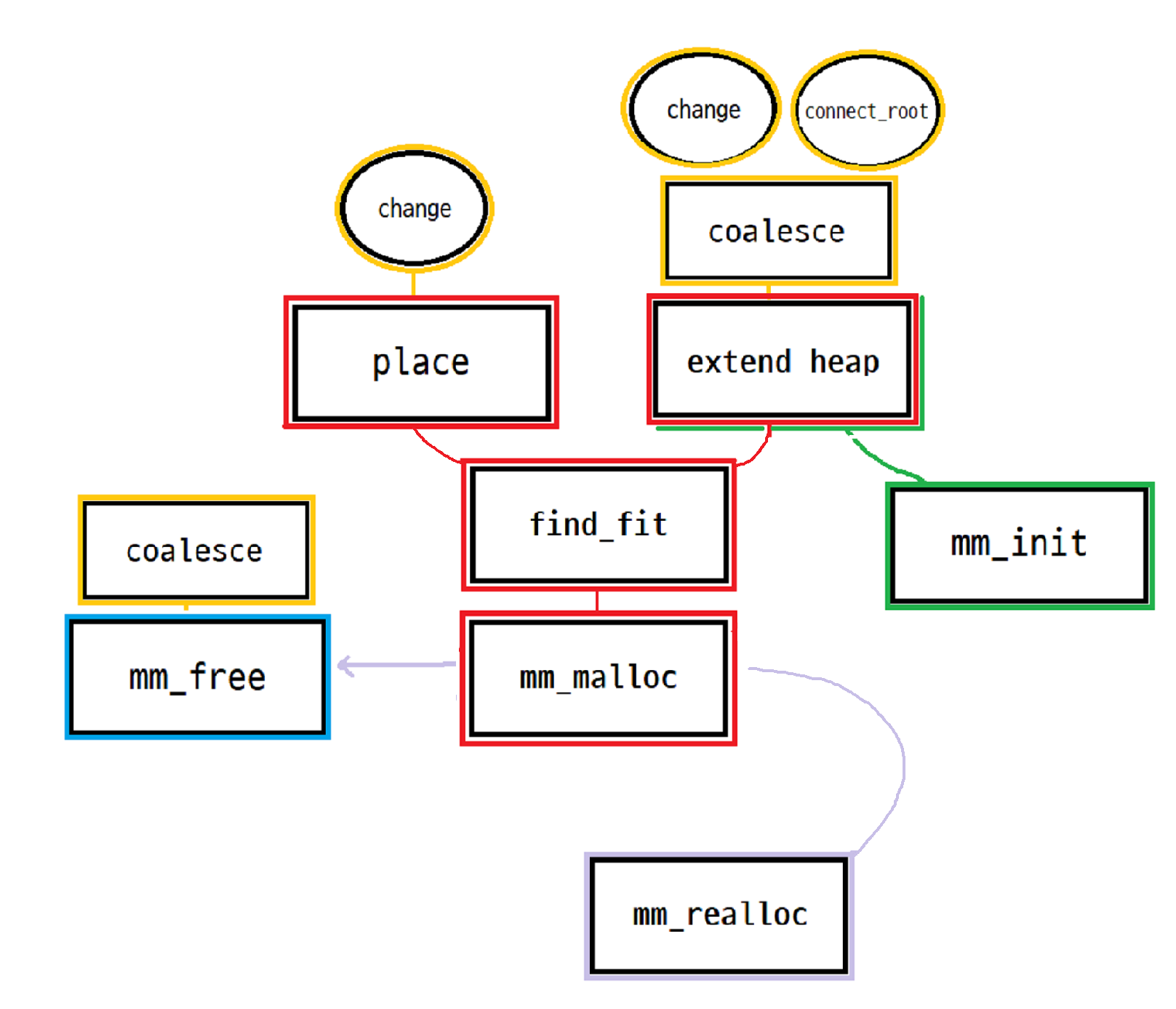
implicit free list 방식에서 크게 변한 함수는 place와 coalesce함수이다. 그리고 change 함수와 connect_root 함수가 추가되었다.
필요 함수
//PREV가 들어갈만한 WORD장소인것
#define PRED_LOC HDRP(bp)+WSIZE
//SUCC가 들어갈만한 WORD장소인것
#define SUCC_LOC HDRP(bp)+DSIZE
// PRED로 가는것 (순간이동)
#define PRED *(char *)PRED_LOC(bp)
// NEXT로 가는것 (순간이동)
#define SUCC *(char *)SUCC_LOC(bp)
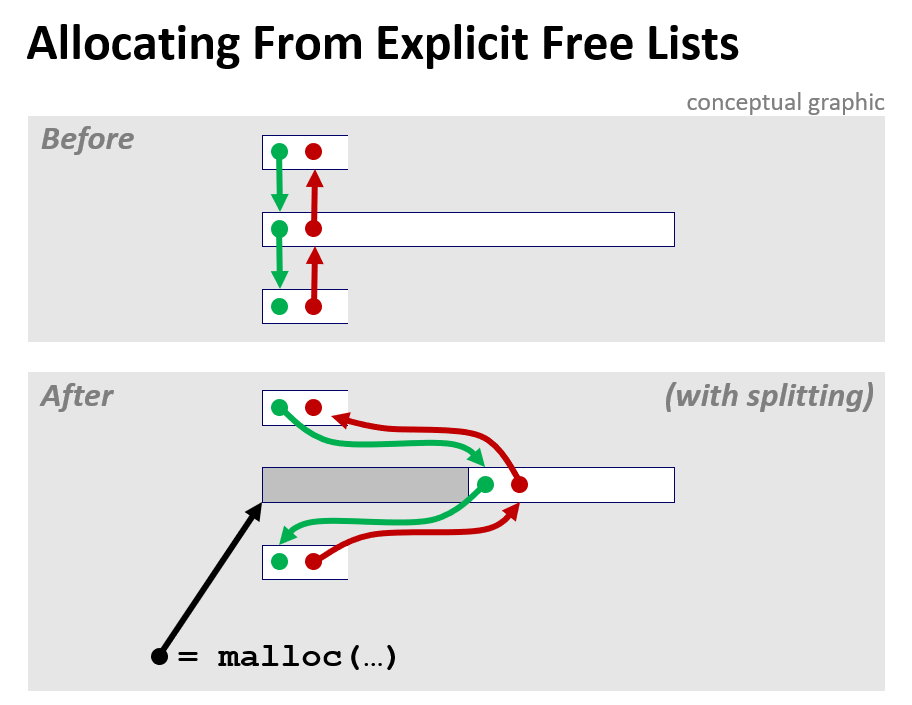
place() : 현재블록의 pred와 succ을 다른 곳으로 place해 줌
point : 할당할 블록을 분할할 것인가?
place에서는 공간이 다시 분할되어야되는지 판단한다.
explicit LIFO 방식에서는 implicit과 달리 물리적으로는 서로 떨어져있는 메모리블록들이 free된 순서대로 포인터로 연결되어 나열되기 때문에, 그 포인터정보들을 수정해줘야한다.
분할되었다면 (bp를 NEXT_BLKP(bp)로 옮긴 뒤) SUCC과 PRED에게 bp에서 NEXT_BLKP(bp)로 수정된 위치를 전달한다.
분할이 필요없으면 나빼고 너희들끼리 연결해라(change)한다.
분할한 경우
if 남는 공간이 최소 공간보다 같거나 크다면: => 분할
//1. 헤더와 푸터를 할당된 길이만큼 뒤로(새 free블록 자리로) 옮김
//2. pred와 succ을 옮겨줌
/*
내 pred의 값을 내 다음 블록 pred자리에 전달
= pred(bp)의 값을 pred_loc(NEXT_BLKP(bp))에 전달
*/
PUT(PRED_LOC(NEXT_BLKP(bp)),PRED(bp))
/*
내 succ의 값을 내 이전 블록 succ자리에 전달
succ(bp)의 값을 succ_loc(PREV_BLKP(bp))에 전달
*/
PUT(SUCC_LOC(NEXT_BLKP(bp)),SUCC(bp))
//3. bp를 next위치로 옮김
bp = NEXT_BLKP(bp)안 한 경우
else (안남음)
//나 빼고 기존에 있던 너희들끼리 연결해라.
//내 pred의 succ을 (원래 나였는데) 내 succ으로 바꿔줌
PUT(SUCC_LOC(PRED(bp)),SUCC(bp))
//내 succ의 pred를 (원래 나였는데) 내 pred로 바꿔줌
PUT(PRED_LOC(SUCC(bp)),PRED(bp))Coalesce():
case 1
상황 : 인접한블록은 둘다 할당이고, free블록 Root(A)와 C가 있는 상황에서 B free
: A와 C 사이에 B가 비집고 들어가는 것. connect_root(bp) 호출
case 2
뒷블록은 free, 앞블록은 allocate
connect_root(bp), change(다음블록bp) 호출
case 3
앞블록은 free, 뒷블록은 allocate
connec
case 4
상황: 앞 뒤의 free블록을 내 블록과 합쳐주고, 앞뒤의 free블록에 연결되어있던 pred와 succ을 정리해준 뒤, case1과 같이 A, C블록과 pred, succ 연결

coalesce될 블록이 있다면 그 블록에 연결되어있던 Next, Prev 포인터들은 정리해준다. (본인의 Prev 블럭의 Next 포인터, Next 블럭의 Prev 포인터 수정)
=> case 2는 본인 앞의 free블록, 3은 뒤의 free블록, 4는 앞 뒤의 free블록의 포인터들을 처리한다.
change():
나 빼고 너희들끼리 연결해라!
static void change(void *bp)
{
// NULL 배열은 다음에만 올 수 있다.
PUT_ADDRESS(SUCC_LOC(PRED(bp)), SUCC(bp));
// 나의 전 녀석과, 나의 뒷 녀석을 건드린다.
if (SUCC(bp) != NULL)
PUT_ADDRESS(PRED_LOC(SUCC(bp)), PRED(bp));
}connect_root():
루트 => 나 => 루트's 이전 다음을 연결시키기
(내가 둘 사이에 비집고 들어가는 그림)
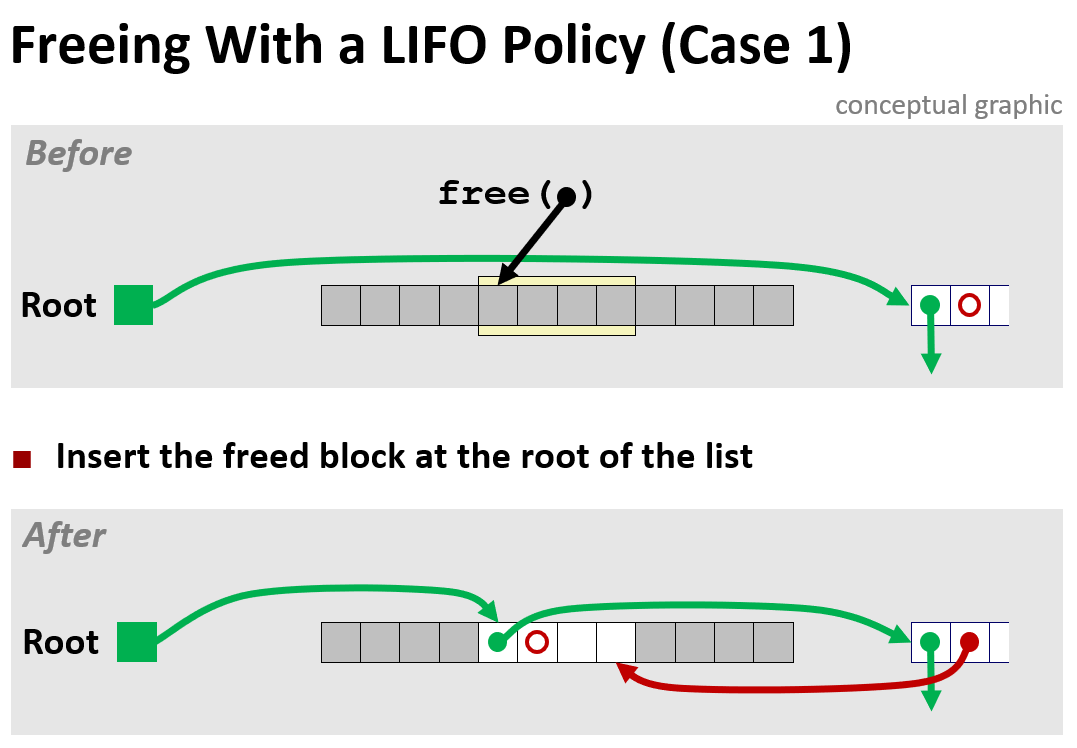
- Root는 가장 마지막으로 free된 블록을 가리킨다.
- 가장 마지막으로 free 된 블록은 Root가 가리키던 블록(그 전까지 마지막 free였던 블록)을 가리킨다.
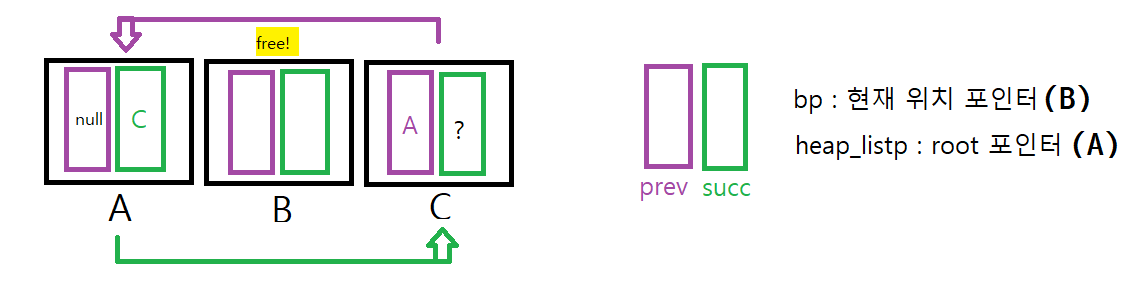
먼저 B의 PRED_LOC과 SUCC_LOC에 값을 채워준다.
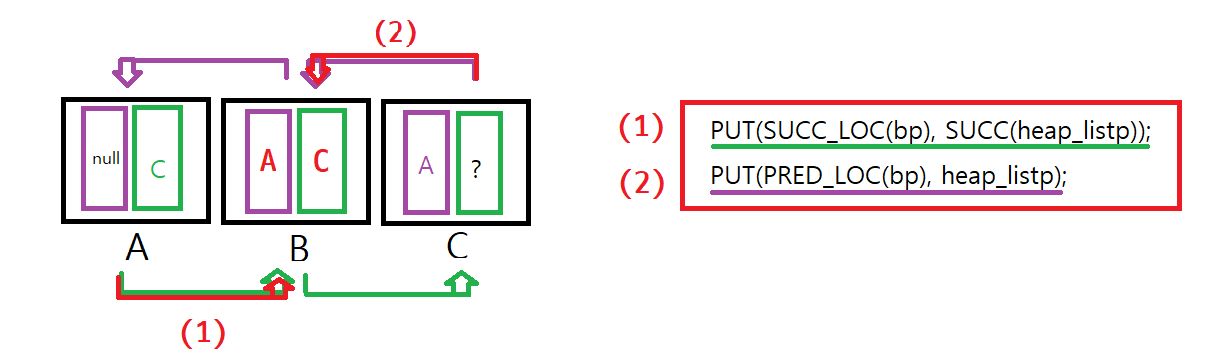
(1) bp(B)의 SUCC_LOC에 root(heap_listp)의 SUCC값을 넣어준다.
(2) bp(B)의 PRED_LOC에 root의 주소를 넣어준다.
(2)는 코드상에서 C에서 B로 날아오는 화살표는 아니긴 함
A의 주소값을 바로 B에 넣어준 것
그 다음 A의 SUCC_LOC, C의 PREV_LOC 값을 갱신해준다.
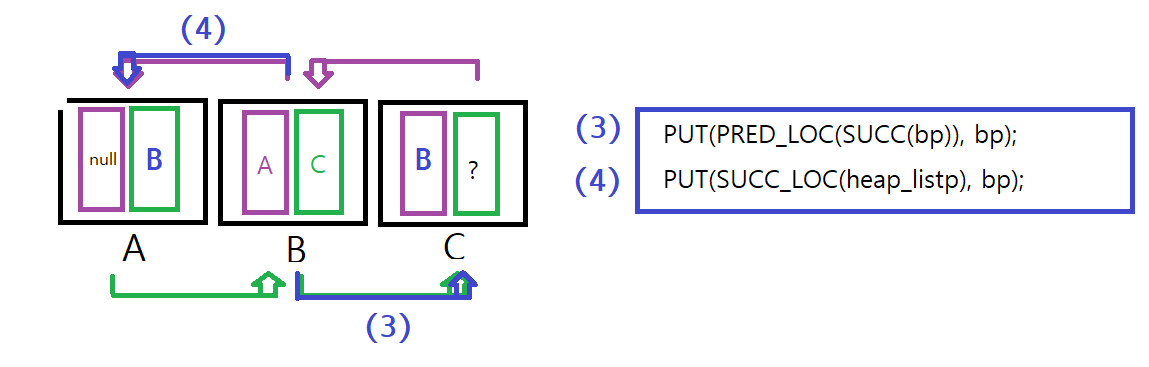
(3) bp(B)의 SUCC값(C)의 PRED_LOC자리에 bp(B)를 넣어라.
(4) heap_listp(root = A)의 SUCC_LOC 자리에 bp(B)를 넣어라.
static void connect_root(void *bp) {
// <1> 내 안에 양 root와 root의 이전 다음놈 정보를 저장
PUT(SUCC_LOC(bp), SUCC(heap_listp));
PUT_ADDRESS(PRED_LOC(bp), heap_listp);
// <2> root와 root의 이전다음놈에게 내 정보를 줌
// ※ 이때, root의 이전다음놈이 NULL이 아닌지 체크!
if (SUCC(bp) != NULL) {
PUT_ADDRESS(PRED_LOC(SUCC(bp)), bp);
}
PUT_ADDRESS(SUCC_LOC(PRED(bp)), bp);
}
이해하기 쉽게 정리해주셔서 감사합니다 ㅎㅎ 많이 배우고 갑니다 😊