해시테이블(Hash Table)
👉해시함수 h를 사용하여 key-value 쌍의 데이터를 입력받고, h에 key값을 입력으로 넣어 얻은 해시값 h(k)를 위치로 지정하여 key-value 데이터 쌍을 저장한다.
👍삽입, 삭제, 검색의 시간복잡도는 모두 O(1)이다.
주소화 방식은 크게 Direct-address Table과 Hash Table 2가지로 나뉜다.
Direct-address Table(직접 주소화 테이블)
👉key값이 k인 데이터를 index k 위치에 저장하는 방식으로, ArrayList를 떠올리면 된다.
🚩그런데, 이러한 테이블 방식은 다음과 같은 문제점이 있다.
-
불필요한 공간 낭비
인덱스를 기반으로 메모리에 저장하기 때문에 사용하지 않은 공간은 낭비가 될 수 있다. -
Key값으로 문자열이 올 수 없다.
왜냐하면 인덱스는 int형만 허용하기 때문
🔨위와 같은 문제점들을 해결하기 위해, Hash Table이라는 자료구조가 생겨났고, 해시 테이블은 다음과 같은 특징을 가진다
해시 테이블의 특성
-
모든 데이터에 key값은 무조건 존재해야 한다.
-
key값은 unique하기 때문에 중복되는 key값이 있어서는 안된다.
👉만약 duplicate key가 존재할 경우, 해시 테이블에서 collision을 일으켜서 예상치 못하게 기존의 value가 업데이트될 수 있다.🔎해시 테이블에서 collision이 발생하면, 아래와 같이 open-addressing을 사용해서 해결할 수도 있지만, 보통은 linear-probing을 하기 때문에 free-slot(or space)를 탐색하기 위해 최악의 경우 O(N)이 걸릴 수 있다.
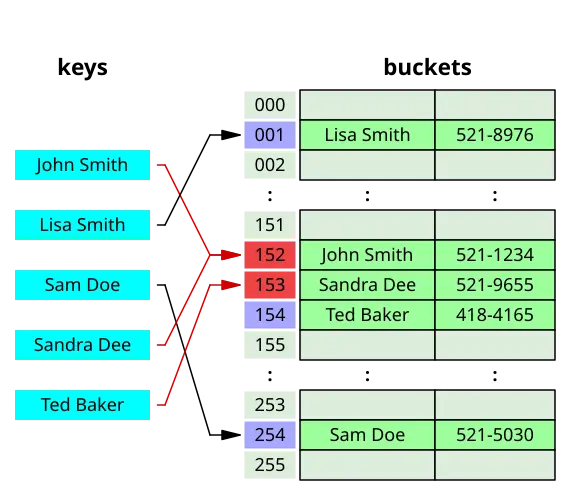
⏰시간복잡도 비교
Hash Table과 Doubly LinkedList, 그리고 Array의 시간복잡도를 아래의 표를 참고해서 비교해보자.
| 연산 / 구조 | Hash Table | Doubly LinkedList | Array (Dynamic) |
|---|---|---|---|
| access | O(1) (key) | O(N) | O(1) (index) |
| insert_front | ❌ | O(1) | O(N) |
| insert_back | ❌ | O(1) | O(1) |
| insert_at | ❌ | O(N) (노드 탐색) | O(N) (shift) |
| remove_front | ❌ | O(1) | O(N) (shift) |
| remove_back | ❌ | O(1) | O(1) amortized or O(N) if resizing needed |
| remove_at | ❌ | O(N) (노드 탐색) | O(N) (shift) |
- 해시 테이블은 위에서 말했다시피, 해시함수 h에 key값을 입력으로 넣어 얻은 해시값 h(k)를 위치로 지정하기 때문에 순서의 개념이 없어서 삽입/삭제, 검색의 시간복잡도는 O(1)이 된다.
자바의 해시테이블: HashMap
해시맵은 다음과 같이 생성할 수 있다:
HashMap<Key, Value> map = new HashMap<>();💡기본적으로 Primitive data type은 허용하지 않기 때문에, Wrapper class 또는 class type을 사용해야 한다.
그런데, 해시맵은 키-값 쌍의 개수에 따라 동적으로 크기가 증가하기 때문에 overhead가 크다. 따라서 초기에 저장할 데이터 개수를 알고 있다면 추가적으로 argument에 다음과 같이 initialCapacity와 load factor를 설정할 수도 있다.
HashMap<Key, Value> map = new HashMap<>(1000, 0.7f);🔖initialCapacity: 초기에 저장할 데이터 개수
🔖load factor: 몇 퍼센트 이상 해시 버킷이 차면, 해시 버킷의 크기를 2배의 크기로 resizing한다.
🔎실무에서 웹 서비스를 개발할 때는 대량의 데이터를 저장하거나 동시성, 메모리 최적화가 중요할 때 initialCapacity, loadFactor를 조정해서 리사이징 횟수를 줄이고 성능 최적화가 중요하다.
👉즉, 코테에서는 1초에 10^8개의 데이터를 연산 처리하기 때문에 필요없음!
💻해시맵의 메서드 종류
void clear(): 해시맵의 모든 요소들을 지운다.
boolean isEmpty(): 해시맵이 비었는지 확인
boolean containsKey(Object Key): 인자로 주어진 Key가 해시맵에 존재하는지 판단하여 boolean값을 반환한다.
🔎파이썬의 딕셔너리 in 연산자와 비슷하게 동작하고, key를 기반으로 탐색하기 때문에 O(1)이 걸린다.
boolean containsValue(Object value): 인자로 주어진 Value를 가진 Key가 해시맵에 존재하는지를 판단
⚠️value가 존재하는지 확인하기 위해 모든 값을 탐색하기 때문에 O(N)가 걸리므로 주의할 것!
Set<Map.Entry<K, V>> entrySet(): 해시맵의 모든 요소들을 파이썬의 dict.items()와 같이 'Key=Value'로 묶어서 Set으로 반환한다.
Set<K> keySet(): 해시맵의 모든 요소의 key만 묶어서 Set으로 반환한다.
Collection<V> values(): 해시맵의 모든 요소의 value만 묶어서 반환한다.
V get(Object key): 인자로 주어진 key와 매핑되는 Value를 반환한다.
- 만약 해시맵에 key가 없으면 null을 반환
V put(K key, V value): 인자로 주어진 key=value 쌍을 해시맵에 추가한다.
HashMap<String, Integer> map = new HashMap<>();
map.put("사과", 1);
map.put("바나나", 2);
map.put("포도", 3);
map.put("사과", 4);
map.put("복숭아", 5);- 만약 해시맵에 key가 이미 존재하면, 나중에 put된 value로 업데이트된다.
V remove(Object key): 해시맵에 인자의 key가 있으면 key=value 쌍을 제거하고 value를 반환한다.
- 주어진 key가 없으면 null을 반환한다.
V replace(K key, V value): 해시맵에 기존에 존재하던 key=oldValue를 새로운 key=value로 바꾼다.
- 만약 해시맵에 key가 없으면 null을 반환한다.
void forEach(BiConsumer<? super K,? super V> action): forEach를 사용하여 해시맵의 각 key=value쌍에 접근할 수 있는데 보통 람다식을 사용해서 다음과 같이 접근할 수 있다.
map.forEach((key, value) -> {
System.out.println("key = " + key);
System.out.println("value = " + value);
});🔎keySet(), entrySet(), values()로 만든어진 것들도 위와 같이 접근이 가능하다.
V getOrDefault(K Key, V defaultValue): key가 존재하면 key에 매핑되는 value를 반환하고, key가 존재하지 않으면 defaultValue를 반환한다.
- 기존의
map.get(K key)는 해당 key가 존재하지 않을 경우 null을 반환
🔎파이썬의dict.get(key, default_value)와 동일하다.
V putIfAbsent(K key, V value): key가 해시맵에 없을 때에만 put이 진행된다. 만약 기존의 key가 해시맵에 존재한다면, 그 key에 매핑되는 value를 반환한다.
💡기존에 저장한 key에 매핑되는 value를 업데이트하고 싶지 않을 때 사용한다.
V computeIfAbsent(K key, Function<? super K, ? extends V> mappingFunction): 해시맵에 key가 없으면 mappingFunction이 호출되서 key=value 값을 해시맵에 추가할 수 있다. 만약 해시맵에 key가 있으면 mappingFunction은 호출되지 않고 기존의 value를 반환한다.
map.computeIfAbsent("감", key -> 40);
System.out.println("map = " + map); // {감=40}V computeIfPresent(K key, BiFunction<? super K, ? super V, ? extends V> remappingFunction): 해시맵에 key가 있으면, remappingFunction을 호출해서 key=value 값을 해시맵에 갱신할 수 있다.
HashMap<String, Integer> map = new HashMap<>();
map.put("사과", 1);
map.put("바나나", 2);
map.put("포도", 3);
map.put("사과", 4);
map.put("복숭아", 5);
map.computeIfAbsent("딸기", k -> 40);
map.computeIfPresent("복숭아", (k, v) -> v + 50000);
System.out.println(map); // {복숭아=50005, 포도=3, 사과=4, 바나나=2, 딸기=40}🤔putIfAbsent() vs computeIfAbsent() 차이점
computeIfAbsent(): 키가 없으면 값을 얻기 위하여 호출하는 mappingFunction이 있다.
putIfAbsent(): value를 바로 가져오기 때문에 computeIfAbsent()보다 오버헤드가 크다.
var theKey = "Fish";
// key가 존재하여도 callExpensiveMethodToFindValue()가 호출된다.
productPriceMap.putIfAbsent(theKey, callExpensiveMethodToFindValue(theKey));
// key가 존재한다면 callExpensiveMethodToFindValue()가 결코 호출되지 않는다.
productPriceMap.computeIfAbsent(theKey, key -> callExpensiveMethodToFindValue(key));🔎putIfAbsent(): 타임어택이 있는 코테에서 사용해도 무난
computeIfAbsent(): 실무에서는 오버헤드가 곧 성능과 직결되기 때문에 캐시 구현, DB/API 조회 결과 저장 같은 상황에서 사용하면 효율성이 극대화된다.
📝그런데, 코테에서 주로 사용하는 해시맵은 다음과 같다.
| Java HashMap 메서드 | Python 딕셔너리 대응 |
|---|---|
| containsKey(key) | if key in dict: |
| keySet() | dict.keys() |
| values() | dict.values() |
| entrySet() | dict.items() |
| getOrDefault(key, defaultValue) | dict.get(key, defaultValue) |
| putIfAbsent(key, value) | dict.setdefault(key, value) (또는 if key not in dict: dict[key] = value) |
📚참고자료
🔗해시맵 메서드 및 사용법: https://gre-eny.tistory.com/97#Set%-CMap-Entry%-CK%-C%--V%-E%-E%--entrySet--
