Quartz And Spring Batch 설명
컴퓨터 클러스터와 Quartz를 이용한 분산 처리 방법 정리
컴퓨터 클러스터란?
컴퓨터 클러스터는 여러 대의 컴퓨터들이 연결되어 하나의 시스템처럼 동작하는 컴퓨터들의 집합을 의미합니다. 클러스터는 분산 처리를 통해 작업을 효율적으로 수행할 수 있도록 합니다.
Quartz를 이용한 분산 스케줄링
Quartz에서는 분산된 시스템을 하나로 동작하게 하기 위해 스케줄링 시스템을 데이터베이스(DB)화하여 관리합니다.
기존 방식
기존에는 메모리에 스케줄을 담고 있어, 여러 서버에서 동일한 소스로 구동 시 각각의 스케줄러가 동작하여 충돌 문제가 발생할 수 있습니다.
클러스터 방식
이를 해결하기 위해 스케줄을 DB에 담고, 각 서버는 DB에 저장된 정보를 기반으로 동작하게 됩니다. 하나의 서버가 스케줄을 선점하면 다른 서버는 해당 스케줄을 실행하지 않게 되어 충돌을 방지합니다. 또한 서버 간의 작업 분담과 서버 장애 시 대체가 가능합니다.
Quartz의 주요 테이블
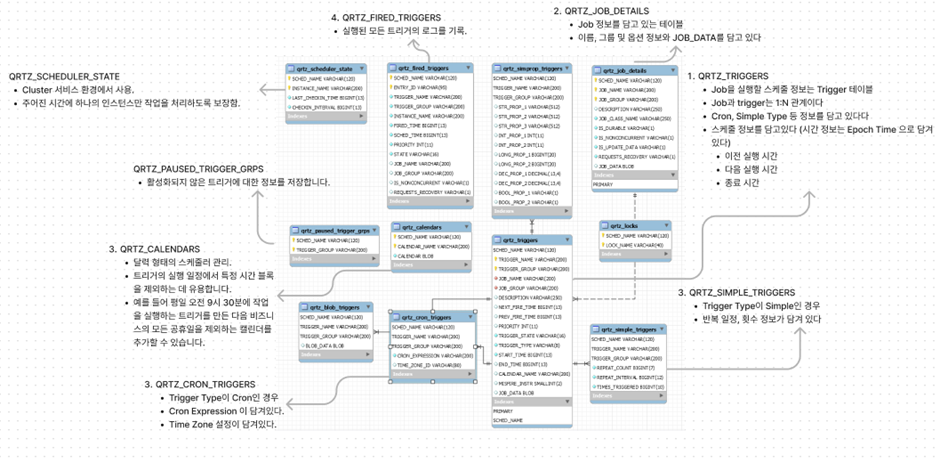
- QRTZ_JOB_DETAILS: Job 정보를 담고 있는 테이블. 이름, 그룹, 옵션 정보, JOB_DATA 등을 포함.
- QRTZ_TRIGGERS: Job을 실행할 스케줄 정보를 담은 테이블. Job과 1:N 관계이며, 스케줄 정보와 이전/다음 실행 시간 등을 포함.
- QRTZ_CRON_TRIGGERS: Trigger Type이 Cron인 경우, Cron Expression과 Time Zone 설정을 포함.
- QRTZ_SIMPLE_TRIGGERS: Trigger Type이 Simple인 경우, 반복 일정과 횟수 정보를 포함.
- QRTZ_CALENDARS: 달력 형태의 스케줄러 관리.
- QRTZ_LOCKS, QRTZ_SCHEDULER_STATE, QRTZ_FIRED_TRIGGERS, QRTZ_PAUSED_TRIGGER_GRPS: 실행 중이거나 활성화되지 않은 트리거 정보 등을 관리.
Batch의 주요 테이블
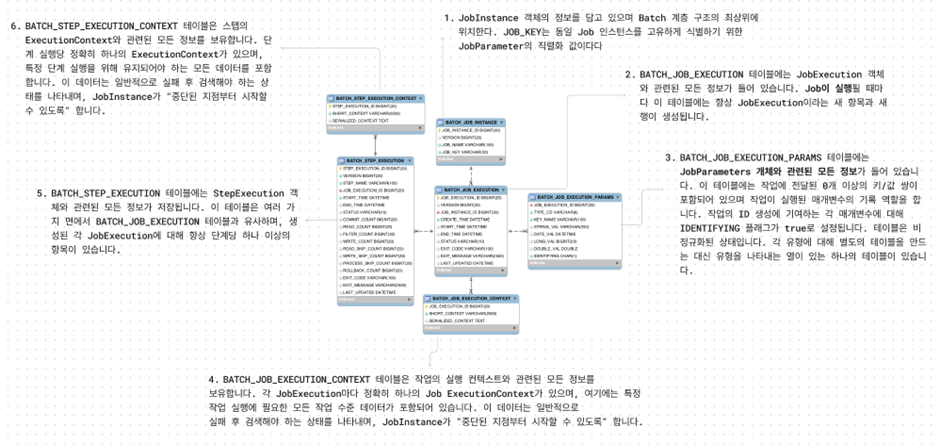
- BATCH_JOB_INSTANCE: Job 실행 시 고유 식별 정보를 등록하는 테이블.
- BATCH_JOB_EXECUTION: Job의 생성, 시작, 종료 시간 및 상태 값을 확인할 수 있는 테이블.
- BATCH_JOB_EXECUTION_CONTEXT, BATCH_JOB_EXECUTION_PARAMS: 작업 수준 데이터를 저장.
- BATCH_STEP_EXECUTION: Step 실행 정보를 담고 있는 테이블.
- BATCH_STEP_EXECUTION_CONTEXT: 작업 수준 데이터를 저장.
Quartz를 활용한 스케줄 및 Job, Trigger 등록 예제
@Bean
public Job testJob() {
return jobBuilderFactory
.get("testJob")
.incrementer(new RunIdIncrementer())
.start(testStep())
.build();
}
@Bean
@JobScope
public Step testStep() {
return stepBuilderFactory
.get("testStep")
.<TestDomain, TestDomain>chunk(100)
.reader(testReader())
.processor(testProcessor())
.writer(testWriter())
.build();
}
@Bean
public JobDetail jobDetail() {
JobDataMap jobDataMap = new JobDataMap();
jobDataMap.put("jobName", "testJob");
return JobBuilder.newJob(CustomQuartzJobBean.class)
.withIdentity("testJob", null)
.setJobData(jobDataMap)
.storeDurably()
.build();
}
@Bean
public Trigger jobTrigger() {
CronScheduleBuilder scheduleBuilder = CronScheduleBuilder.cronSchedule("0 * * * * ?");
return TriggerBuilder
.newTrigger()
.forJob(jobDetail().getKey())
.withIdentity("jobTrigger", null)
.withSchedule(scheduleBuilder)
.build();
}요약
- 컴퓨터 클러스터는 여러 컴퓨터를 하나의 시스템처럼 동작시켜 분산 처리.
- Quartz는 스케줄을 DB에 저장하여 클러스터 환경에서 스케줄링을 관리.
- 주요 테이블을 활용하여 스케줄 및 Job/Trigger를 관리 및 모니터링 가능.

기술블로거입니다