AWS Personalize-Serverless Infrastructure
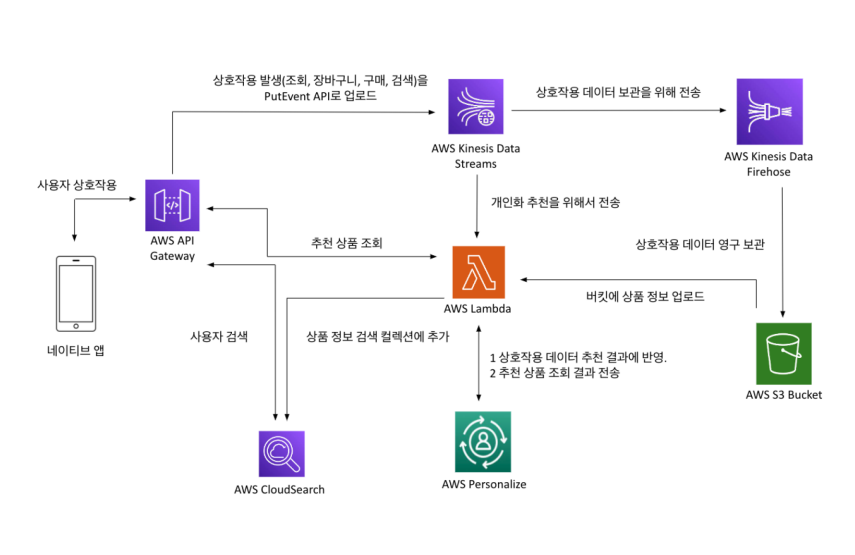
인프라 프로세스
URL Endpoint-to-API Gateway-Resource
1 API Gateway 생성
2 URL 쿼리 문자열 파라미터 추가
3 필요시 API 키를 해더 담아요 ACCCESS하게 수정
4 수정 후 api 테스트 돌리고
5 배포가 끝나야 사용 가능
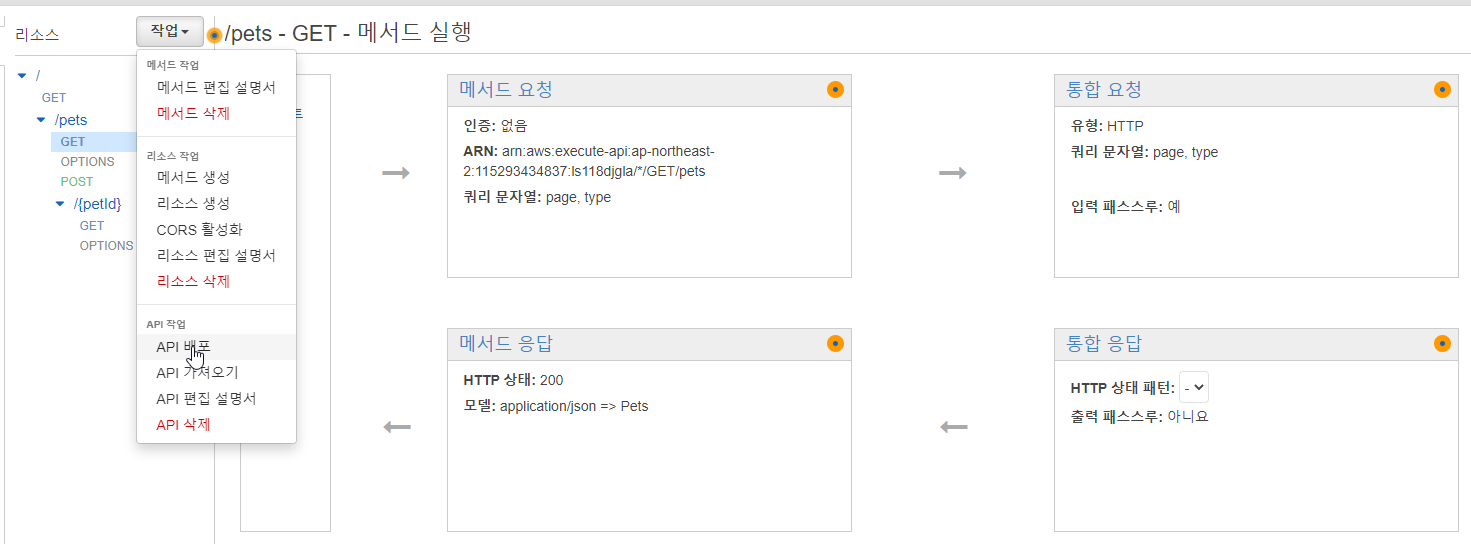
API Gateway-to-Lambda
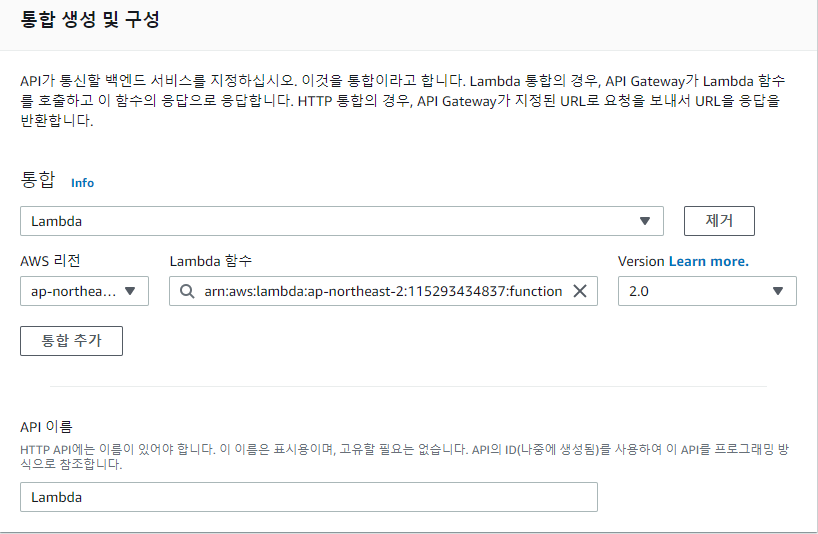
S3Bucket-to-CloudSearch-Lambda
S3 Bucket에 오브젝트 담으면 자동으로 CloudSearch 등록
var AWS = require('aws-sdk');
uuid = ()=>{
return 'xxxxxxxx-xxxx-4xxx-yxxx-xxxxxxxxxxxx'.replace(/[xy]/g, function(c) {
var r = Math.random() * 16 | 0, v = c == 'x' ? r : (r & 0x3 | 0x8);
return v.toString(16);
});
}
csvToJSON = function (csv_string, bucketName, docName) {
// 1. 문자열을 줄바꿈으로 구분 => 배열에 저장
//const rows = csv_string.split("\r\n");
// 줄바꿈을 \n으로만 구분해야하는 경우, 아래 코드 사용
const rows = csv_string.split("\n");
// 2. 빈 배열 생성: CSV의 각 행을 담을 JSON 객체임
const jsonArray = [];
// 3. 제목 행 추출 후, 콤마로 구분 => 배열에 저장
const header = rows[0].split(",");
// 4. 내용 행 전체를 객체로 만들어, jsonArray에 담기
for(let i = 1; i < rows.length; i++){
let obj = {}; // 빈 객체 생성: 각 내용 행을 객체로 만들어 담아둘 객체임
let objTemp = {}; //
let row = rows[i].split(","); // 각 내용 행을 콤마로 구분
obj['type'] = 'add';
obj["id"] = bucketName+':'+docName+uuid(); // INFO : concatenate bucket and filename
for(let j=0; j < header.length; j++){ // 각 내용행을 {제목1:내용1, 제목2:내용2, ...} 형태의 객체로 생성
objTemp[header[j].toLowerCase()] = row[j];
}
obj["fields"] = objTemp;// bucketName+':'+docName; // INFO : concatenate bucket and filename
jsonArray.push(obj); // 각 내용 행의 객체를 jsonArray배열에 담기
}
return jsonArray; // 5. 완성된 JSON 객체 배열 반환
// 문자열 형태의 JSON으로 반환할 경우, 아래 코드 사용
// return JSON.stringify(jsonArray);
}
addToIndex = function (bucketName, docName, docContent, context) {
var SERVICES_REGION = process.env.SERVICES_REGION;
var CS_NAME = process.env.CS_NAME;
var csd = new AWS.CloudSearchDomain({
endpoint: CS_NAME+'.'+SERVICES_REGION+'.cloudsearch.amazonaws.com',
apiVersion: '2013-01-01'
});
// see documentation at :
// http://docs.aws.amazon.com/cloudsearch/latest/developerguide/preparing-data.html#creating-document-batches
const arr_json = csvToJSON(docContent, bucketName, docName);
// TEMPLATE
/*
var jbatch = [
{ "type": "add",
"id": bucketName+':'+docName, // INFO : concatenate bucket and filename
"fields" : {
"category_l3" : "테스트",
"gender" : "null",
"item_id" : "테스트",
"price" : "1000",
"rating" : "1",
"category_l1" : "테스트",
"age" : "0",
"timestamp" : "1661225252",
"category_l2" : "테스트"
}
},
];
*/
//console.log(arr_json); // 3. JSON 변환 결과 확인
var params = {
contentType: 'application/json',
//documents: new Buffer('...'),
//documents: streamObject,
documents: JSON.stringify(arr_json),
};
csd.uploadDocuments(params, function(err, data) {
if (err) {
console.log('CloudSearchDomain ERROR');
console.log(err, err.stack);
context.done();
}
else {
console.log('CloudSearchDomain SUCCESS');
console.log(data);
context.done();
}
});
};
deleteFromIndex = function (bucketName, docName, context) {
var SERVICES_REGION = process.env.SERVICES_REGION;
var CS_NAME = process.env.CS_NAME;
var csd = new AWS.CloudSearchDomain({
endpoint: CS_NAME+'.'+SERVICES_REGION+'.cloudsearch.amazonaws.com',
apiVersion: '2013-01-01'
});
// see documentation at :
// http://docs.aws.amazon.com/cloudsearch/latest/developerguide/preparing-data.html#creating-document-batches
var jbatch = [
{"type": "delete",
"id": bucketName+':'+docName,
}
];
var params = {
contentType: 'application/json',
//documents: new Buffer('...'),
//documents: streamObject,
documents: JSON.stringify(jbatch),
};
csd.uploadDocuments(params, function(err, data) {
if (err) {
console.log('CloudSearchDomain ERROR');
console.log(err, err.stack);
context.done();
}
else {
console.log('CloudSearchDomain SUCCESS');
console.log(data);
context.done();
}
});
};
exports.handler = (event, context, callback) => {
var goesIN = (event.Records[0].eventName == 'ObjectCreated:Put');
var goesOUT = (event.Records[0].eventName == 'ObjectRemoved:Delete');
var filename = event.Records[0].s3.object.key;
var bucketname = event.Records[0].s3.bucket.name;
var params = {
Bucket: bucketname,
Key: filename,
RequestPayer: 'requester',
};
var s3 = new AWS.S3();
s3.getObject(params, function (err, data) {
if (err) {
console.log(err, err.stack);
if (goesIN) {
console.log('file was not found : ERROR');
}
else if (goesOUT) {
console.log('file was not found : as expected');
console.log(data);
deleteFromIndex(bucketname, filename, context);
}
else {
console.log('SCENARIO NOT HANDLED');
context.done();
}
}
else {
if (goesIN) {
//console.log('file was found : as expected');
//console.log(data);
var contentText = data.Body.toString('utf8');
addToIndex(bucketname, filename, contentText, context);
}
else if (goesOUT) {
console.log('file WAS found : ERROR');
}
else {
console.log('SCENARIO NOT HANDLED');
context.done();
}
}
});
};Kinesis Stream-Data Firehose
from aws_kinesis_agg.deaggregator import deaggregate_record
import base64
def construct_response_record(record_id, data, is_parse_success):
return {
'recordId': record_id,
'result': 'Ok' if is_parse_success else 'ProcessingFailed',
'data': base64.b64encode(data)}
def process_kpl_record(kpl_record):
raw_kpl_record_data = base64.b64decode(kpl_record['data'])
try:
# Concatenate the data from de-aggregated records into a single output payload.
output_data = b"".join(deaggregate_record(raw_kpl_record_data))
return construct_response_record(kpl_record['recordId'], output_data, True)
except BaseException as e:
print('Processing failed with exception:' + str(e))
return construct_response_record(kpl_record['recordId'], raw_kpl_record_data, False)
def lambda_handler(event, context):
'''A Python AWS Lambda function to process aggregated records sent to KinesisAnalytics.'''
raw_kpl_records = event['records']
output = [process_kpl_record(kpl_record) for kpl_record in raw_kpl_records]
# Print number of successful and failed records.
success_count = sum(1 for record in output if record['result'] == 'Ok')
failure_count = sum(1 for record in output if record['result'] == 'ProcessingFailed')
print('Processing completed. Successful records: {0}, Failed records: {1}.'.format(success_count, failure_count))
return {'records': output}
server-cloud-AWS-infra-gateway-lambda-service-cloundsearch,AWS Personalize-S3Bucket

기술블로거입니다