데이터베이스 이중화
DB-이중화 필요성-손상 대응-물리적,논리적
DB-이중화 필요성-부하 대응-분산 처리
-
오류로 인한 데이터베이스 서비스 중단 또는 물리적 손상 발생 시 이를 복구하기 위해 동일한 데이터베이스를 복제해서 관리
-
데이터베이스에 문제 발생 시 복제된 데이터베이스를 이용해서 즉시 문제 해결 가능
-
손쉽게 백업 서버 운영 가능
-
애플리케이션을 여러 개의 데이터베이스로 분산해 처리하므로 데이터베이스 부하를 줄일 수 있음
분류
DB 이중화-종류-데이터 변경-즉시 전달-Eager
DB 이중화-종류-데이터 변경-트렌젝션 완료 후 전달-Lazy
Eager 기법
- 트랜잭션 수행 중 데이터 변경이 발생하면 이중화된 모든 데이터베이스에 즉시 전달하여 변경 내용이 즉시 적용되도록 하는 기법
Lazy 기법
- 트랜잭션의 수행이 종료되면 변경 사실을 새로운 트랜잭션에 작성하여 각 데이터베이스에 전달되는 기법,
데이터베이스마다 새로운 트랜잭션이 수행되는 것으로 간주됨
이중화 구성 방법
DB 이중화 구성-종류-(활동-대기)-장애 발생시 대기 상태 DB가 대응
DB 이중화 구성-종류-(활동-활동)-장애 발생시 활동 상태 DB가 대응
활동-대기(Active-Standby)
방법
- 한 DB가 활성 상태로 서비스하고 있으면 다른 DB는 대기하고 있다가 활성 DB에 장애가 발생하면 대기 상태에 있던 DB가 자동으로 모든 서비스를 대신 수행 함
- 구성 방법과 관리가 쉬어 많은 기업에서 이용됨. 자원 소모가 덜하고, sync 문제 덜함.
활동-활동(Active-Active)
방법
- 두 개의 DB가 서로 다른 서비스를 제공하다가 둘 중 한쪽 DB에 문제가 발생하면 나머지 다른 DB가 서비스를 제공
- 두 DB가 모두 처리를 하기 때문에 처리율이 높지만 구성 방법 및 설정이 복잡. 부하 분산에 용이함.
클러스터링
두 대 이상의 서버를 하나의 서버처럼 운영하는 기술
- 고가용성 클러스터링 : 하나의 서버에 장애 발생 시 다른 서버가 받아 처리하여 서비스 중단을 방지하는 방식
- 병렬 처리 클러스터링 : 전체 처리율을 높이기 위해 하나의 작업을 여러 개의 서버에서 분산하여 처리하는 방식
로드 밸런서(Load Balancer) :
- DB 부하 대응-네트워크 서비스-여러 서버로 요청 분산
- 특성 서버에 집중되는 부하를 덜기 위해 여러 개의 서버로 부하를 분산시키는 네트워크 서비스
데이터베이스 회복 기법
장애 유형
DB-장애-유형-논리적인 오류, 시스템 오류, 디스크 오류
- 트랜잭션 장애: 트랜잭션의 실행 시 논리적인 오류로 발생할 수 있는 에러 상황
- 시스템 장애: H/W 시스템 자체에서 발생할 수 있는 에러 상황
- 미디어 장애: 디스크 자체의 손상으로 발생할 수 있는 에러 상황
복구 방법
DB-장애-복구-방법-로그 활용-오류 발생 시점 후 변경사항 취소-Undo-BEFORE COMMIT
DB-장애-복구-방법-로그 활용-오류 발생 트렌젝션 재실행-Redo-AFTER COMMIT
Undo:
- 트랜잭션 로그를 이용하여 오류와 관련된 모든 변경을 취소하여 복구 수행
- 로그파일에 트랜잭션의 시작(START)는 있고 종료(COMMIT)은 없는 경우 UNDO 수행
Redo:
- 트랜잭션 로그를 이용하여 오류가 발생한 트랜잭션을 재실행하여 복구 수행
- 로그파일에 트랜잭션의 시작(START)와 종료(COMMIT)이 있는 경우 REDO 수행
회복 기법
로그 기반 회복 기법
DB-장애 회복-로깅 기법-선 로그 후 (커밋시) 기록
DB-장애 회복-로깅 기법-선 기록 후 로그
지연갱신 회복 기법(Deferred Update)
- 선 로그 후 기록
- 트랜잭션의 부분 완료 상태에선 변경 내용을 로그 파일에만 저장
- 커밋이 발생하기 전까진 데이터베이스에 기록하지 않음
중간에 장애가 생기더라도 데이터베이스에 기록되지 않았으므로 UNDO가 필요 없음(미실행 된 로그 폐기)
즉시갱신 회복 기법(Immediate Update)
- 선 기록 후 로그
- 트랜잭션 수행 도중에도 변경 내용을 즉시 데이터베이스에 기록
커밋 발생 이전의 갱신은 원자성이 보장되지 않는 미완료 갱신이므로 장애 발생 시 UNDO 필요
검사점 회복 기법 (Checkpoint Recovery)
- 체크포인트(Checkpoint) 회복 기법이라고도 한다.
장애 발생 시 검사점(Checkpoint) 이전에 처리된 트랜잭션은 회복에서 제외하고 - 검사점 이후에 처리된 트랜잭션은 회복 작업 수행
- 검사점 이후, 장애 발생 이전에 commit이 완료된 경우 Undo 수행
- 장애 발생 시점까지 commit되지 못한 경우 Redo 수행
그림자 페이징 회복 기법 (Shadow Paging Recovery)
- 트랜잭션이 실행되는 메모리상의 Current Page Table과 하드디스크의 Shadow Page Table 이용
- 트랜잭션 시작시점에 Current Page Table과 동일한 Shadow Page Table 생성
- 트랜잭션이 성공적으로 완료될 경우 Shadow Page Table 삭제
- 트랜잭션이 실패할 경우 Shadow Page Table을 Current Page Table로 함
미디어 회복 기법 (Media Recovery)
- 디스크와 같은 비휘발성 저장 장치가 손상되는 장애 발생을 대비한 회복 기법
- 데이터베이스 내용을 백업, 미러링, RAID등을 통해 별도의 물리적 저장장치에 덤프
- 미디어 장애 시 가장 최근 덤프로 복구하고 로그 파일을 참조해 덤프 이후의 작업 Redo
(Undo는 사용되지 않음)
ARIES 회복 기법
- REDO 중 Repeating history: 붕괴가 발생했을 때의 데이터베이스 상태를 복구하기 위하여 붕괴 발생 이전에 수행했던 모든 연산을 다시 한번 수행. 붕괴가 발생했을 때 완료되지 않은 상태였던 (진행 트랜잭션)은 UNDO
- UNDO 중 Logging: UNDO를 할 때에도 로깅을 함으로써 회복을 수행하는 도중에 실패하여 회복을 다시 시작할 때에 이미 완료된 UNDO 연산은 반복하지 않음
DB 트렌젝션 격리 수전 (Transaction Isolation Level)
정의
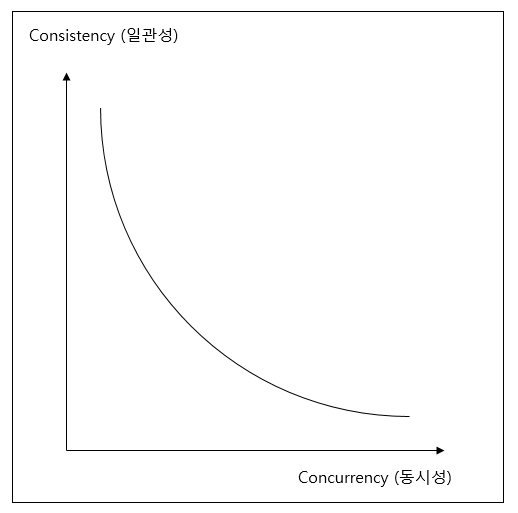
- 동시에 여러 트렌젝션 처리시 각 트렌젝션의 고립도 규칙을 정함.
트렌젝션 일관성과 동시성의 역설
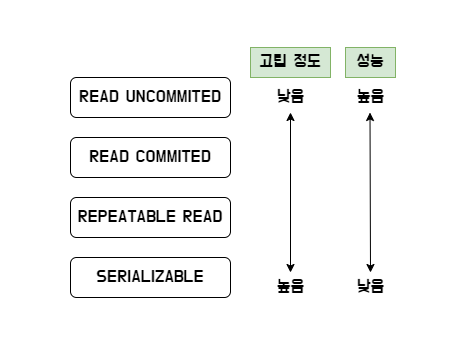
LV.0 READ UNCOMMITED
정의
- 커밋되지 않은 데이터에 접근 가능.
발생가능 문제
- Dirty read : UPDATE 또는 INSERT가 되기 전에 읽어서 최신 데이터로 읽을 수 없거나 오류가 발생함.
LV.1 READ COMMITED
정의
- 이미 커밋된 데이터만 조회 가능.
발생가능 문제
- Non-repeatable Read : 하나의 트렌젝션이 같은 값 조회시 다른 값이 검색되는 현상. 첫 번째 조회시 트렌젝션하고 두 번째 조회시 트렌젝션 정보가 달라짐.
LV.2 READPEATABLE READ
정의
- 트렉젝션 완료 전까지 한 번 조회한 값은 계속 같은 걸로 조회됨.
발생가능 문제
- Phantom Read : 유령처럼 데이터가 사라지가너 없어지는 현상. 트렌젝션 시적점에서 없던 데이터가 끝나는 시점에서는 조회가 됨.
LV.3 SERIALIZABLE
정의
- 트렌젝션이 특정 테이블을 읽을시 다른 트렌젝션은 그 테이블 데이터 접근 불가.
발생가능 문제
- Dirty Read, Non-Repeatable Read, Phantom Read 등의 정합성 문제는 없지만 동시 처리 성능이 가장 떨어짐.
출처
https://powerdev.tistory.com/44
https://raisonde.tistory.com/entry/데이터베이스-회복-기법-정리 [지식잡식]

기술블로거입니다