파드 개념
k8s는 파드라는 단위로 컨테이너를 '묶어' 관리한다. -> 파드는 컨테이너 여러개로 구성된다.
3장 예시들도 단일 컨테이너를 다루는 것처럼 보였으나 실제로는 컨테이너를 직접 관리하지 않고 파드 단위로 다룬것.
컨테이너 여러개를 한꺼번에 관리할 때는 컨테이너마다 역할 부여가 가능하다.
파드 하나에 속한 컨테이너들은 모두 노드 하나 안에서 실행된다. (여러 노드에 흩어져 실행되는 일은 없다) 이는 k8s에서 다루는 최소 단위가 파드이기 때문이다.
한 파드 안에 있는 컨테이너는 같은 IP 하나를 공유한다. 만약 외부에서 이 파드에 접근한다면? 일단 정해진 하나의 IP로 접근한다. 여기서 파드 안 컨테이너와 통신할땐 컨테이너마다 다르게 설정한 포트를 사용하게 된다.
그런데 컨테이너 하나에 역할 여러개를 부여할 수도 있다. 그럼 왜 굳이 파드로 컨테이너 여러개를 묶어 관리하는가? 실제론 컨테이너 하나에서 프로세스를 2개 실행하도록 설정하는게 쉽지 않기 때문이다. 시스템 신호나 종료 코드 처리도 프로세스마다 설정해줘야 하는 등의 번거로움이 존재한다. 컨테이너 관리 효율도 낮다.
파드 사용하기
교재의 파드의 탬플릿 설정 예시 YAML 파일을 참고하자.
apiVersion: v1
kind: Pod
metadata:
name: kubernetes-simple-pod --- 1
labels:
app: kubernetes-simple-pod --- 2
spec:
containers:
- name: kubernetes-simple-pod --- 3
image: arisu1000/simple-container-app:latest --- 4
ports:
- containerPort: 8080 --- 5- .metadata.name : 파드 이름 설정. 여기서는 kubernetes-simple-pod
- .metatdata.labels.app : 오브젝트 식별 레이블 설정. 여기서는 해당 파드가 앱 컨테이너고 kubernetes-simple-pod라고 식별한다고 설정
- .spec.containers[].name : 컨테이너 이름 설정. 여기서는 kubernetes-simple-pod라고 설정. name 앞의 '-' 표시는 배열을 의미한다. .spec.containers의 하위 필드를 배열형태로 묶겠다는 것을 의미한다. 그래서 .spec.containers[] 라고 표기한 것이다.
- .spec.containers[].image : 컨테이너에서 사용할 이미지를 정한다. 여기서는 저자가 컨테이너 환경 테스트용으로 만든 이미지를 설정했다.
- .spec.containers[].ports[].containerPort : 해당 컨테이너에 접속할 포트 번호를 설정한다. 여기서는 8080으로 설정
이를 pod.yaml로 저장한 후
kubectl apply -f pod-sample.yaml
명령으로 클러스터에 적용하자.
kubectl get pods
명령으로 STATUS 항목이 Running 이면 정상적으로 파드를 실행한 것.
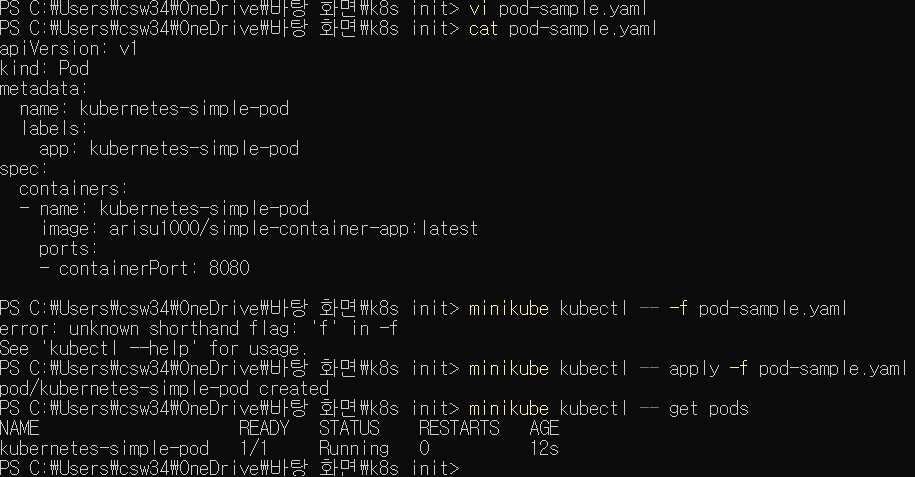
해당 실습은 minikube를 활용하여 진행되었다.
파드 생명 주기
파드는 생성부터 삭제까지의 과정에 생명주기Lifecycle 가 있다.
- Pending: k8s system에 파드를 생성하는 중임을 의미한다. 이 상태는 컨테이너 이미지를 다운로드한 후 전체 컨테이너를 실행하는 도중이므로 파드 안의 전체 컨테이너가 실행될 때까지 시간이 걸린다.
- Running: 파드 안 모든 컨테이너가 실행 중인 상태. 1개 이상의 컨테이너가 실행중이거나 시작 / 재시작 상태일 수 있다.
- Succeeded: 파드 안 몯느 컨테이너가 정상 실행 종료된 상태로 재시작되지 않는다.
- Failed: 파드 안 모든 컨테이너 중 정상적으로 실행 종료되지 않은 컨테이너가 있는 상태이다. 컨테이너 종료 코드가 0이 아니면 비정상 종료(ex: Out of memory는 137 종료코드) 이거나 시스템이 직접 컨테이너를 종료한 것이다.
- Unknown: 파드의 상태를 확인할 수 없는 상태이다 보통 파드가 있는 노드와 통신할 수 없을 때이다.
그럼 파드 생명 주기를 어떻게 확인 가능할까?
kubectl describe pods [pod name]
이후 status 항목을 살펴보면 확인할 수 있다.
현재 파드가 Running 상태임을 확인할 수 있다.
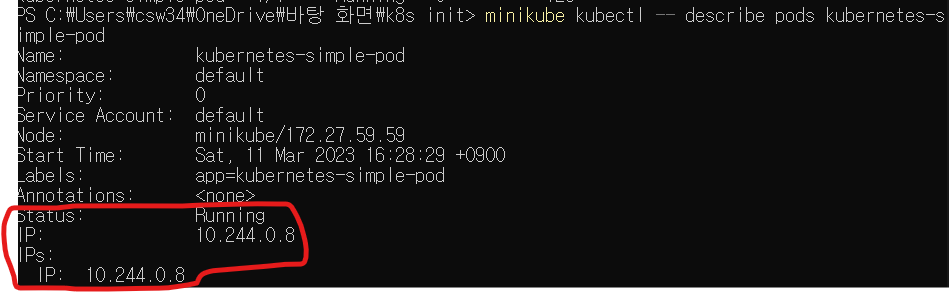
Condition 항목은 파드의 현재 상태를 나타낸다.
Type과 Status로 구분되어 있다.
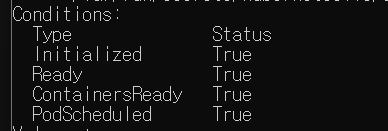
Type에는 다음 같은 정보가 있다.
- Initialized: 모든 초기화 컨테이너가 성공적으로 시작 완료되었다는 뜻.
- Ready: 파드는 요청들을 실행할 수 있고 연결된 모든 서비스의 로드밸런싱 풀에 추가되어야 한다는 뜻.
- ContainersReady: 파드 안 모든 컨테이너가 준비 상태라는 뜻.
- PodScheduled: 파드가 하나의 노드로 스케줄을 완료했다는 뜻.
- Unschedulable: 스케줄러가 자원의 부족이다 다른 제약등으로 지금 당장 파드를 스케줄할 수 없다는 뜻.(여기서는 표시되지 않았다.)
Status에는 True, False, Unknown(상태 알수 없음)으로 나뉜다.
kubelet으로 컨테이너 진단.
컨테이너 실행 후에는 kubelet이 컨테이너를 주기적으로 진단한다. 이때 필요한 프로브probe에는 다음 세가지가 있다.
- livenessProbe: 컨테이너가 실행됐는지 확인한다. 이 진단이 실패한다면 kubelet은 컨테이너를 종료시키고, 재시작 정책에 따라 컨테이너를 재시작한다. 컨테이너에 livenessProbe가 명시되지 않았다면 기본값은 Success이다.
- readinessProbe: 컨테이너 실행 후 실제로 서비스 요청에 응답할 수 있는지 진단한다. 이 진단이 실패하면 엔드포인트 컨트롤러endpoint controller는 해당 파드에 연결된 모든 서비스를 대상으로 엔드포인트 정보를 제거한다. 첫번째 readinessProbe를 하기 전까지의 기본 상태값은 Failure이다. readinessProbe 를 지원하지 않는 컨테이너라면 기본 상태값은 Success이다.
- startupProbe: 컨테이너 안 애플리케이션이 시작되었는지를 나타낸다. 이는 진단이 성공할 때까지 다른 나머지 프로브는 활성화되지 않는다. 또한 이것의 진단이 실패하면 kubelet이 컨테이너를 종료시키고 컨테이너를 재시작 정책에 따라 처리한다. 이것이 없으면 기본 상태값은 Success이다.
이 세가지 Probe가 k8s의 장점이다. readinessProbe를 지원하는 컨테이너는 실행된 다음 바로 서비스에 투입되어 트래픽을 받지 않는다. 실제 트래픽을 받을 준비가 되었는지를 확인한 후 받을 수 있다. 자바 app처럼 프로세스 시작 후 앱이 초기화될 때까지 시간이 걸리는 상황에 유용하다. 또한 대용량 데이터가 필요한 앱이나, 컨테이너 실행은 되었으나 앱의 환경 설정 실수로 앱이 실행되지 않는 상황 등에 대비 가능하다.
컨테이너 진단은 컨테이너가 구현한 핸들러handler를 kubelet이 호출해서 실행한다. 핸들러는 세가지가 있다.
- ExecAction: 컨테이너 안에 지정된 명령을 실행하고 종료 코드가 0일때 Success라고 진단.
- TCPSocketAction: 컨테이너 안에 지정된 IP와 포트로 TCP상태를 확인하고 포트가 열려 있으면 Success라고 진단.
- HTTPGetAction: 컨테이너 안에 지정된 IP, 포트, 경로로 HTTP GET 요청을 보낸다. 응답 상태 코드가 200~400이면 Success라고 진단한다.
진단 결과 역시 세가지가 있다.
- Success : 컨테이너 진단 성공
- Failure : 컨테이너 진단 실패
- Unknown : 진단 자체가 실패해 컨테이너 상태를 알 수 없음
초기화 컨테이너
app container가 실행되기 전 파드를 '초기화' 하는 컨테이너이다. 보안상 이유로 app container image와 같이 두면 안되는 app의 소스코드를 별도 관리할 때 유용하다.
특징
- 여러개 구성 가능. 여러개 있다면 pod tamplate에 명시한 순서대로 실행된다.
- 실행 실패하면 성공할 때까지 재시작한다. 이를 이용하면 k8s의 '선언적' 특징에서 벗어날 수 있다. 필요한 명령들을 순서대로 실행하는 데 사용하는 것이다.
- 이들이 모두 실행된 후에야 app container가 실행된다.
이런 특징을 이용해 pod 실행 시 app container가 외부 특정 조건을 만족할 때까지 기다렸다 실행하도록 만들 수 있다.
이들은 app container와 몇가지가 다르다. probe를 지원하지 않음을 기억하자. pod가 모두 준비되기 전 실행한 후 종료되어야 하는 컨테이너이기 때문이다.
초기화 컨테이너를 설정하는 pod의 yaml 예시
교재 예시 참고
초기화 컨테이너는 .spec.initContainers[] 의 하위 필드이다.
예시 하나를 보자
~
- name: init-myservice
image: arisu1000/simple-container-app:latest
command: ['sh', '-c', 'sleep 2; echo helloworld01;']
~name의 필드 값으로 init-myservice가 설정되었다.
image 필드 값으로 저자가 정한 이미지가 설정되었다.
command 필드 값으로 명령어가 설정되어 있는데, 이것의 의미는
'2초 대기 후 helloworld01 메세지 출력' 이다.
파드 인프라 컨테이너
k8s에는 모든 파드에서 항상 실행되는 pause라는 컨테이너가 있다. 이 pause를 'Pod infrastructure container' 라고 한다.
구조 참고
pause는 파드 안 기본 네트워크로 실행되며, 프로세스 식별자가 1(PID 1)로 설정되므로 다른 컨테이너의 부모 역할을 한다. 다른 컨테이너는 pause가 제공하는 네트워크를 고유해 사용한다. 그래서 파드 안 다른 컨테이너가 재시작됐을 때는 파드의 IP를 유지하지만, pause가 재시작된다면 파드 안의 다른 모든 컨테이너도 재시작된다.
kubelet에는 명령 옵션으로
--pod-infra-container-image
가 존재한다. pause가 아닌 다른 컨테이너를 파드 인프라 컨테이너로 지정하는 옵션이다.
스태틱 파드
kube-apiserver를 통하지 않고 kubelet이 직접 실행하는 파드들이 있다. Static pod이다. kubelet 설정의 --pod-manifest-path라는 옵션에 지정한 디렉터리에 스태틱 파드로 실행하려는 파드를 넣어두면 kubelet이 그걸 감지해 파드로 실행한다.
static pod는 kubelet이 직접 관리하며 이상이 생긴다면 재시작한다. 또 kubelet이 실행중인 노드에서만 실행되고 다른 노드에서는 실행되지 않는다.
kube-apiserver로 pod를 조회 가능하지만 static pod에 어떠한 명령을 실행할 수는 없다.
보통 static pod는 kube-apiserver, etcd같은 system pod를 실행하는 용도로 많이 쓰인다.
k8s에서 파드를 실행하려면 kube-apiserver가 필요한데 kube-apiserver자체를 처음 실행하는 별도의 수단으로 static pod를 이용하는것이다.
파드에 CPU와 메모리 자원 할당
노드 하나에 여러 개 파드를 실행하는 일이 자주 있다. 이때 자원 사용량이 큰 파드가 노드 하나에 모여있다면 파드들의 성능이 나빠지며 전체 클러스터 자원 효율도 낮아진다.
k8s에서는 이를 막는 여러 방법이 있다. 가장 기본적인 것은 파드 설정시 파드 안 각 컨테이너가 CPU나 메모리를 얼마나 사용할 수 있을지 조건을 지정하는 것이다.
파드에는 CPU와 메모리를 대상으로 자원 사용량을 설정하도록 .limit와 .requests 필드를 준비해두었다. 필드는 다음과 같다
- .spec.containers[].resources.limit.cpu
- .spec.containers[].resources.limit.memory
- .spec.containers[].resources.request.cpu
- .spec.containers[].resources.requestmemory
자원 사용량 설정의 예시
spec:
containers:
- name: kubernetes-simple-pod
image: arisu1000/simple-container-app:latest
resources:
requests:
cpu: 0.1 --- 1
memory:200M --- 2
limits:
cpu: 0.5 --- 3
memory: 1G --- 4
ports:
- containerPort: 80801, 2번 필드는 최소 자원 요구량을 나타낸다. 이 필드에 설정된 만큼 자원 여유가 있는 노드여야 그곳에 파드가 스케줄링되어 실행된다. 자원이 여기 요구하는 만큼 있는 노드가 없다면 파드는 Pending상태로 실행되지 않는다. 클러스터 내에 자원 여유가 생길 때까지 대기한다.
3, 4번 필드는 자원을 최대로 얼마나 사용할 수 있는지 제한하는 설정이다. 평소엔 사용량이 적더라도 갑자기 늘어날 수 있을 것이다. 이때 limit 설정이 따로 없다면 해당 컨테이너가 노드의 모든 자원을 사용할 수 있을 것이다. 그럼 같은 노드에 실행된 다른 컨테이너가 모두 영향을 받을수 있으며, 최악엔 클러스터 안 모든 서비스에 영향을 끼칠 수도 있다. limit설정은 이를 막아준다.
k8s가 파드를 스케줄링할 때는 노드의 현재 사용량을 보지 않는다. 파드에 설정된 해당 사용량만 확인한다.
메모리가 4GB 인 노드에 request.memory 필드값을 2GB로 설정하고 limit.memory 값을 설정하지 않았다면 파드가 메모리를 4GB 전부를 사용할 수도 있을 것이다.
이 상태에서 추가로 request.memory가 1.5GB인 파드를 할당하면 k8s는 노드 전체 메모리 4GB에서 현재 실행되는 파드의 request.memory 필드 값 2GB를 제외한 나머지 2GB가 실제 할당 가능한 메모리라 판단하고 해당 노드에 추가로 파드를 실행한다. 그런데 기존 파드의 사용량이 많아 1.5GB가 부족할 수 있을 것이다. 이러면 컨테이너가 실행되려다 Out of memory 에러를 발생시킨다.
이러한 상황을 막기 위해 limits.memory 필드를 설정해 최대값에 제한을 두는 것이다. 반대로 이 필드를 사용하지 않는다면 노드의 자원을 최대로 활용할 수 있을 것이다.
CPU는 어떻게 계산할 수 있을까? 예시를 보면 0.1, 0.5 등으로 표현된 모습이 보인다. 이는 CPU 코어 하나의 연산능력이 기준이 된 것으로, 1은 코어 하나의 연산 능력을 온전히 쓰도록 설정했다는 뜻이다. 0.1이라면 CPU코어 하나의 10%만큼 연산능력을 할당한다는 의미가 된다.
파드에 환경 변수 설정하기
컨테이너의 장점중 하나 : 개발 환경에서 만든 컨테이너의 환경 변수만 변경해 실제 환경에서 실행하더라도 개발 환경에서 동작하던 그대로 동작함.
파드의 환경 변수 설정 방법이다.
.spec.containers[].env[] 필드에서 설정한다. 다음과 같은 의미를 지닌다.
- name : 사용할 환경변수의 이름을 설정.
- value : 문자열이나 숫자 형식의 값을 설정.
- valueFrom: 값을 직접 할당하는 것이 아니라 어딘가 다른 곳에서 참조하는 값 설정.
- fieldRef : 파드의 현재 설정 내용을 값으로 설정한다는 선언.
- fieldPath : .fieldRef에서 어디서 값을 가져올 것인지 지정. 값을 참조하려는 항목의 위치를 지정.
- resourceFieldRef : 컨테이너에 CPU, 메모리 사용량을 얼마나 할당했는지에 관한 정보를 가져옴.
- containerName: 환경 변수 설정을 가져올 컨테이너 이름을 설정.
- resource : 어떤 자원의 정보를 가져올지 설정.
사용예시는 교재 참고
파드 환경 설정 내용 적용하기
파드는 환경 설정 내용을 탬플릿 하나에 모두 작성한 후 적용해야 한다.
실습 내용은 환경변수가 설정된 탬플릿을 적용한 후, 해당 컨테이너에 접속하여 env명령어로 환경변수를 확인하는 것이다.
파드 구성 패턴
파드로 여러 개의 컨테이너를 묶어서 구성하고 실행할 때 몇가지 패턴을 적용할 수 있다.
구굴의 '컨테이너 기반의 분산 시스템 디자인 패턴' 을 참고하면 도움이 된다.
- 사이드카 패턴
원래 사용하려던 기본 컨테이너의 기능을 확장/강화하는 용도의 컨테이너를 추가하는 것.
기본 컨테이너는 원래 목적의 기능에만 충실하도록 구성하고, 나머지 공통 부가 기능들은 사이드카 컨테이너를 추가해서 사용한다.
웹 서버의 예시)
웹 서버 컨테이너는 그 역할만 하고, 로그는 파일로 남긴다. 사이드카 역할인 로그 수집 컨테이너가 파일 시스템에 쌓이는 로그를 수집해 외부의 로그 수집 시스템으로 보낸다.
이러면 웹 서버 컨테이너를 다른 역할을 하는 컨테이너로 변경했을 때도 로그 수집 컨테이너는 그대로 사용 가능하다. 공통 역할을 하는 컨테이너의 재사용성을 높일 수 있다.
- 앰버서더 패턴
파드 안에서 프록시 역할을 하는 컨테이너를 추가하는 패턴이다. 파드 안에서 외부 서버에 접근할 때 내부 프록시에 접근하도록 설정하고, 실제 외부와 연결은 프록시에서 알아서 처리한다.
교재 예시 참조
웹 서버 컨테이너는 캐시에 localhost로만 접근하고, 외부 캐시 중 어디로 접근할지는 프록시 컨테이너가 처리한다.
이 방식은 파드의 트래픽을 더 세밀하게 제어할 수 있다는 장점이 있다.
- 어댑터 패턴
파드 외부로 노출되는 정보를 표준화하는 어댑터 컨테이너를 사용한다는 뜻이다. 주로 어댑터 컨테이너로 파드의 모니터링 데이터를 노출시킨다. 외부 모니터링 시스템은 이 어댑터 컨테이너에서 해당 데이터를 주기적으로 가져가 모니터링하는데 이용한다.
교재 예시 참조
