데몬 세트
클러스터 전체 노드에 특정 파드를 실행할 때 사용하는 컨트롤러. 클러스터 안에 새롭게 노드가 추가되었을 때 데몬세트가 자동으로 해당 노드에 파드를 실행시킨다.
반대로 노드가 클러스터에서 빠질때는 해당 노드에 있떤 파드는 그대로 사라질 뿐 다른곳으로 옮겨가서 실행되거나 하지는 않는다
따라서 데몬세트의 용도 : 로그수집기나 노드를 모니터링하는 모니터링용 데몬 등, 클러스터 전체에 항상 실행시켜두어야 하는 파드에 사용한다.
데몬세트 사용하기
예시 탬플릿을 보자
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: fluentd-elasticsearch
namespace: kube-system -------- 1
labels:
k8s-app: fluentd-logging ---- 2
spec:
selector:
matchLabels:
name: fluentd-elasticsearch
updateStrategy:
type: RollingUpdate ------------ 3
template:
metadata:
labels:
name:fluentd-elasticsearch
spec:
containers:
- name: fluentd-elasticsearch
image: fluent/fluentd-kubernetes-daemonset:elasticsearch -------- 4
env:
- name: testenv
value: value
resources:
limits:
memory: 200Mi
requests:
cpu: 100m
jmemory: 200Mi- 로그 수집기는 쿠버네티스 관리용 파드나 설정에 해당한다. 그래서 .metadata.namespace 필드값으로 kube-system 네임스페이스를 별도로 설정한것
- .metadata.labels.k8s-app 필드는 오브젝트를 식별하는 레이블로 키는 k8s-app, 값은 fluentd-logging으로 설정한다.
- 데몬세트의 파드를 업데이트하는 방법은 .spec.updateStrategy.type 필드값을 설정하는것. OnDelete / RollingUpdate 두가지 값이 있다. 기본값은 RollingUpdate
이 값일땐 탬플릿 변경시 바로 변경사항을 반영한다. 이때 모든 파드가 한꺼번에 변경되는 것이 아니라 지정한 개수만큼 이전 파드를 삭제하고 새로 파드를 실행하는 방식. .spec.updateStrategy.rollingUpdate.maxUnavailable 필드의 .spec.minREadySeconds 필드를 추가설정해 한번에 교체하는 파드개수를 조정한다. .spec.updateStrategy.rollingUpdate.maxUnavailable 필드는 한번에 삭제하는 파드개수고 .spec.minReadySeconds 필드는 새로 실행하는 파드가 준비상태가 되는 최소시간이다. 기본값은 0이라 파드가 준비되는대로 사용할 수 있다. - 로그수집에 사용하는 fluentd 의 컨테이너 이미지
이를 저장해
kubectl apply -f daemonset.yaml
명령으로 클러스터에 적용 후
kubectl get daemonset -n kube-system
명령을 실행해 결과를 확인하자

kube-system 네임스페이스에 fluentd-elasticsearch 라는 데몬세트가 만들어졌다. 만약 노드가 여러대라면 노드 수만큼 데몬세트가 생성되지만, 실습은 노드가 1개이므로 데몬세트용 파드가 1개뿐이다.
NODE SELECTOR 항목은 노드셀렉터가 설정되었으면 정보를 보여주며, 현재는 위와 같다.
데몬세트의 파드 업데이트 방법 변경
kubectl edit daemonset fluentd-elasticsearch -n kube-system
명령으로 앞에서 실행한 데몬세트의 현재설정을 열어 다른값으로 바꿔보자.
.spec.template.spec.containers[].env[].value 필드값을 value01로 바꾸고 저장하자.
현재 업데이트방식이 RollingUpdate이므로 파드는 즉시 재시작된다.
kubectl describe daemonset -n kube-system
위 명령으로 변경사항을 확인해보자
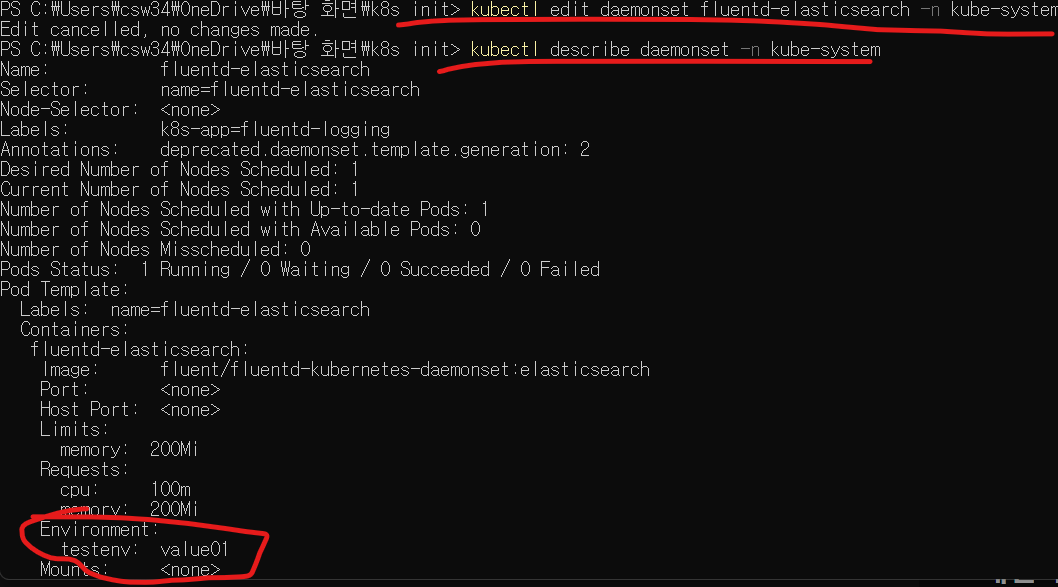
만약 업데이트 방식이 OnDelete라면 바로 적용되지 않는다. 데몬세트로 실행한 파드를 직접 지워야 해당 노드에 새로운 탬플릿버전의 파드가 실행되는 방식이다.
kubectl edit daemonset fluentd-elasticsearch -n kube-system
으로 .spec.template.spec.containers[].env[].value 필드값을 value02로, .spec.updateStrategy.type 필드값을 OnDelete로 변경한다.
기존 방식이 RollingUpdate 였으므로 여기까진 잘 반영된다.
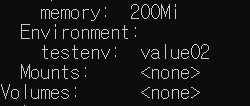
그럼 이제 OnDelete가 잘 작동하는지 확인해보자.

UP-TO-DATE 항목이 0이다. 변경은 했으나 최신 설정으로 변경되지 않았다는 뜻이다.
다음으로
kubectl delete pods [파드이름] -n kube-system
명령으로 해당파드를 지워보자.
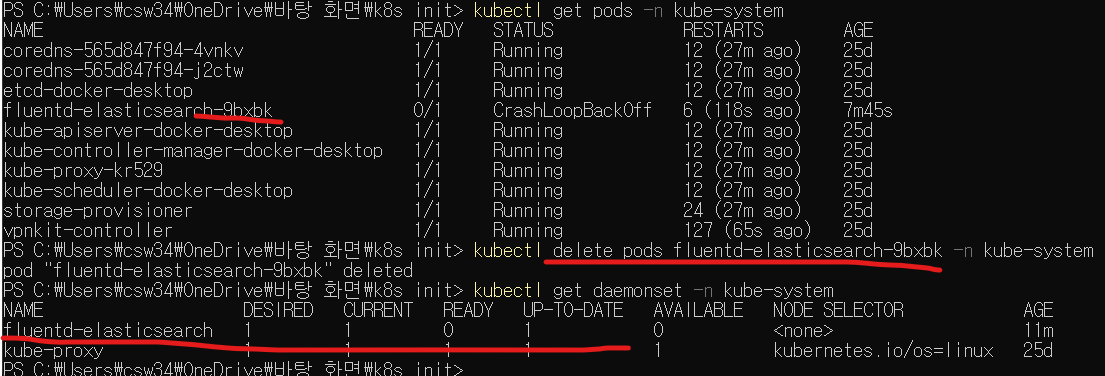
데몬세트가 최신상태로 변경되었음을 알 수 있다.
스테이트풀세트
앞서 배웠던 1,2,3절의 컨트롤러들은 모두 상태가 없는 파드들을 관리하는 용도였다. StatefullSets는 의미 그대로 상태가 있는 파드들을 관리하는 컨트롤러이다.
앞으로 설명할 volume을 사용해 특정 데이터를 저장한 후 파드를 재시작했을 때 해당 데이터를 유지한다.
또 여러개의 파드 사이에 순서를 지정해 그대로 실행되도록 할 수 있다.
이렇게 어떠한 상태가 있어야 할때 사용한다.
스테이트풀세트 사용하기
탬플릿은 다음과 같다.
apiVersion: v1 ------- 1
kind: Service
metadata:
name: nginx-statefulset-service
labels:
app: nginx-statefulset-service
spec:
ports:
- port: 80
name: web
clusterIP: None
selector:
app: nginx-statefulset-service ------ 1
---
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: web -------------------------- 2
spec:
selector:
matechLabels:
app: nginx-statefulset
serviceName: "nginx-statefulset-service"
replicas: 3
template:
metadata:
labels:
app: nginx-statefulset
spec:
terminationGracePeriodSeconds: 10 -------3
containers:
- name: nginx-statefulset
image: nginx
ports:
- containerPort: 80
name: web-
스테이트풀세트에서 사용할 서비스(7장 내용) 설정이다. .spec.serviceName 필드값으로 설정할 서비스를 정의한다. 서비스 이름과 스테이트풀세트에서 만들어진 파드 이름을 조합하면 k8s 클러스터 안에서 사용한느 도메인을 만들 수 있다. 조합은 [파드이름].[서비스이름] 형식이다.
-
스테이트풀세트의 이름이다. .metadata.name 필드 값으로, web으로 설정되어있다.
-
.spec.template.spec.terminationGracePeriodSeconds 필드는 그레이스풀의 대기시간을 설정한다. 10초이다.
그레이스풀? : 실행중인 프로세스를 종료할 때 바로 하는것이 아니라 하던 작업을 마무리 후 정상종료하는 것이다. 10초간 이걸 기다리겠다는 것이다.
이를 클러스터에 적용시켜보자. 이후
kubectl get svc,statefulset,pods
로 결과를 확인해보자.
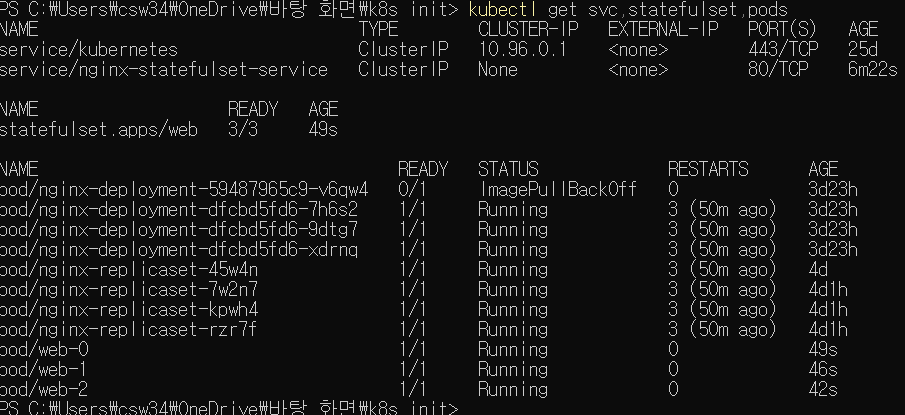
기존과 다르게 파드이름의 UUID 형식의 접미사가 붙는게 아니라, web- 이란 이름 뒤에 0,1,2처럼 숫자가 순서대로 붙은 모습이다. 파드가 실행될때 이 순서로 실행되며, 앞에 것이 정상 실행되지 않았다면 뒤의 파드는 실행되지 않는다
삭제는 실행의 역순이다.(2,1,0) 실행중인 스테이트풀 세트의 .spec.replicas 필드값을 줄이면 2번부터 줄인 숫자 개수만큼 삭제한다.
kubectl edit statefulset web
명령으로 실행중인 스테이트풀세트의 설정을 편집기로 열고 .spec.replicas 필드값을 3에서 2로 변경하자. 이후 내역을 확인하면
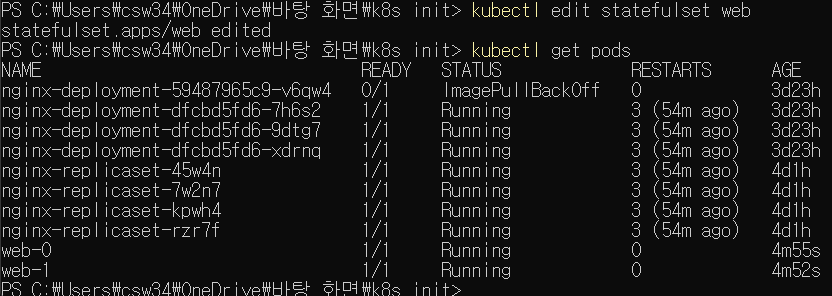
web-2 파드가 사라져 갯수가 2개로 맞춰진 모습이다.
파드를 순서 없이 실행하거나 종료하기
스테이트풀세트의 기본동작은 순서대로 파드를 관리하는 것이다.
하지만 .spec.podManagementPolicy 필드로 순서를 없애는 것도 가능하다.
기본 값은 OrderedReady이고 파드를 순서대로 관리한다
이를 Parallel로 변경하면 파드들이 순서없이 실행되거나 종료되도록 할 수 있다. 기존 스테이트풀세트에선 이를 변경할수 없다고 하니 새로운 스테이트풀세트를 설정하자.
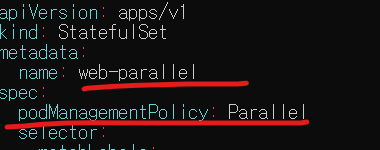
이전에 비해 이 부분이 달라졌다. 이름을 바꾸고 .spec.podManagementPolicy 필드를 추가하였다. 이를 적용하고 확인해보자.
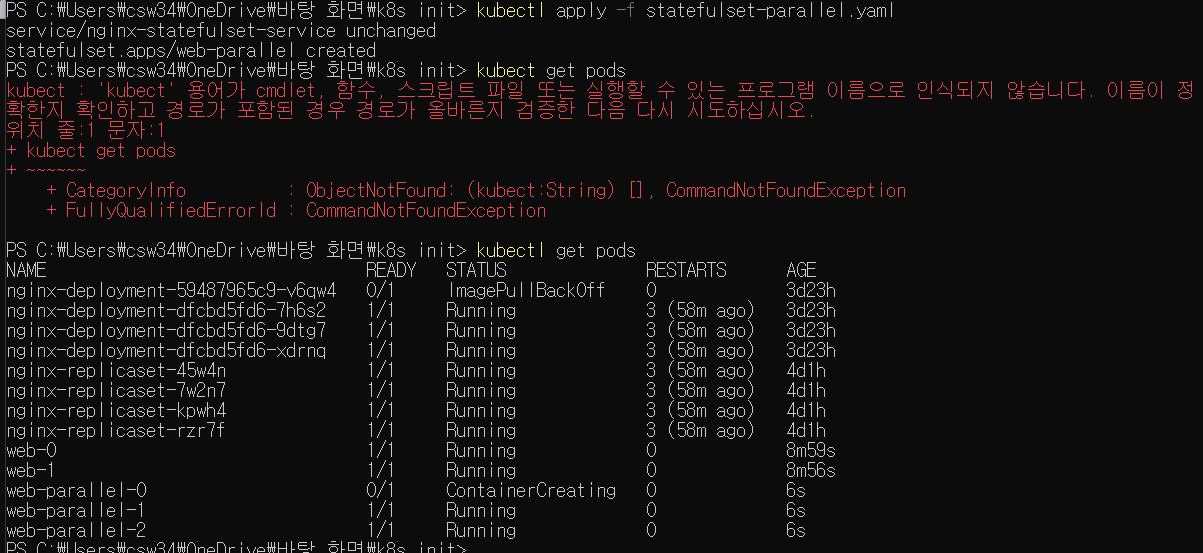
이전과 다르게 파드가 한꺼번에 만들어지는 모습이다. 1, 2번은 running인데 0번이 containercreating 상태인 것에서 이를 확인할 수 있다.
스테이트풀세트로 파드 업데이트하기
업데이트 방법을 .spec.updateStrategy.type 필드에서 설정 가능하다. 기본 값은 RollingUpdate이다. 탬플릿 변경시 자동으로 예전 파드 삭제 후 새로운 파드를 실행한다.
web 스테이트풀 세트에 kubectl edit statefulset web 명령을 실행해 .spec.template.spec.containers[].env[] 환경변수를 추가하고 저장하자
이후 확인해보면 탬플릿을 변경함에 따라 파드들이 재시작되는 걸 알 수 있다.
.spec.updateStrategy. rollingUpdate.partition 필드는 어떤 역할을 하는가? 여기 지정된 값보다 큰 번호를 가진 파드들만 업데이트를 적용시킨다. 말 그대로 파드들을 분할하는 역할이다.
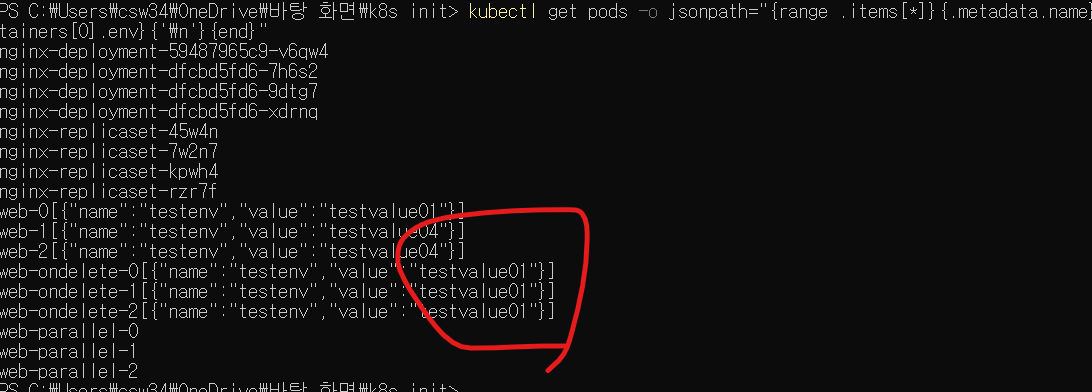
이 값을 1로 지정하고 .spec.containers[].env[].value 필드값을 testvalue04로 변경해 저장해보자. 어떤 일이 일어나는가?
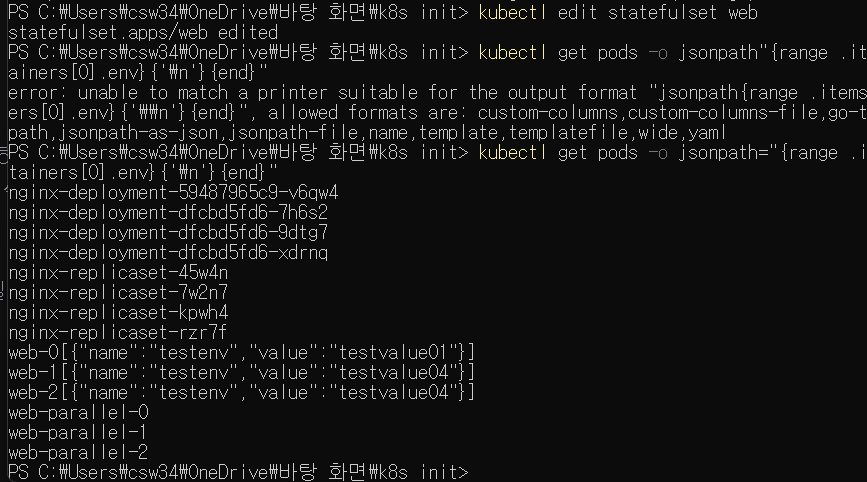
kubectl get pods -o jsonpath="{range .items[*]}{.metadata.name}{.spec.containers[0].env}{'\n'}{end}"
이 명령어를 통해 결과를 확인하였다. partition 필드에 값을 1로 지정했으므로 이보다 같거나 큰 1, 2번 파드만 업데이트가 적용되었다. 만약 partition 필드 값이 replicas 필드보다 크다면 .spec.template 필드에 변경사항이 있어도 업데이트하지 않는다.
kubectl describe pod web-0
위 명령으로 파드상태를 확인해보자
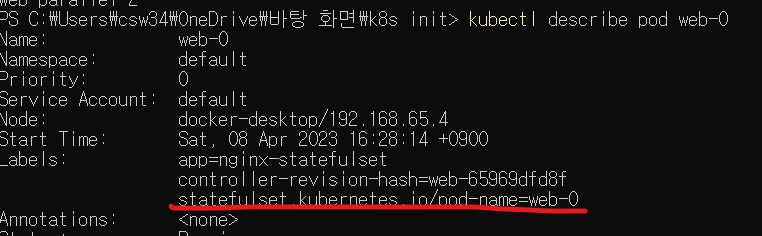
labels 항목에 새 레이블이 추가된 모습이다.
이 레이블을 이용하면 스테이트풀세트가 관리하는 전체 파드중 특정 파드에만 서비스를 연결할 수도 있다.
.spec.updateStartegy.type 필드값을 OnDelete로 설정하면 어떻게 될까? 스테이트풀세트의 템플릿을 변경해도 바로 반영되지 않는다. 사용자가 수동으로 스테이트풀세트에 속한 파드들을 삭제했을 때 새로운 설정이 있는 파드가 실행된다. 예시를 적용시켜 알아보자.
다음은 statefulset-ondelete.yaml 탬플릿이다
apiVersion: v1
kind: Service
metadata:
name: nginx-statefulset-service
labels:
app: nginx-statefulset-service
spec:
ports:
- port: 80
name: web
clusterIP: None
selector:
app: nginx-statefulset-service
---
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: web-ondelete
spec:
selector:
matchLabels:
app: nginx-statefulset
serviceName: "nginx-statefulset-service"
replicas: 3
template:
metadata:
labels:
app: nginx-statefulset
spec:
terminationGracePeriodSeconds: 10
containers:
- name: nginx-statefulset
image: nginx
ports:
- containerPort: 80
name: web
env:
- name: testenv
value: testvalue01
updateStrategy:
type: OnDelete이를 적용시키고, edit 명령으로 .spec.contaienrs[].env[].value 필드값을 testvalue01에서 testvalue02로 변경해 저장하자.
이후
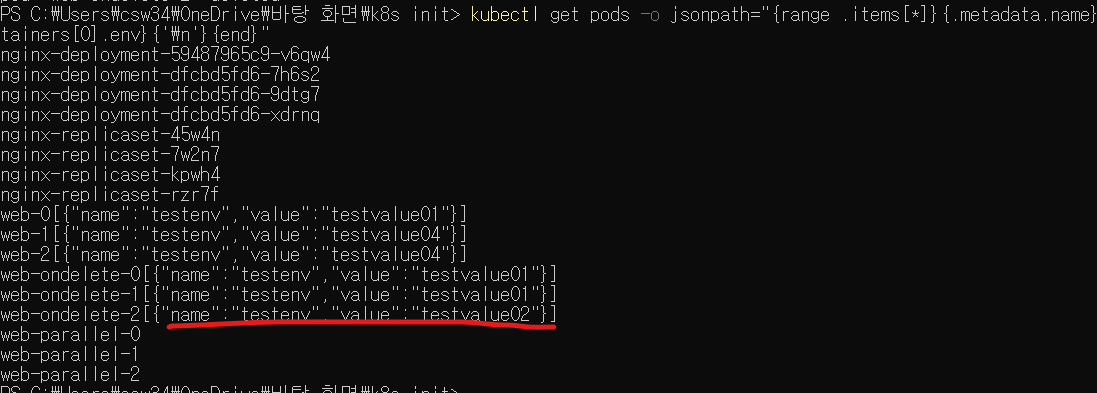
kubectl get pods -o jsonpath="{range .items[*]}{.metadata.name}{.spec.containers[0].env}{'\n'}{end}"
명령어로 결과를 확인해보면
업데이트가 적용되지 않은 모습이다. 여기서
kubectl delete pods web-ondelete-2
명령으로 web-ondelete-2 파드를 삭제해보자. 파드가 새로 실행되며 환경변수가 적용될것이다.
잡
잡job은 실행후 종료해야 하는 일회성 성격의 작업에 사용한다. 특정 개수만큼의 파드를 정상적으로 실행종료함을 보장한다.
파드 하나를 실행하고 정상 종료되는지 확인한다. 실행실패, 하드웨어 장애, 노드 재시작 등의 문제시엔 다시 파드를 실행하며, 잡 하나가 파드를 여러개 실행할 수도 있다.
잡 사용하기.
apiVersion: batch/v1 -------------------- 1
kind: Job
metadata:
name: pi
spec:
template:
spec:
containers:
- name: pi
image: perl
command: ["perl", "-Mbignum=bpi", "-wle", "print bpi(2000)"] --- 2
restartPolicy: Never ---------------- 3
backoffLimit: 4 ------------------------ 4-
잡이 사용하는 apiVersion은 batch/v1 이다. 배치 작업을 실행하는 v1버전 API를 사용한다는 의미
-
해당 명령어는 원주율을 계산하는 pearl 명령 내용이다.
-
Never로 설정해 파드가 항상 성공으로 끝나게 한다. 이 외에 OnFailure도 설정가능하다. 이는 파드 안 컨테이너가 비정상 종료했거나 다양한 이유로 실행이 정상 종료되지 않았을 때 컨테이너를 다시 시작하도록 한다
-
.spec.backoffLimit는 잡 실행이 실패했을 때 자동으로 최대 몇번까지 재시작할 것인지를 설정한다. 이를 파드 비정상 실행 종료의 backoff 정책이라고도 일컫는다. 기본값은 6이며 여기선 4이다. 보통 잡 컨트롤러가 재시작을 관리할 때마다 시간 간격을 늘린다. 처음 재시작 실패 후 10초를 기다린 후 시도하고 그 다음은 20초, 40초 이런 방식으로 계속 재시작 대기시간을 늘리는 것. 이렇게 재시작하다 파드실행이 완료되면 재시도 횟수는 0이 된다.
이 탬플릿을 적용시켜보자. 그리고 일정 시간 이후 kubectl describe job [잡이름] 으로 잡 상태를 확인하자
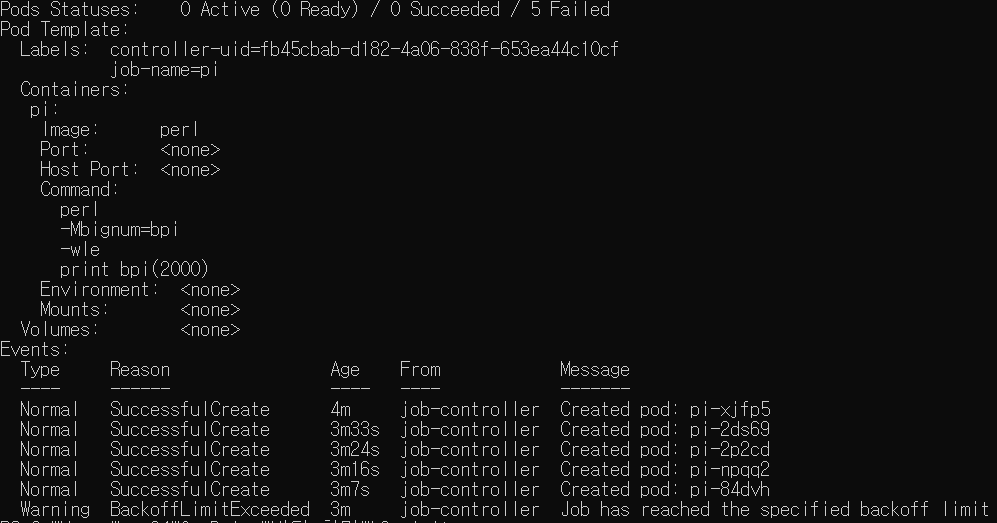
교재에선 성공했지만 난 실패했다. 오류가 네번 뜨고 backoff 정책에 걸려 정지된 모습이다.
원인을 모르겠어서 그냥 지웠다 왜 안될까?
잡 병렬성 관리
잡 하나가 몇개 파드를 동시 실행할지를 '잡 병렬성' 이라고 한다
.spec.parallelism 필드에 설정가능하다. 기본값은 1이고 0으로 설정하면 잡을 정지할 수 있다. 단, 병렬성 옵션을 설정했더라도 다음과 같은 이유로 지정된 값보다 잡이 파드를 적게 실행할 수 있다.
-
정상 완료되는 잡의 개수를 고정하려면, 병렬로 실행되는 실제 파드의개수가 정상 완료를 기다리며 남아있는 잡의 개수를 넘지 않아야 한다.
ex) 정상 완료되어야 하는 잡 개수가 10개고 현재 정상완료된 잡의 개수가 9개라면 병렬성을 3으로 설정했더라도 실제 파드는 3개가 아닌 1개만 실행된다. -
워크 큐용 잡에서는 파드 하나가 정상적으로 완료되었을 때 새로운 파드가 실행되지 않는다. 단, 현재 실행중인 잡은 완료될 때까지 실행될 수 있다.
-
잡 컨트롤러가 반응하지 못하거나 자원부족이나 권한부족같은 이유로 파드를 실행하지 못할때도 있다.
-
잡에서 실행시킨 파드들이 너무 많이 실패했으면 잡 컨트롤러가 새로운 파드생성을 제한할 수 있다.
-
파드가 그레이스풀하게 종료되었을 때도 있다.
잡의 종류
잡의 종류에는 단일잡, 완료된 잡의 개수가 있는 병렬parallel 잡, 워크 큐가 있는 병렬 잡이 있다.
단일 잡은 다음과 같은 특징이 있다.
-
파드 하나만 실행된다. 파드가 정상적으로 실행종료(파드생명주기가 succeeded) 되면 잡실행을 완료한다.
-
.spec.completions 와 .spec.parallelism 필드를 설정하지 않는다. 두 필드의 기본값은 1이다. .spec.completions 필드는 정상적으로 실행 종료되어야 하는 파드개수, .spec.parallelism 필드는 병렬성을 지정하는 필드이며 동시에 몇개의 파드가 실행되어도 괜찮은지를 설정한다. 그런데 두 필드값이 1이면 한번에 파드 하나만 실행되어야 하고, 정상적으로 실행종료 되어야 하는 파드개수도 1개라는 의미이다.
완료 개수가 있는 병렬 잡에는 다음 특징이 있다.
-
.spec.completions 필드 값으로 양수를 설정한다. 필드값이 1이면 정상적으로 실행동료된 파드가 1개만 생겨도 잡이 완료된다.
-
.spec.parallelism 필드는 설정하지 않거나 기본값인 1로 설정해야 한다.
워크큐가 있는 병렬 잡에는 다음 특징이 있다.
-
.spec.compltions 필드는 설정하지 않고, .spec.paralleism 필드는 양수로 설장한다.
-
.spec.completions 필드값을 설정하지 않으면 기본값이 .spec.parallelism 필드와 동일하게 설정된다.
-
파드 각각은 정상적으로 실행 종료됐는지를 독립적으로 결정할 수 있다. 대기열에 있는 작업들이 모두 동시에 실행될 수도 있다는 뜻
-
파드 하나라도 정상적으로 실행 종료되면 새로운 파드가 실행되지 않는다.
-
최소한 파드 1개가 정상적으로 종료된 후 모든 파드가 실행 종료되면, 잡이 정상적으로 종료된다.
-
일단 파드 1개가 정상적으로 실행종료되면 다른 파드는 더이상 동작하지 않거나, 어떤 작업 처리결과를 내지 않는다. 다른 파드는 모두 종료과정을 실행한다.
비정상적 실행종료된 파드 관리하기
비정상적 실행 종료된 컨테이너를 대비해 컨테이너 재시작 정책을 설정하는 .spec.template.spec.restartPolicy 필드를 지정할 수 있다.
컨테이너가 비정상 실행 종료될 때의 예는 메모리 사용량 제한초과, 비정상 종료코드 표시 등 다양하다. 이때 이 필드값을 OnFailure로 설정하면 파드는 원래 실행중이던 노드에서 컨테이너를 재시작한다. 이때 앱 컨테이너가 재시작되는 상황을 고려해야 한다.
컨테이너 재시작 정책을 Never 로 설정할 수도 있다. 이러면 재시작을 막을 수 있다.
ex) 파드를 실행 중이던 노드가 장애나 업그레이드를 이유로 정지될 때도 있다. 이때 필드값이 Never라면 컨테이너가 비정상 종료했을 때 재시작을 막을 수 있다. 재시작을 막은 후 잡에서 새 파드를 실행한다. 이렇게 파드가 재시작되는 상황도 앱 컨테이너에서 처리해야 한다.
이전 파드에서 처리중이던 상태를 인식해 해당 상태부터 재시작하거나 아니면 초기화하고 처음부터 다시 시작할수도 있어야 한다.
그런데 .spec.parallelism과 .speccompltions 필드값을 1, .spec.template.spec.restartPolicy 필드값을 Never로 설정하면 같은 프로그램이 2번 실행될 수도 있다. 이때는 저 위 필드 값 모두 1보다 크게 설정하면 여러개 파드가 실행될수 있다.
앱은 이러한 상황을 고려해 처리할 수 있도록 설계되어야 할 것이다.
잡 종료와 정리
잡이 정상적으로 실행종료되면 파드가 새로 생성되지도, 삭제되지도 않는다. 또한 잡도 남아있다. 파드나 잡이 삭제되지 않고 남아있으면 로그에서 에러/경고를 확인할 수 있고, 잡의 상태도 계속해서 확인할 수 있다.
특정 시간을 지정해 잡 실행을 종료하려면 .spec.activeDeadlineSeconds 필드에 시간에 해당하는 값을 설정한다. 지정된 시간에 해당 잡 실행을 강제로 끝내면서 모든 파드 실행도 종료한다. 시간을 지정해 잡 실행을 끝냈다면 잡의 상태를 확인했을 때 종료 이유가 reason:DeadlineExceeded로 표시된다.
잡 삭제는 사용자가 직접 delete job [job name] 으로 입력해야 한다. 이때 관련파드들도 같이 삭제된다.
잡 패턴
잡에서 파드를 병렬실행할 경우 파드 각각은 서로 통신하지 않는다. 각 파드는 독립적 동작이 전제이기 때문이다. 메일을 발송하거나 파일을 변환하는 등의 작업은 분산작업이라 한꺼번에 실행해야 해서 제대로 동작하지 않을 것이다.
잡의 일반적 사용 패턴을 소개하겠다.
-
작업마다 잡을 하나씩 생성하는것보다 모든 작업을 관리하는 잡 하나를 사용하는것이 좋다. 잡은 생성시 오버헤드가 크기 때문이다.
-
작업 개수만큼 파드를 생성하는것보다 파드 하나가 여러개의 작업을 처리하는 것이 좋다. 파드를 생성하는 오버헤드도 크므로 작업이 많아질수록 파드하나가 여러개 작업을 처리하는 것이 유리하다
-
워크 큐를 사용한다믄 카프카난 RabbitMQ 같은 큐 서비스로 워크큐를 구현하도록 기존 프로그램이나 컨테이너를 수정해야 한다. 워크 큐를 사용하지 않으면 그냥 기본 설정 그대로 컨테이너를 사용하므로 비효율적이다.
크론잡
Cronjob은 job을 시간 기준으로 관리하도록 생성한다. 지정한 시간에 한번만 잡 실행 / 지정 시간동안 주기적으로 잡을 반복 실행할 수 있다. 시간 지정시에는 리눅스나 유닉스의 cron 명령어에서 사용하는 옵션형식을 그대로 사용한다. 잡 실행 후에는 잡과 마찬가지로 동작한다.
크론잡 사용
cronjob.yaml 탬플릿이다.
apiVersion: batch/v1beta1
kind: CronJob
metadata:
name: hello
spec:
schedule: "*/1 * * * *" ---------------- 1
jobTemplate:
spec:
template:
spec:
containers:
- name: hello
image: busybox ---------------- 2
args: -------------------------3
- /bin/sh
- -c
- date; echo Hello from the Kubernetes cluster -- 3
restartPolicy: OnFailure-
크론잡의 핵심 스케줄 지정 필드이다. 일반적 cron 명령을 설정할 때와 같은 형식이다. 매 1분마다 실행하도록 하는 의미이다.
-
어떤 작업을 실행할 지에 대한 필드이다. busybox 컨테이넝 ㅣ미지를 사용하도록 설정한다.
-
해당 필드에는 셸 스크립트로 간단한 환영 메세지를 출력하도록 했다.
탬플릿 대신 kubectl create cronjob 명령으로 크론잡을 사용하도록 할 수 있으나 복잡하니 탬플릿 사용을 권장한다.
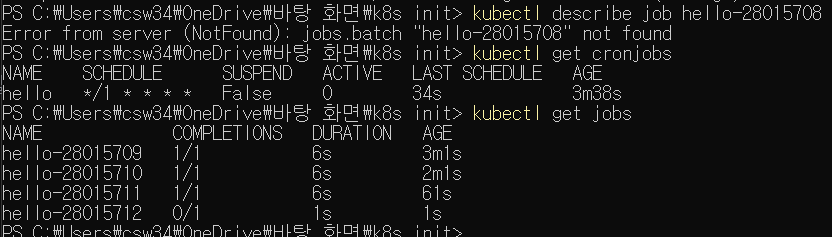
크론잡의 스케줄 설정 확인 및 실행한 잡을 확인해본 것이다. 이건 또 정상적으로 작동한다. 왜지?

크론잡 설정
.spec.startingDeadlineSeconds 필드
지정된 시간에 크론잡이 실행되지 못했을 때 필드값으로, 설정한 시간까지 지나면 크론잡이 그냥 실행되지 않게 한다. 이 필드값을 설정하지 않으면 실행 시간이 좀 지나도 제약없이 잡이 실행된다.
.spec concurrencyPolicy
크론잡이 실행하는 잡의 동시성을 관리한다. 기본값은 Allow이고 크론잡이 여러개 잡을 동시실행할 수 있도록 한다. Frobid로 설정하면 동시실행하지 못하게 한다.
ex) 만약 이전 실행 잡이 아직 정상종료되지 않았고, 실행중인 상태에서 새로운 잡을 실행해야 할 시간이다. 이때 크론잡은 해당 시간에 새로운 잡을 실행시키지 않고 다음 지정된 시간에 잡을 실행시킨다. Replace로 설정하면 이전에 실행했던 잡으 실행중인 상태에서 새로운 잡을 실행할 시간일 때 이전에 실행 중이던 잡을 새로운 잡으로 대체한다.
위 두 필드의 사용예시를 확인해보자. 다음 템플릿을 이용한다.
cronjob-concurrency.yaml
apiVersion: batch/v1beta1
kind: CronJob
metadata:
name: hello-concurrency
spec:
schedule: "*/1 * * * *"
startingDeadlineSeconds: 600 --------------- 1
concurrencyPolicy: Forbid --------------- 2
jobTemplate:
spec:
template:
spec:
containers:
- name: hello
image: busybox
args:
- /bin/sh
- -c
- date; echo Hello from the Kubernetes cluster; sleep 6000 -- 3
restartPolicy: OnFailure- 테스트 가능하도록 600초로 설정하였다.
- 우선 Forbid로 설정하여 동시실행을 막았다.
- 컨테이너에서 실행하도록 명령한 값을 6000초 동안 대기하도록 하였다. 100분동안 끝나지 않고 대기하게 만드는 것이다.
스케줄 필드 값으로 1분 간격마다 잡을 실행하도록 하였는데, 처음 실행한 잡이 종료되지 않고 6000초 동안 대기하므로 다음 잡을 실행하려 할때 기존 잡이 남아있는 상황이 만들어질 것이다. 이때 concurrencyPolicy 필드가 Forbid이므로 처음 실행했던 작업의 종료를 기다리게 될 것이다.
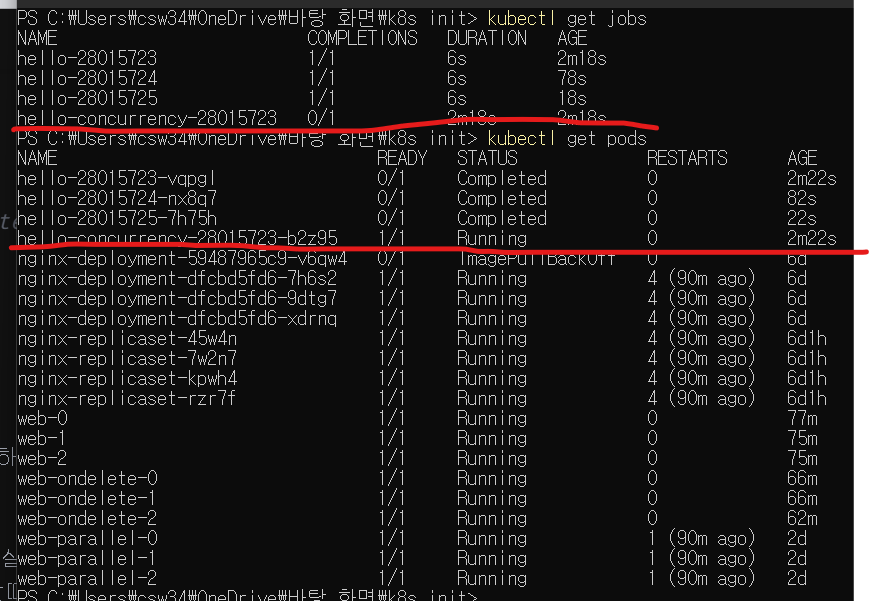
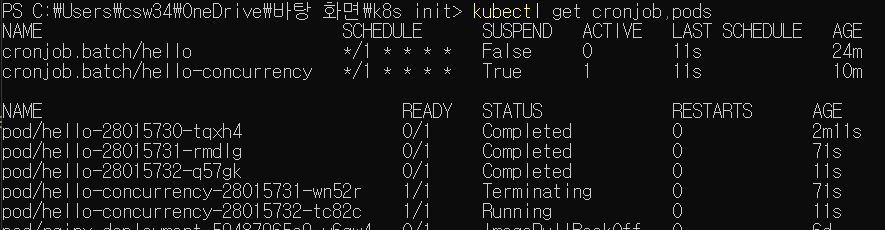
concurrency 관련 파드가 하나뿐인걸 확인 가능하다.
이때 대기중 작업을 실행하도록 concurrencyPolicy 필드값을 Allow로 바꿔보자. edit 명령을 사용하자.
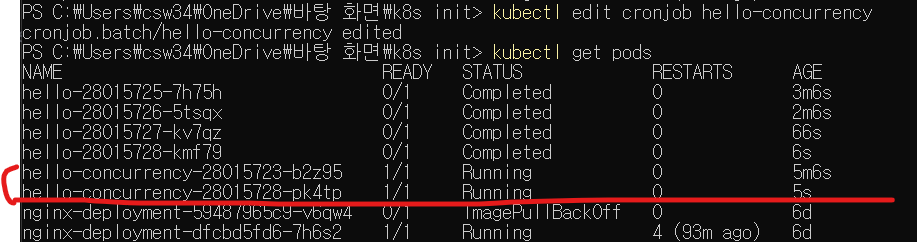
보는것과 같이 새로운 파드가 실행되었다.
지정된 시간 1분마다 새 파드가 하나씩 추가실행되고, 기존 잡은 아직 대기중이므로 종료되지 않고 계속 남아있다.
이번엔 concurrencyPolicy를 Replace로 바꿔보자.
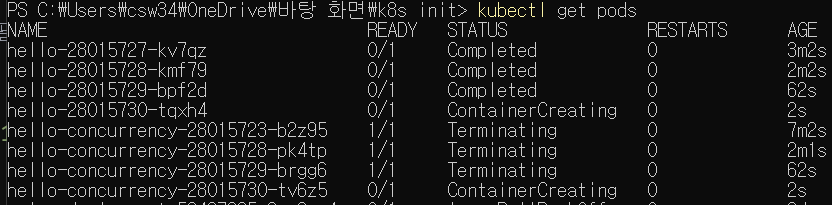
1분이 지나 새로이 잡이 실행되니까, 기존에 대기하던 잡이 모두 Terminating 상태가 되었다. 기존 잡을 모두 종료시키는 것이다.
- .spec.suspend 필드를 true(기본은 false) 로 설정하면 더이상 크론잡이 실행되지 않고 멈춘다. 기존의 잡은 멈추지는 않는다.
.spec.successfulJobsHistoryLimit
.spec.failedJobsHistoryLimit
잡의 정상적 실행종료/비정상 종료에 관한 내역을 저장하는 갯수를 설정한다. 성공종료는 기본값 3, 비정상 종료는 1이다.
처음 크론잡 예제로 설정한 hello 크론잡은 이 값이 기본값인 3이므로 잡 파드들이 3개만 남아있는걸 확인 가능하다.
