💻 폰켓몬 (level 1)
def solution(nums):
kind = set()
kind.add(nums[0])
limit = len(nums) * 0.5
for pkm in nums:
if(len(kind) == limit):
break
kind.add(pkm)
answer = len(kind)
return answer- set에 저장해서 자동으로 중복제거
- n/2개 담기위해서 limit 변수를 만들었다
🎯 모범답안
def solution(ls):
return min(len(ls)/2, len(set(ls)))- set을 활용하여 담을 수 있을만큼 담고 n/2 개 값과 최솟값 비교
💻 완주하지 못한 선수 (level 1)
def solution(participant, completion):
for i in completion:
if i in participant:
participant.remove(i)
return participant[0]-
완주자에서 하나씩 꺼내 참가자에 있는지 확인하고 있다면 제외해주는 방식
-
효율성에서 개털렸다 하나하나 다 확인했으니 당연한 결과
-
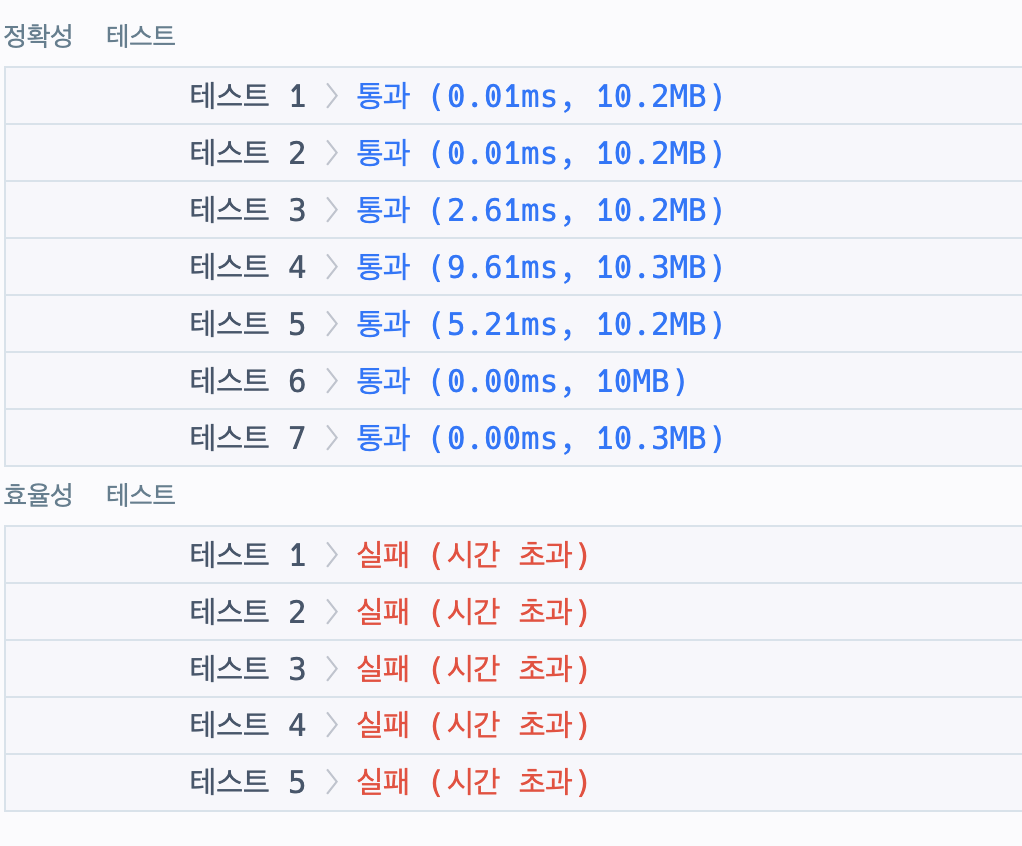
🎯 모범답안
def solution(participant, completion):
participant.sort()
completion.sort()
for p, c in zip(participant, completion):
if p != c:
return p
return participant.pop()- 탈락자는 한 명만 존재한다는 점을 인식하고 발견하자마자 return 하는 방식을 사용했어야 했다.
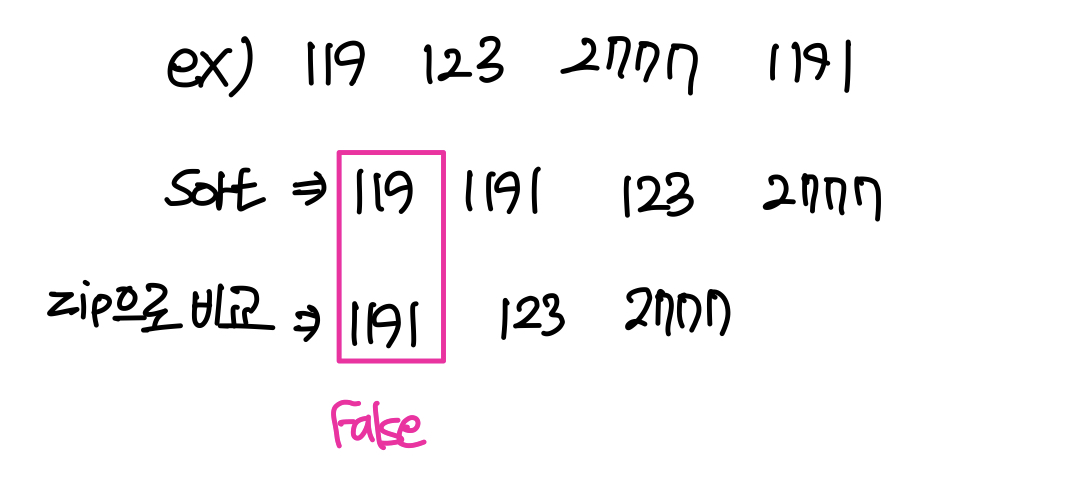
- zip()함수 까먹었을까봐 정리하자면
li1 = ['a','b','c','d','e']
li2 = ['b','c', 'e']
for i in zip(li1, li2):
print(i)
# 결과
# 인덱스끼리 매칭해주고 남은 것들(매칭이 안 된것들)은 버림
('a', 'b')
('b', 'c')
('c', 'e')💻 전화번호 목록 (level 2)
def solution(phone_book):
phone_book.sort(key=len)
for i in range(len(phone_book)):
for j in range(i+1, len(phone_book)):
if phone_book[i] in phone_book[j][:len(phone_book[i])]:
return False
return True- 길이순으로 정렬 -> 제일 짧은거부터 하나씩 접두어 여부 확인 -> 맞다면 바로 False return
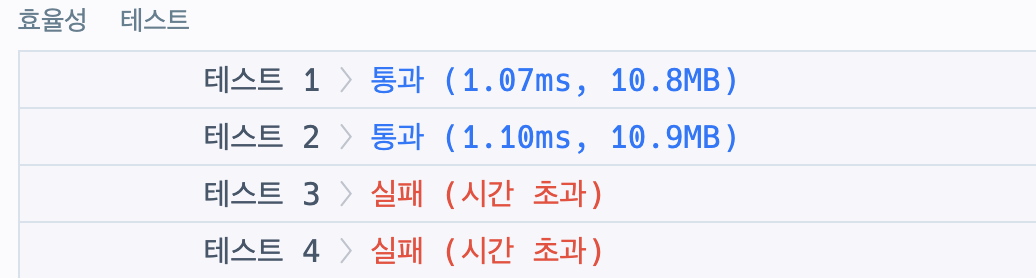
- 효율성이 진짜 사람 빡돌게 하는거 같다. 느낌상 True일 때 loop를 다 돌아서 그런거 같은데..
어떻게 고치냐 이걸
🎯 모범답안
def solution(phone_book):
phone_book.sort() # 문자열이니까 자릿수가 몇자리이든 앞 자리수 기준으로 정렬됨
for p1, p2 in zip(phone_book, phone_book[1:]):
if p2.startswith(p1):
return False
return True- 비교할때는 zip함수가 효율성 측면에서 국밥인거 같다
startswith()이라는 야무진 함수도 있다. 기억해두자- sort를 했기 때문에 한 번만 비교해도 되는 것이다 sort 안 하면 망함
🎯 모범답안 (Hash)
def solution(phone_book):
# 1. hash_map을 생성
hash_map = {}
for nums in phone_book:
hash_map[nums] = 1
# 2.접두어가 Hash map에 존재하는지 찾기
for nums in phone_book:
jda = ""
for num in nums:
print(num)
jda += num
if jda in hash_map and jda != nums:
return False
return True
- 그래도 해시 파트니까 이걸 활용해서 풀어야 겠다는 생각이 양심상 조금이나마 생겨서 공부함
hash_map = {}: 쉽게 생각하면 key값을 전화번호로 가지는 전화번호부, 여기서 value가 1인건 의미 없음- phone_book에 있는 전화번호 하나씩 가져와서 숫자 하나하나씩 추가하면서 hash_map에 있는 번호랑 접두어 여부 확인하기
jda != nums: 접두어가 자기 자신일 경우에는 제외하였다- 이렇게 하나하나 확인해도 hash라서 빠른거 같다.
💻 위장 (level 2)
def solution(clothes):
hash_map = {}
for clothe, type in clothes:
# type이란 키가 없으면 default값으로 0을 value로 주겠다.
hash_map[type] = hash_map.get(type, 0) + 1
answer = 1
# dict로 for문 돌리면 키값으로 순회한다
for type in hash_map:
answer *= (hash_map[type] + 1)
return answer - 1
[["yellow_hat", "headgear"], ["blue_sunglasses", "eyewear"], ["green_turban", "headgear"]]으로 볼 때
headgear : 2개, eyeware: 1개 이다.
headgear -> 첫 번째 headgear 착용, 두 번째 headgear착용, 아무것도 착용 x
eyeware -> 첫 번째 eyeware착용, 아무것도 착용x
이렇게 경우를 나눌 수 있고 총 경우의 수는 3*2 - 1 = 5개이다.
하나를 뺀 이유는 headgear, eyeware 모두 착용하지 않았을 경우이다.
hash_map.get(type, 0) + 1: get 메소드 사용 시 키값이 없다면 해당 키 값에 value로 기본값을 부여해줄 수 있다.answer *= (hash_map[type] + 1): value값에 + 1을 하는 이유는 해당 종류의 옷을 안 입는 경우의 수 까지 추가하기 위함
💻 베스트 앨범 (level 3)
def solution(genres, plays):
answer = []
dic1 = {} # 장르별로 음악 담기
dic2 = {} # 장르별 총 플레이 횟수를 저장
for i, (g, p) in enumerate(zip(genres, plays)):
if g not in dic1:
dic1[g] = [(i, p)] # value를 list형태로 저장 (key값을 고정시키기 위해)
else:
dic1[g].append((i, p))
if g not in dic2:
dic2[g] = p
else:
dic2[g] += p # 플레이 횟수 더하기
for (k, v) in sorted(dic2.items(), key=lambda x:x[1], reverse=True):
# dic1의[k] 즉, 장르에있는 value 이므로 list를 가져오되, 정렬 기준은 뒤에 있는 재생횟수
for (i, p) in sorted(dic1[k], key=lambda x:x[1], reverse=True)[:2]:
answer.append(i)
return answer-
enumerate: 인덱스와 원소로 만들어진 튜플을 만들어준다.for i, j in enumerate(['A', 'B', 'C']): print(i,j) # 결과 (0, A) (0, B) (0, C) # 만약 1부터 인덱스를 시작하고 싶다면 for i, j in enumerate(['A', 'B', 'C'], start=1): -
dic1과 dic2

-
for (k, v) in sorted(dic2.items(), key=lambda x:x[1], reverse=True): value값을 기준으로 내림차순 정렬 -
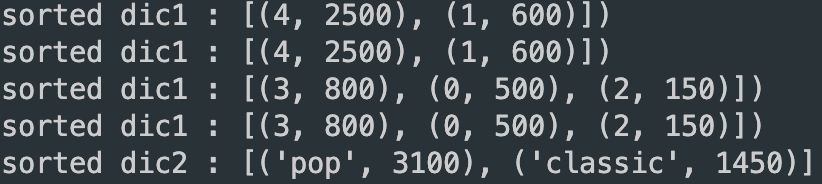
sorted 된 dic1과 dic2 (dic1은 for문을 도니까 여러개로 출력했음)
개어렵다