Key words
데이터 베이스, 관계형 데이터 베이스, MySQL, 스키마, ERD(Entity Relation Diagram), SQL(⭐)
1. 데이터 베이스란?
- 데이터 베이스란 '여러 사람이 공유하여 사용할 목적으로 체계화해 통합, 관리하는 데이터의 집합'이다.
- (데이터 베이스는 무엇이고 왜 필요한가?라는 질문을 들었을 때, 사실 너무 당연히 존재하는 것이라고 생각해와서, 선뜻 대답하기가 어려웠다.)
- 위 정의를 통해 DB의 필요성을 알 수 있다. DB외에 우리가 데이터를 다루는 케이스를 살펴보자.
In-Memory: 흔히 파이썬으로 우리가 어떤 코드를 짜서 데이터를 가공/저장한다고 해도, 그 프로그램을 종료하면 안에서 사용하던 것 모든 데이터는 '휘발'된다. (데이터가 프로그램에 의존한다는 말로 기억하면 더 쉬울 듯) 나 혼자 데이터를 한 두번 보고 말 것이 아니라면, 이 방식이 불편할 것은 직관적으로 알 수 있다.File I/O: 엑셀이나 CSV 파일을 읽어오는 일반적인 방식을 생각하면 된다. 파일을 켤 때마다 그 안의 데이터를 불러와야 하는데, 만약 2000만개의 데이터가 있는 엄청나게 무거운 파일이라면 매번 어떻게 불러올거야! 그리고 파일이 손상되기라도 하면 어쩔거야?! 불편해 불편해~
- 이런 의미에서 데이터 베이스의 필요성을 이해할 수 있는데, 그렇다고 데이터 베이스가 완전무결하다는 얘기로 생각하면 안된다! 각자의 상황에서 각자의 필요에 따라 장단점은 나뉘는 거다. 뭐든 극단적으로 생각하지 말자구~
DBMS(Database Management System)은 데이터 베이스에 접근하여 데이터 베이스를 조작, 제어하는 등 DB 관리를 지원하는 소프트웨어를 말한다.- 현업에서는 DB와 DBMS를 혼용하여 부르는 경우가 많다고 한다. 왜지..? DB는 정적 개념이고, 사람들이 주로 하는 management가 더 동적 개념이라 그런 것 같기도.
- MySQL이랑 SQL이랑 다른 건 줄 몰랐다ㅋㅋㅋㅋ
- MySQL은 데이터 베이스의 종류 중 하나이다. 다른 걸로는 Oracle 등이 있다.
- DB에서 데이터를 관리하기 위해서 SQL을 쓰는 것이다.
- (이건 기록 차 남겨두는데, ORM이라는게 있어서 파이썬 코드를 SQL로 자동 변환해주는 도구도 있나보다. 의존성을 경계하라고 하긴 했는데, 기억해뒀다가 나중에 꼭 필요하면 알아봐야지)
2. SQL, 스키마
- SQL = Structured Query Language이다. 여기서 쿼리는 '질의문'을 말한다. 우리가 구글에서 검색어 적고 엔터 누르는 것도 구글에 쿼리를 날리는 것이다. 이와 같이 SQL은 데이터 베이스에 쿼리를 날려서 내가 원하는 데이터만 가져올 수 있게 하는 언어라고 생각하면 될 것 같다.
- SQL 종류가 이렇게 많은지 몰랐네?!
- DDL: Create, drop
- DML: Insert, delete, update
- DCL: Grant, revoke
- DQL: select
- TCL: commit, rollback
- 내가 쓰는 쿼리문이 어떤 종류인지 대략 인지 정도만 하고 있으면 된다고 한다. 아직은 이 개념의 필요성을 못 느끼겠다. 나중에 느끼면 다시 찾아봐야겠다.
- 데이터 베이스의 스키마는 다음과 같이 생겼다.
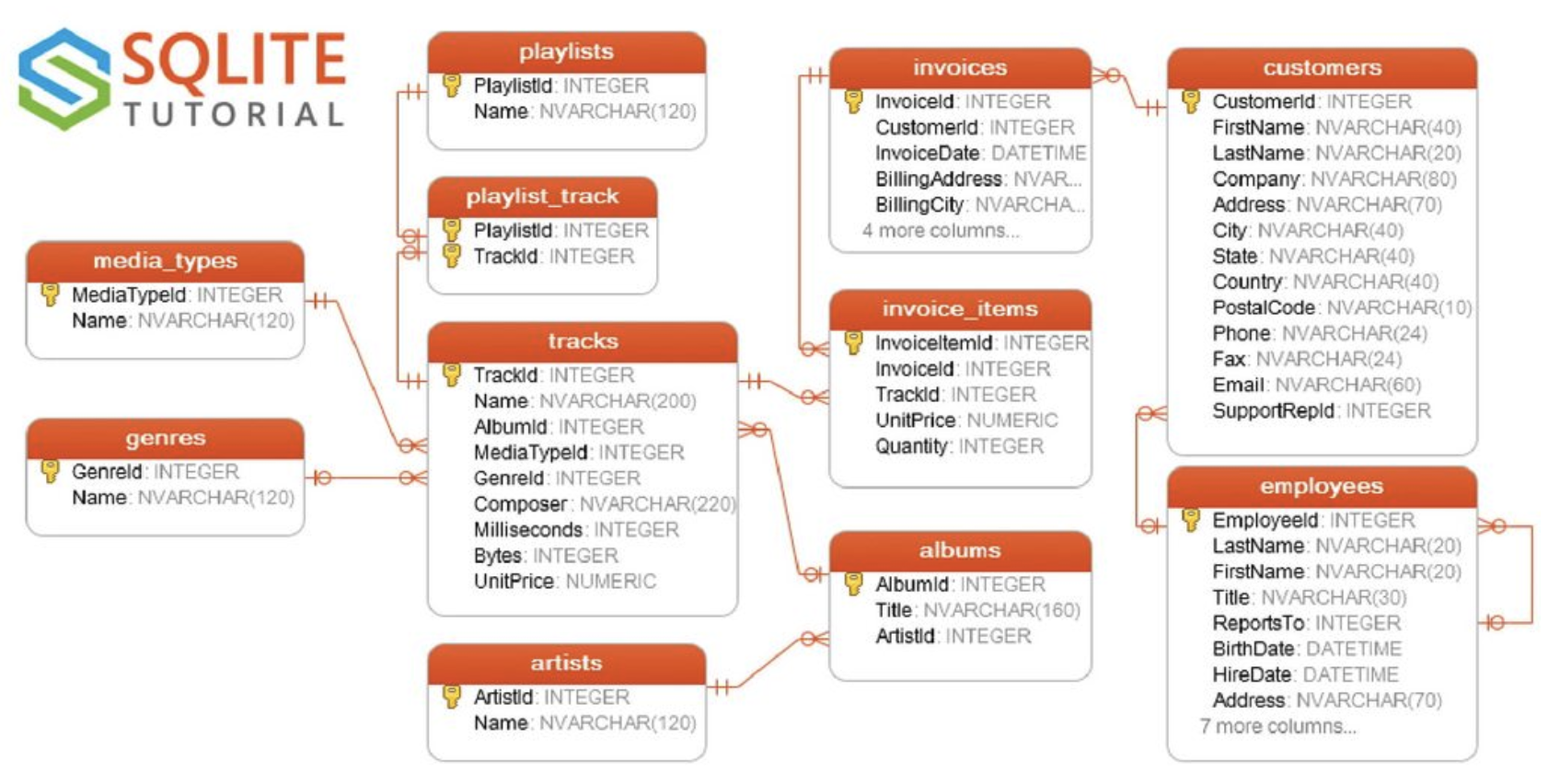
- '청사진'이라고 부를 수 있다고 하던데, 적절한 용어인 것 같다.
- 참고로 ERD는 이렇게 생긴 애다.
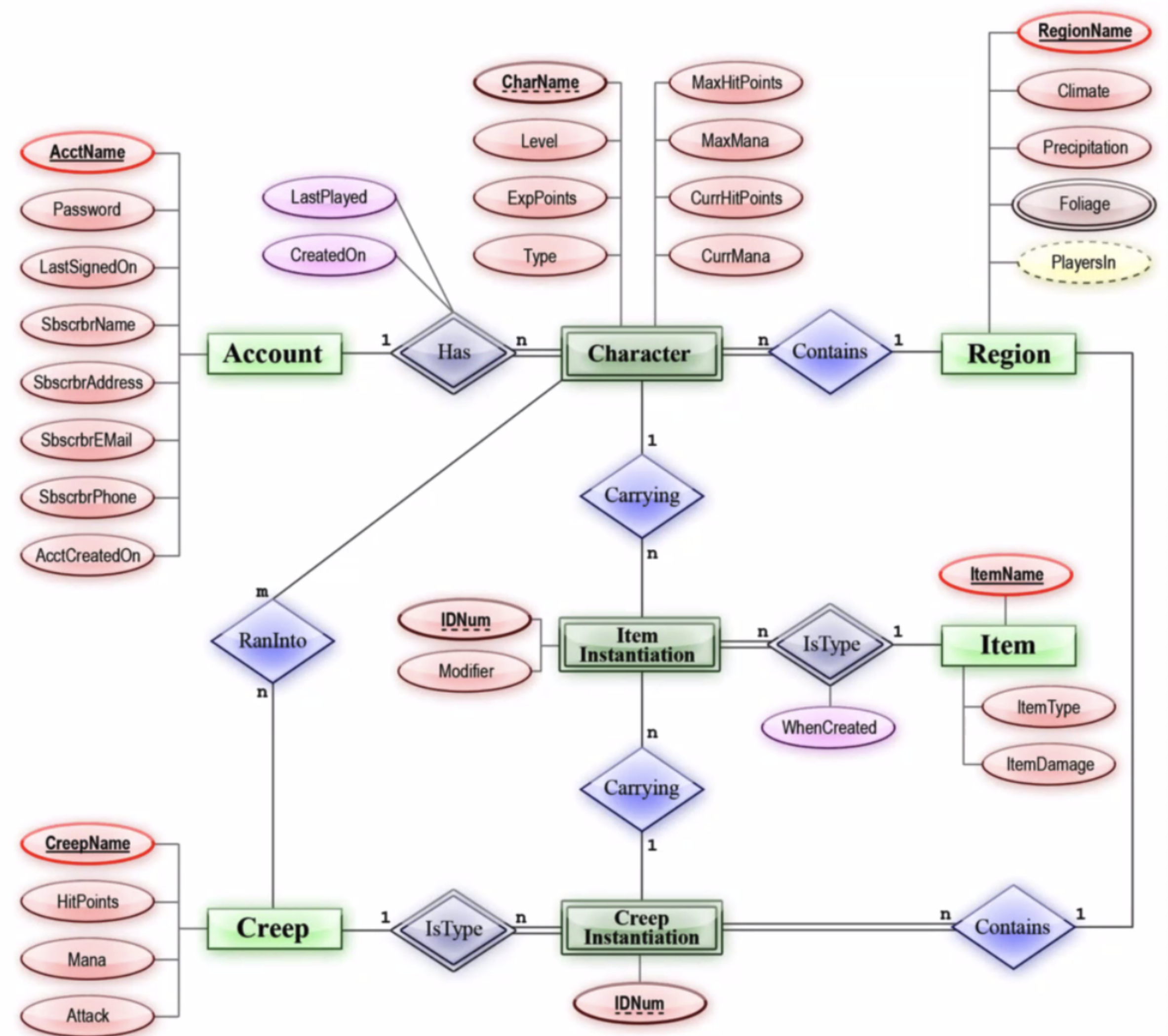
- 스키마와 ERD의 차이에 대해선 찾아보니 의견이 다양한 것 같고, 내 생각엔
설계도 = ERD, 구현 = 스키마정도로 생각해도 될 것 같다. ERD는 꼭 회사에서 업무 프로세스 플로우차트 만들던거랑 비슷하잖아. 그 비슷한 용도로 생각해도 충분할 듯. - 스키마 디자인에 대해서 설명과 예시를 들었는데, 결국 '효율성'을 향해 가기 위한 노력이 핵심이라고 생각하면 될 것 같다.
- SQL 기본 구문(Select, from ...)은 여기 굳이 적을 필요 없을 것 같아서 패스!
3. 데이터 베이스 설계
- 많이 들었지만 매번 새로운 데이터 베이스 디자인에 대한 얘기다. '데이터 베이스 설계'하니까 되게 거창한 것처럼 보이는데, 이번에는 관계형 베이스의 구조와 종류에 대해서만 배웠다.
- 이 용어는 이전에 DataFrame 등 배울 때랑 헷갈릴 수 있으니 기억하자.
테이블 == 관계(Relation) == 엔티티레코드 == 튜플 == 인스턴스 == ROW컬럼 == 속성(attribute) == 필드
- 관계형 데이터 베이스가 '관계형(Relation)'이라고 불리는 이유는 구조화된 데이터가 하나의 테이블로 표현되고, 테이블 간의 상호작용을 '관계'라고 하기 때문이라고 한다. 이렇게 문장으로 풀어말하니 더 어려운 것 같은데.. 그냥 위에 스키마 그림 생각하면 될 것 같다.
- 관계의 종류로는
1:1 관계, 1:N 관계, N:N관계 // Self referencing(테이블 자체의 관계)가 있다.- 오늘 들을 때 1:N, N:N이 헷갈렸다. 각각 담당 선생님과 class, 학생과 class의 관계로 기억하면 쉬울 것 같다.
5. 실습한 것
실습한 내용 중에 기억하고 싶은 것만 옮겨둔다. (참고로 오늘 실습은 DBeaver 통해 SQLite를 사용했다)
- Create table 오늘 처음 해봤다. PK 지정하는 거나, 대문자로 해야하나 같은게 헷갈렸다. 레퍼런스 찾아봐도 SQL 종류에 따라서 조금씩 다른 것 같고. 그냥 다 대문자로 적자!
CREATE TABLE Customer(
customer_id INTEGER NOT NULL,
customer_name VARCHAR(32) NOT NULL,
customer_age INTEGER,
PRIMARY KEY (customer_id)
);- Foreign Key 여러 개 지정하는 것도 헷갈렸었다. 걍 쓰면 된다!
CREATE TABLE Customer_Package(
cp_id INTEGER NOT NULL,
customer_id INTEGER,
package_id INTEGER,
PRIMARY KEY (cp_id),
FOREIGN KEY (customer_id) REFERENCES Customer (customer_id),
FOREIGN KEY (package_id) REFERENCES Package (package_id)
);각 장르 (genre) 마다 트랙을 구매한 고객의 id 의 수를 구해봅니다. (참고로 chinook DB 문제이다.)
- 고객의 수를 계산할 때 고객의 id (customer_id) 는 중복되지 않아야 합니다.
- 조회한 결과는 장르 이름이 표시되는 'genre_name' 칼럼과 구매한 고객수를 표시하는 'The_Number_of_customer_ID' 칼럼이 있어야 합니다.)
- 아~ 이 문제 재밌었다. 구조는 대충 아래와 같이 짰다.
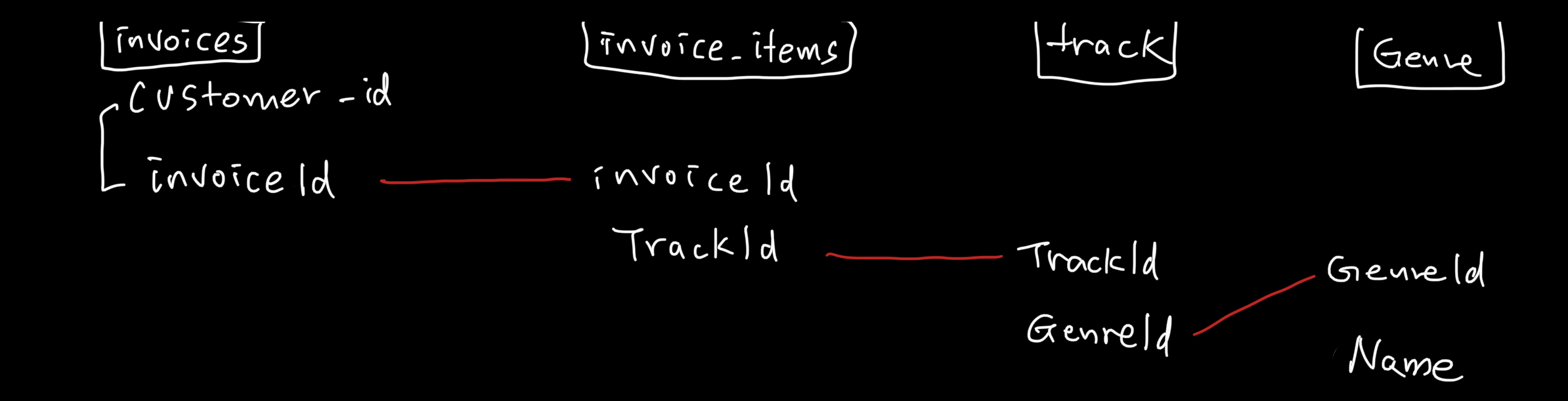 그리고 다음과 같이 코드를 짰다.
그리고 다음과 같이 코드를 짰다.
WITH AA AS(
SELECT TrackId, t.GenreId, g.Name FROM tracks t INNER JOIN genres g ON g.GenreId = t.GenreId),
BB AS(
SELECT ii.InvoiceId, ii.TrackId, AA.GenreId, AA.Name FROM AA INNER JOIN invoice_items ii ON ii.TrackId = AA.TrackId),
CC AS(
SELECT i.CustomerId, BB.Name, i.InvoiceId, BB.TrackId, BB.GenreId from BB INNER JOIN invoices i ON i.InvoiceId = BB.InvoiceId)
SELECT Name as 'genre_name', count(DISTINCT(CustomerId)) as 'The Number of customer_ID' FROM CC GROUP BY Name ;- 근데 다른 분 코드 보니 걍 연속해서 JOIN 해도 되긴 되더라! 여하간 with문에 꽂혀가지고 제대로 공부했다. 만족스러워~~
- 날짜 포맷 바꾸는거 구글링한 걸로도 잘 안되서 헤맸었다.
STRFTIME('%Y-%m-%d', i.invoice_date)이런 식으로 하면 되나보다. 난 안되서 다르게 했는데.. 암튼 이걸로 기억하자. Right JOIN이 SQLite에서 지원하지 않는다고 나와서 테이블 위치 바꿔서Left join으로 한 것도 기억에 남는다.FULL OUTER JOIN도 지원하지 않는다고 하던데, 찾아보니 이건UNION이용해서 두 개 합치는 방식으로 하는 것 같았다.
그 외
- 오늘 오랜만에 쿼리 적고 해보니, 쿼리 짤 때는 역시 머릿속으로 생각(구조화, 어떻게 할 것인지 등) 먼저!!! 쫘라락 해놓는게 굉장히 중요하다는 생각을 다시 한 번 했다. 관계형 데이터 베이스를 다룰 때 이 관계에 대해 생각 안하고 무작정 손가락부터 나가면 비효율적으로 고생할 가능성이 매우 높을 것 같다. 특히 쿼리문이 복잡해질수록 더더욱! 생각 먼저! 하자.
Feeling
- 난 SQL을 아예 처음 접하는 건 아니어서 오늘 내용 따라가는 것이나 과제하는 것도 어려움보단 재미가 훨씬 더 크긴 했는데, 오늘 SQL이란 걸 처음 보는 분들은 굉장히 답답하셨겠다는 생각을 많이 했다. 워낙 자기주도적 학습을 시키다보니 안 맞는 사람에겐 고역일 수 있겠다.
- 여튼 SQL 과제하는데 완전 초집중으로 엄청 재밌는 시간 보냈다. 짜릿해...ㅎㅎㅎㅎ
- 내일 쉬는 날이니까 내일은 오늘 받은 튜토리얼 사이트에서 쿼리문 이것저것 연습해봐야겠다.

B2B SaaS 회사에서 Data Analyst로 일하고 있습니다.