Key words
반복문, 조건문, 내장 메서드, 컬렉션 자료형, 프로그래밍
섹션5 컴퓨터 공학 기본의 첫 날이다.
오늘은 개념을 많이 배우기보단, 다양한 상황에 대해 파이썬으로 어떻게 코드를 짤 수 있는지 보고 직접 실습해보는 시간이 많았다.
1. 오늘 배운 주요 개념
이건 기억하면 좋을 듯
파이썬: 컴퓨터와의 소통언어알고리즘: 효율적인 문제해결방법 (단순한 사칙연산도 알고리즘이라고 볼 수 있다)자료구조: 프로그램의 구조와 크기 (문제 간의 관계, 난이도)
모듈/패키지/라이브러리/프레임워크
- 이것도 면접 때 물어보기 딱일 듯.
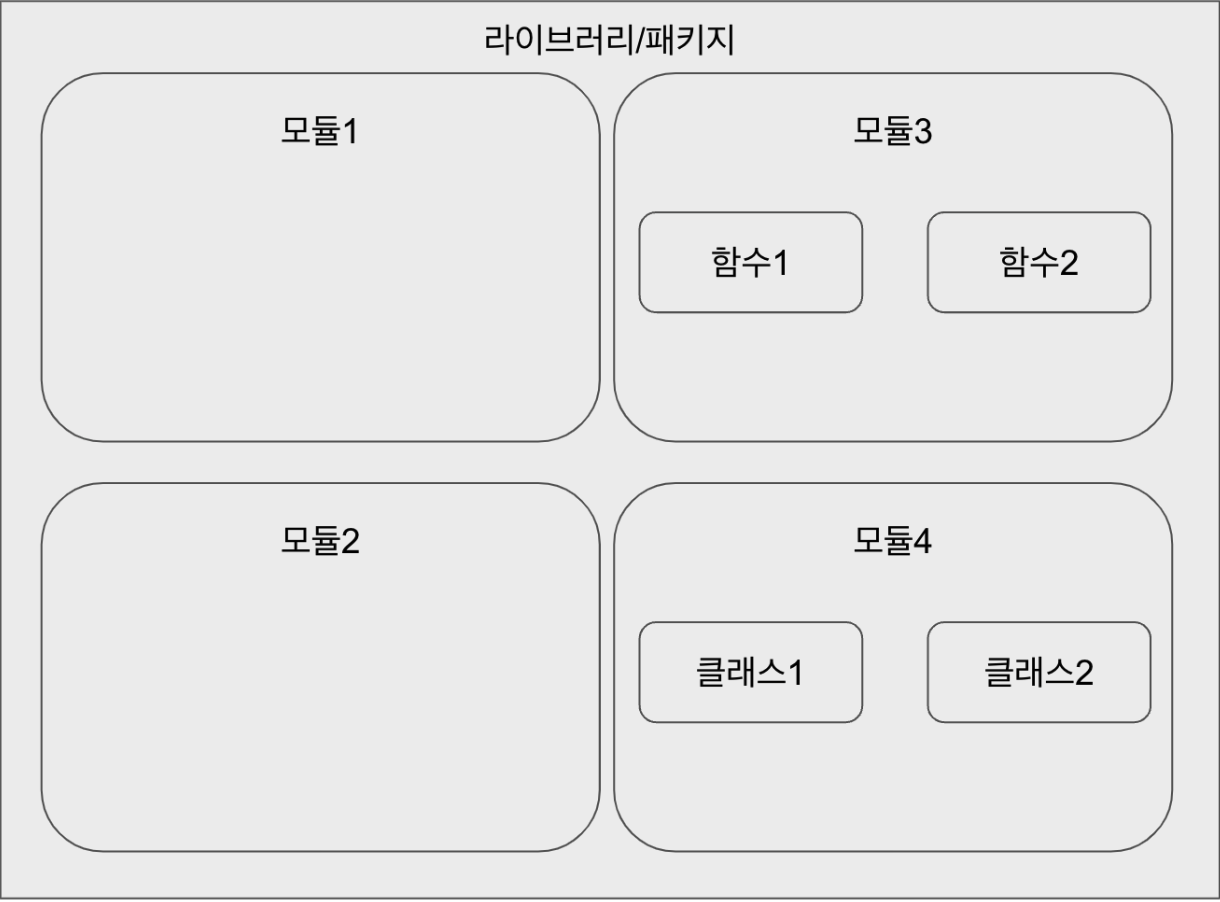
- 모듈은 확장자가
.py인 파이썬 파일을 생각하면 됨. - 파이썬 패키지는 이런 모듈(파이썬 파일)의 모음일 뿐이다.
- 라이브러리는 표준 라이브러리와 외부 라이브러리로 구분된다.
- 프레임워크는 파이썬 라이브러리의 모음이다.
- 이전에 썼던 django, flask도 프레임워크임.
- 모듈은 확장자가
- 코치님이 여러 번 강조했던 말이 있는데, 라이브러리/패키지 등의 개념이 명확하게 구분되어 있는건 아니고, 약간은 추상적인 의미로 쓰인다는 것이었다.
이제부터는 직접 실습해본 내용들 위주로 적어보겠다.
2. 정규표현식
- 일단 정규표현식하면 그 외국 짤부터 생각난다. 문제 하나를 풀려고 정규표현식을 쓰려고 했더니 문제가 두개가 되었다는..ㅎㅎㅎ
- 근데 오늘 몇 개 다뤄보니 잘 쓰면 크롤링할 때도, 자연어 처리를 위한 데이터 전처리할 때도 많은 도움이 되겠다 싶었다.
- 일단
메타 문자등 관련해서는 아래 사이트를 참고하면 된다. 정리 잘 되어있다. (소리질러, 갓 점투파!!!)
신기했던 건 re.search와 re.match의 차이다.
# 정규표현식 라이브러리
import re
wordlist = ["color", "colour", 'acolor', 'acoloraaa']
for word in wordlist:
if re.search('col.*r', word):
print(word) # => color, colour. acolor, acoloraaa- match는 첫 시작부분부터 일치해야하고, search는 꼭 처음이 아니어도 된다. 위처럼 메타문자 잘 이용하면 원하는 형태 잘 뽑아낼 수 있어 유용할 듯!
- 근데 이전부터 여러 번 들어온 것처럼 정규표현식은 지금 다 미리 공부할 필요는 없고 필요할 때 찾아가며 하면 될 것 같다.
re.compile 이용하면 원하는 형태로 된 부분만 뽑아올 수도 있다!
phone = re.compile("010-\d{4}-\d{4}")
info = ['홍길동 010-1234-1234', '고길동 010-5678-5679']
for text in info:
match_object = phone.search(text)
print(match_object.group())- 참고로
.group()을 안하면 결과가<re.Match object; span=(4, 17), match='010-1234-1234'>식으로만 나온다. - re 모듈의 함수들에 대해선 이 사이트를 참고하면 될 것 같다.
3. 그 외 사용해본 메서드들
raw string: escape문자를 문자 그대로 사용하고자 할 때 쓰는 것이다. 출력할 문자열 앞에r만 붙여주면 된다. 아마 윈도우는 파일 경로 딸 때 백슬래시를 쓰니까 더 잘 활용될 수도 있을 듯? 맥에서는 언제 쓰게될지 아직은 모르겠다.
print('raw string을 사용하지 않고고\b 문자 출력하기')
# raw string을 사용하지 않고 문자 출력하기
print(r'raw string을 사용하지 않지 않고고\b 문자 출력하기')
# raw string을 사용하지 않지 않고고\b 문자 출력하기아래 내용 공식문서
rjust(width, [fillchar]):- 원래 문자열 앞을 정해진 문자로 채워준다. width는 채워주고 난 후의 전체 len이다. 공식문서의 설명처럼 width가 이미 원래 문자열보다 같거나 작다면 원래 문자열을 그대로 리턴한다는 건 아래 두 번째 예시를 보면 알 수 있다.
# "00123" print("123".rjust(5,"0") # "50000" print("50000".rjust(5,"0"))zfill(width)- 이건 위랑 비슷한데
z인거 보면 0을 채워준다고 기억하면 될 듯.
- 이건 위랑 비슷한데
- 일반 문장도 인덱싱/슬라이싱 되는거 오래간만에 봐서 까먹고 있었네.
string_ = "Hello, I am Jack and I am a data scientist"
string_[0:2] #=> He
print(string_[0]) #=> H
# 참고로 startwith(), endswith()를 써서 boolean을 반환할 수도 있다.
string_.startswith('Hello') #=> Truecopy(),deepcopy()- 얕은 복사와 깊은 복사로 표현하던데, 깊은 복사는 내부 객체까지 완전 새롭게 카피하는 것이다. 그냥 같은 건데 다른 놈을 새로 만드는 거라고 생각하면 된다. (얕은 복사는 원본이 바뀌면 같이 바뀌지만 깊은 복사는 아예 다른 놈이라서 그렇지 않음)
- 반복문, 조건문 부분은 많이 다뤄보고 있으니 해본 것들을 여기 옮기진 않겠다.
append(),extend(),insert()의 차이에 대해서는 아래 실습과제 할 때 정리해두었으니 참고하자.enumerate()신기했던 것. 지난 섹션인가 써봐서 알았던 건데 오늘 퀴즈 나왔을 때 까먹었어!!
# 특정 문자열이 있는 index 뽑기
def index_collection(list, str):
res = []
for i, c in enumerate(list):
if c == str:
res.append(i)
return res
my_list = ['xyz', 'XYZ', 'abc', 'ABC', 'xyz']
index_collection(my_list, 'xyz') # => [0, 4]del,remove,pop: 참고- list.index vs list.count
sort,sorted: 공식문서, sort는 오늘 실습 과제에서도 써봤다.- lambda도 다루어보았다.
4. 실습 과제
오늘 과제 난이도는 평이했다. 다 제출하고 나서 다른 동기들 코드 보며 어떻게 더 아름답게 코드를 짤 수 있는지 살펴보는 맛이 있었다.
[part1]
'1부터 101 사이에 있는 모든 제곱수'를 하나의 리스트로 반환하는 코드를 작성해주세요.
제곱수 : 1, 4, 9, 16,...,81, 100
아래 예시입력값과 출력값을 참조하며 문제를 해결해봅니다.
입력값:
없음
출력값:
[1, 4, 9, 16, 25, 36, 49, 64, 81, 100]def part1():
res = [] # 결과가 저장될 리스트
for i in range(1,11):
x = i ** 2
res.append(x)
return res
'''
[기록] - append(), extend(), insert()
공식문서: https://docs.python.org/ko/3/tutorial/datastructures.html
- append(): 리스트의 끝에 항목 더함.
- extend(): 리스트의 끝에 이터러블의 모든 항목을 덧붙여서 확장.
ex) ['a', 'b', 'c']를 어떤 리스트에 extend하면 'a', 'b', 'c'가 해당 리스트에 원소로 들어감.
[['a', 'b', 'c']]의 경우라면 ['a', 'b', 'c']이 해당 리스트에 원소로 들어감.
'abc'의 경우라면 'a', 'b', 'c'가 원소로 들어감.
reference: https://m.blog.naver.com/wideeyed/221541104629
'iterable하다'란?
- '반복 가능한 객체이다' => list, dict, set, str, tuple ...
- 쉽게 생각하면 for loop에서 'in' 뒤에 들어갈 수 있는 것들이라고 생각해도 될듯.
reference: https://wikidocs.net/16068
- insert(i, x): 원하는 위치 i에 x를 더함.
ex) a.append(0, x)는 a 리스트 첫 위치에 x를 넣는다는 뜻.
그래서 a.insert(len(a), x) = a.append(x)와 동등하다고 하는 것. (len(a)는 항상 전체 크기를 나타내므로)
'''- 동기 코드 중 제곱을
import math를 해서math.pow(i,2)처럼 하는 것도 보았다.
[part2 - 람다 쓰기]
문제 1.
매개변수로 들어온 리스트 요소들의 제곱수를 가지고 있는 리스트를 반환해주세요.
단 매개변수로 들어오는 리스트는 1이상의 자연수로만 구성되어있습니다.
람다키워드를 함수 내부에서 사용해야 합니다.
*예시 1*
입력값:
[1, 2, 3, 4, 5]
출력값:
[1, 4, 9, 16, 25]
*예시 2*
입력값:
[2, 4, 6, 8, 10, 12]
출력값:
[4, 16, 36, 64, 100, 144]
문제 2.
매개변수로 들어온 리스트 요소들이 홀수인지 짝수인지 리스트를 통해 반환해주세요.
(반환되는 리스트 내부에는 '홀수', '짝수'만 있어야합니다.)
단 매개변수로 들어오는 리스트는 1이상의 자연수로만 구성되어있습니다.
람다키워드를 함수 내부에서 사용해야 합니다.
*예시 1*
입력값:
[1, 4, 9, 16, 25]
출력값:
['홀수', '짝수', '홀수', '짝수', '홀수']
*예시 2*
입력값:
[2, 3, 6, 7, 10, 12]
출력값:
['짝수', '홀수', '짝수', '홀수', '짝수', '짝수']def part2_is_square_num(a):
res = list(map(lambda x: x **2, a))
return res
'''
[기록]
- map(함수, 리스트): 리스트로부터 원소를 하나씩 꺼내서 함수를 적용시킨 다음 그 결과를 새로운 리스트에 담아준다.
- filter(함수, 리스트): 리스트에 있는 원소들에 함수를 적용시켜서 참인 값들로 새로운 리스트를 만들어줌.
ex) list(filter(lambda x: x < 5, range(10))) # => [0, 1, 2, 3, 4]
reference : https://wikidocs.net/64
'''
def part2_is_odd_num(a):
res = list(map(lambda x: '짝수' if x % 2 == 0 else '홀수', a))
return res
# 람다 내 if 문 쓰는 법 기억하기. - for문을 쓰면 리스트를 새로 만들어 할당해주는 식으로 코드가 늘어났는데 람다를 쓰니 알아서 리스트도 만들어주고 코드 줄일 때 좋겠다는 생각을 했다.
- 이전에 데이터프레임에서 apply 함수 내에 람다 쓰는 것만 해봤는데, 아예 이런식으로 함수를 대체할 수 있다는 점이 신기했다.
[part3]
자유롭게 문자를 입력받아 알파벳순서대로(A~Z, a~z) 정렬하세요.
문자를 정렬하기 위한 값의 비교는 아스키코드의 십진법을 기준으로 합니다.
중복되는 문자열을 처리해줄 수 있도록 기능을 구현해주세요.
영어 소문자와 대문자에 대해서만 정렬을 진행하도록 합니다.
아래 예시입력값과 출력값을 참조하며 문제를 해결해봅니다.
*예시 1*
입력값:
'a T C'
출력값:
'C T a'
*예시 2*
입력값:
'z X y D c A b U'
출력값:
'A D U X b c y z'def part3(s):
s = set(s.split(" ")) # 입력 문자열을 나누고 set 자료형을 이용하여 중복 제거
s = list(s) # sorting을 위해 리스트로 변환
s.sort() # sorting. (파이썬에선 문자를 아스키 코드에 대응하여 숫자로 보고 정렬해줌)
s = " ".join(s) # 아웃풋 조건에 맞춰 다시 문자열로 변경
return s
# 근데 문제에 나온 말처럼 영문 외에는 정렬이 아예 안되도록까지 처리를 해줘야 하는건가? 일단 그렇겐 안 함.
'''
[기록]
- 아스키 코드: 영문 알파벳을 사용하는 대표벅인 문자 인코딩. 대부분의 문자 인코딩이 아스키에 기초를 두고 있다.
referecne : https://ddolcat.tistory.com/684 // https://blockdmask.tistory.com/564
'''- 참고로 split을 하면 리스트형태로 나오긴 하는데 type을 보면
Nonetype이었다. 참고참고~
[part4]
Part 3의 요구사항은 기본적으로 충족하고, 추가적인 예외사항을 해결해주세요.
다양한 내장함수를 활용해봅니다.
중복되는 문자열을 처리해줄 수 있도록 기능을 구현해주세요.
소문자는 대문자로, 대문자는 소문자로 변경해주세요.
아래 예시입력값과 출력값을 참조하며 문제를 해결해봅니다.
*예시 1*
입력값:
'c t A'
출력값:
'a C T'
*예시 2*
입력값:
'z X y W v U t S'
출력값:
's u w x T V Y Z'def part4(s):
s = set(s.split(" ")) # 입력 문자열을 나누고 set 자료형을 이용하여 중복 제거
s = list(s) # 대소문자 변경 및 sorting을 위해 리스트로 변환
res_lower = [] # 소문자 저장할 리스트
res_upper = [] # 대문자 저장할 리스트
for i in s:
if i.islower():
i = i.upper() # 뽑은 문자열이 소문자면 대문자로 바꿔라.
res_upper.append(i)
else:
i = i.lower()
res_lower.append(i)
res_upper.sort()
res_lower.sort() # sorting.
res_total = res_lower + res_upper
res_total = " ".join(res_total) # 아웃풋 조건에 맞춰 다시 문자열로 변경
return res_total
'''
[기록] - 왜 대문자, 소문자 담을 리스트를 따로 만들어서 합쳐줬나?
- sorting 할 때 sort(reverse = True)를 하면 소문자 > 대문자 순으로는 소팅할 수 있지만 abc 순 정렬도 반대가 되어버림.
- 즉, abcAbc 정렬 순서는 그대로 두되 소문자가 먼저 나오고 대문자가 이어지도록 하는 함수를 못 찾겠어서 별도로 함.
=> swapcase()라는 내장함수가 있었네!
'''- 이건 주석에 적어둔 것처럼 소문자 대문자를 서로 변경하는 내장함수를 못 찾아서 별도로 했던건데, 나처럼 복잡하게 할 거 없이 그냥 part3처럼 sorting 그대로 하고 마지막에
swapcase()만 해주면 코드가 훨씬 더 간결해질 수 있었다. - 컴퓨팅 사고 잘 기억하자!
Feeling
- 새로운 섹션에 들어오면 오전은 늘 약간은 혼란스럽다. 강의 영상/자료의 스타일, 과제 제출 방법, 코치님의 성향 등이 섹션마다 다 다르기 때문이다. 섹션3 이후로 오랜만에 Pytest로 과제 제출하는데 헷갈려서 다시 찾아보기도 했다.
- 파이썬 코드를 짜보며 느낀 건, 역시 나는 코드를 짤 때 기분이 좋구나~ 라는 것이다. 문제가 주어지면 나름 논리적 사고를 통해 어떻게 구성할지 머리로 생각하고 손으로 구현하는 재미가 있다. 내가 아직 진짜 어려운 코딩을 안 해봤기 때문에 그런 걸지도..ㅎ
- 이번 달 말에 있을 회사 지원 준비 생각에 마음이 싱숭생숭 혼란스럽긴 하지만 그래도 이번 섹션 잘 보내보자! 파이썬 제대로 써먹어볼 수 있을 것 같아 기대가 많이 된다ㅎㅎ

B2B SaaS 회사에서 Data Analyst로 일하고 있습니다.