Keyword
인스타그램, 스크레이핑, 파이썬 인스타그램 스크래이핑, selenium
한 것
인스타그램 게시물 스크레이핑하는 코드 짜는 걸 어제에 이어 했다.
- 코멘트 가져오는게 생각보다 잘 안되서 많이 해맸다. css selector를 이리저리 바꿔봐도 안되었는데, 문제는 생각보다 간단했다.
driver.find_elements(By.CLASS_NAME,comment_ids_objects_css)로 하니 잘 되었다. 원래 참조한 코드는element로 되어있었는데 이걸elements로 안 바꾼 거였다;; VSC에서.text가 제대로된 코드 표시가 안된 힌트가 있었는데도 단순히 css selector를 잘못 골랐다고 결론 내리고 거기서만 헤맨거였다. - 여하튼 인스타그램 코멘트 영역 selector 찾을 때 공통된 영역이 뭐가 있는건가 찾기 어려웠는데, 아래 이미지와 같이 class name이 공통된 규칙을 찾았고, 코멘트 부분은
find_elements(By.CSS_SELECTOR..)가 아니라 클래스 네임으로 했다. css selector로 하기엔 댓글마다 고유한 넘버가 매겨져 있어서 더 어려운 것 같았다.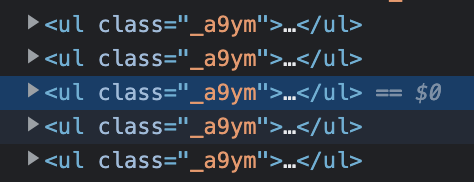
- 댓글에서 아쉬운 점은 id만 따로 빼는 걸 못했다는 거다. class name
_a9ym하위로 접근하여 공통된 요소를 바로 찾지 못했다. 그래서, 개인정보가 들어가 있어서 여기에 캡쳐 이미지를 넣지는 못하지만, 결국 코멘트 통채로 긁어오는 방식을 택했다. 통채로 가져오면 어차피 id가 맨 앞에 들어가 있기도 하고, 의뢰자가 id는 있으면 좋지만 어렵다면 그냥 내용만 해도 된다고 하기도 했다. 어차피 직접 댓글 내용을 보며 참고할 것이기 때문에 큰 상관은 없을 것 같다고 생각했다. - json 데이터를 그냥 dump하니까 csv파일로 저장할 때 깨지는 현상이 있어서
comment_json = json.dumps(comment_data, ensure_ascii=False)와 같이 ascii 파라미터를 조정해주니 잘 됐다. - 그럼에도 코멘트가 csv파일에서 사람이 직접 보기엔 정리가 너무 안되어있기도 했고, 또 직접 해당 게시물을 봐야할 상황이 있을 것 같기도 해서
link = driver.current_url를 이용해서 해당 게시물의 링크도 파일 내용에 추가시켰다. - 아래는 내가 오늘까지 작성한 코드 전부다. 많은 시간을 들인 것도 아니고 오늘 안에 여하튼 끝내야만 해서 급하게 해 허접하긴 하지만,, 그래도 누군가에겐 도움이 되길 바란다. (인스타는 html 코드가 자주 바뀐다고 하니 시간이 지나면 다시 직접 수정해야할거다.)(참고로 저는 맥북을 씁니다!!)
#---main code for scraping---#
from selenium import webdriver as wd
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import time
import json
import pandas as pd
#---원하는 인스타그램 계정 URL과 추출하고 싶은 게시물 수를 입력하세요---#
search_account_url = '링크'
wish_num = 3
user_id="아이디", # 인스타그램 아이디를 입력하세요.
user_passwd="비밀번호" # 인스타그램 패스워드를 입력하세요.
save_file_name="instagram_extract_test" # 저장할 파일명을 입력하세요.
#-----------------------------------------#
# 크롬 드라이버 경로
driver_path = "크롬드라이버 저장 경로"
driver = wd.Chrome(driver_path)
# 인스타그램 Login 기본 정보
login_option="instagram" # 수정 X
instagram_id_name="username" # 수정 X
instagram_pw_name="password" # 수정 X
instagram_login_btn=".sqdOP.L3NKy.y3zKF " # 수정 X
# login 시도
print(f"login start - option {login_option}")
login_url = "https://www.instagram.com/accounts/login/"
driver.get(login_url)
time.sleep(7)
try:
instagram_id_form = driver.find_element(By.NAME, instagram_id_name)
instagram_id_form.send_keys(user_id)
time.sleep(7)
instagram_pw_form = driver.find_element(By.NAME, instagram_pw_name)
instagram_pw_form.send_keys(user_passwd)
time.sleep(7)
login_ok_button = driver.find_element(By.CSS_SELECTOR, instagram_login_btn)
login_ok_button.click()
is_login_success = True
except:
print("instagram login fail")
is_login_success = False
time.sleep(7)
# 원하는 계정의 메인 페이지로 이동.
driver.get(search_account_url)
time.sleep(7)
# 첫번째 게시물 클릭
first_img_css="div > div:nth-child(1) > div:nth-child(1) > a > div._aagu > div._aagw"
driver.find_element(By.CSS_SELECTOR, first_img_css).click()
#-----------------------------------------#
# data 저장할 list 생성
upload_ids = []
date_texts = []
date_times = []
date_titles = []
main_texts = []
thumbs_up_counts = []
comments = []
comment_counts = []
links = []
check_arrow = True # 다음 게시물 넘어가는 버튼이 있는가?
count_extract = 0 # 현재 몇 개의 게시물이 추출되었나?
print_flag=True # True로 할시 추출되는 정보를 실시간으로 표시해줌.
# CSS Info.
upload_id_object_css="div._aar0._ad95._aar1 > div.alzwoclg > div > div > div > span > a"
date_object_css="div._ae5u._ae5v._ae5w > div > div > a > div > time"
main_text_object_css="div._ae5q._ae5r._ae5s > ul > div > li > div > div > div._a9zr > div._a9zs > span"
thumbsup_css="section._ae5m._ae5n._ae5o > div > div > div > a > div > span"
comment_more_btn="div._ae5q._ae5r._ae5s > ul > li > div > button > div > svg"
#comment_ids_objects_css="_a9ym" # 못 찾겠다..
comment_texts_objects_css="_a9ym"
next_arrow_btn_css1=" div:nth-child(1) > div > div > div._aaqg._aaqh > button"
next_arrow_btn_css2=" div:nth-child(1) > div > div > div._aaqg._aaqh > button"
# 작업 수행
while True:
if count_extract > wish_num:
break
time.sleep(7)
if check_arrow == False:
break
# 작성자 ID
try:
upload_id_object = driver.find_element(By.CSS_SELECTOR, upload_id_object_css)
upload_id = upload_id_object.text
except:
upload_id = None
# 게시 날짜
try:
date_object = driver.find_element(By.CSS_SELECTOR,date_object_css)
date_text = date_object.text
date_time = date_object.get_attribute("datetime")
date_title = date_object.get_attribute("title")
except:
date_text = None
date_time = None
date_title = None
# 본문 내용
try:
main_text_object = driver.find_element(By.CSS_SELECTOR,main_text_object_css)
main_text = main_text_object.text
except:
main_text = None
# 좋아요 수
try:
thumbs_up_object = driver.find_element(By.CSS_SELECTOR,thumbsup_css)
thumbs_up_count = thumbs_up_object.text
except:
thumbs_up_count = None
# 댓글
## 더보기 버튼 클릭
try:
while True:
try:
more_btn = driver.find_element(By.CSS_SELECTOR,comment_more_btn)
more_btn.click()
time.sleep(1)
except:
break
except:
print("----------------------fail to click more btn----------------------------------")
continue
## 댓글 데이터
try:
comment_data = {}
comment_ids_objects = driver.find_elements(By.CLASS_NAME,comment_ids_objects_css)
comment_texts_objects = driver.find_elements(By.CLASS_NAME,comment_texts_objects_css)
try:
for i in range(len(comment_ids_objects)):
comment_data[str((i+1))] = {"comment text":comment_texts_objects[i].text} #"comment_id": comment_ids_objects[i].text,
except:
print('---fail---')
except Exception as E:
print(E)
#comment_id = None
comment_text = None
comment_data = {}
# 게시물 링크
try:
link = driver.current_url
except:
link = None
upload_ids.append(upload_id)
date_texts.append(date_text)
date_times.append(date_time)
date_titles.append(date_title)
main_texts.append(main_text)
thumbs_up_counts.append(thumbs_up_count)
try:
comment_json = json.dumps(comment_data, ensure_ascii=False)
except Exception as E:
print(E)
comments.append(comment_json)
comment_counts.append(len(comment_data))
links.append(link)
if print_flag:
print("upload id : ", upload_id)
print("date : {} {} {}".format(date_text, date_time, date_title))
print("main : ", main_text)
print("thumbs up :", thumbs_up_count)
print("comments counts", len(comment_data) )
print("comment : ", comment_data)
print("post link : ", link)
print("====================================")
try:
WebDriverWait(driver, 100).until(EC.presence_of_element_located((By.CSS_SELECTOR, next_arrow_btn_css1)))
driver.find_element(By.CSS_SELECTOR,next_arrow_btn_css2).click()
except:
check_arrow = False
count_extract += 1
#-----------------------------------------#
#파일 저장
try:
insta_info_df = pd.DataFrame({"upload_id":upload_ids, "date_text":date_texts, "date_time":date_times, "date_title":date_titles, "main_text":main_texts,"thumbs up":thumbs_up_counts,"comments counts": comment_counts ,"comment":comments, "link":links})
insta_info_df.to_csv("{}.csv".format(save_file_name), index=False)
except Exception as E:
print("fail to save data")
print(E)
# 크롬 드라이버 종료
driver.close()
driver.quit()느낀 것
- 부족한게 너무 많아.. 배워나가자!

B2B SaaS 회사에서 Data Analyst로 일하고 있습니다.