NOTE
- 본 포스트는 6월 9일 공부한 웹 스크레이핑의 실습 과제인
네이버 영화 리뷰 정보 가져오기에서 내가 작성한 코드를 다시 보기 위해 작성되었다. 그 과정에서 특정 문제에 대해선 동기 분이 작성한 코드를 참고하여 Cleaner, Simpler한 코드를 찾아보자~!
(웹 스크레이핑 공부 글)
[Part 1]
# 문제
import re
from unittest import result
import requests
from bs4 import BeautifulSoup
import math #추가
"""
Part 1
영화 리뷰 스크레이핑을 위한 함수들을 구현해봅니다.
사용할 사이트는 네이버의 영화 리뷰입니다.
> 해당 BASE_URL 은 아래 설정이 되어 있습니다. 코드를 작성하면서 `BASE_URL` 에 문자열을 추가로 붙여서 사용해보세요!
> 추가로 BASE_URL 은 접속이 되지 않습니다.
"""
BASE_URL = "https://movie.naver.com/movie"1번
def get_page(page_url):
"""
get_page 함수는 페이지 URL 을 받아 해당 페이지를 가져오고 파싱한 두
결과들을 리턴합니다.
예를 들어 `page_url` 이 `https://github.com` 으로 주어진다면
1. 해당 페이지를 requests 라이브러리를 통해서 가져오고 해당 response 객체를 page 변수로 저장
2. 1번의 response 의 html 을 BeautifulSoup 으로 파싱한 soup 객체를 soup 변수로 저장
3. 저장한 soup, page 들을 리턴하고 함수 종료
파라미터:
- page_url: 받아올 페이지 url 정보입니다.
리턴:
- soup: BeautifulSoup 으로 파싱한 객체
- page: requests 을 통해 받은 페이지 (requests 에서 사용하는 response
객체입니다).
"""
Mymovie_URL = BASE_URL + '/bi/mi/point.naver?code=192608' #범죄도시2의 '평점' 탭
page = requests.get(Mymovie_URL)
soup = BeautifulSoup(page.content, 'html.parser')
return soup, page- 지금 보니까
Mymovie_URL을 그냥page_url파라미터를 넣었어야 했네?! 범죄도시2는 내가 테스트하려고 기록해뒀던 건데.. - 참고로
page.content,page.text는 같은 역할을 한다고 들었다.
2번
ef get_avg_stars(reviews):
"""
get_avg_stars 함수는 리뷰 리스트를 받아 평균 별점을 구해 리턴하는
함수입니다.
파라미터:
- reviews: 리뷰 객체가 항목으로 이루어진 리스트. 각 리뷰 객체는 다음과
같은 property 가 있어야 합니다:
- 'review_text': 리뷰 내용이 담긴 문자열 (str)
- 'review_star': 리뷰 별점이 담긴 숫자 (float)
리턴:
- 별점 평균: 주어진 리뷰들의 별점들을 평균을 낸 숫자(float) 입니다.
------------------------------------------------
예시:
reviews =
[
{
'review_text': 'Wow...!',
'review_star': 7
},
{
'review_text': 'Okay movie',
'review_star': 6
}
]
get_avg_stars(reviews) #=> 6.5
------------------------------------------------
"""
review_star = []
for i in range(len(reviews)):
review_star.append(reviews[i]['review_star'])
avg = sum(review_star) / len(reviews)
return avg - 난 일단 리뷰 평점만 모아둔 별도의 리스트를 하나 만들고, 그 안에서 평균을 내는 방식을 택했다.
- 근데 동기 코드 보니 이렇게 표현하는게 더 깔끔해 보이는 것 같다. score를 0으로 두고 for문들 돌리는데, 리스트 하나씩 빼고 딕셔너리는 키값으로 뽑아 더하기. 그리고 마지막에 Len(reviews)로 avg내기. (코드 옮겨두고 싶은데 다른 사람 코드 막 옮겨두면 안될 것 같아서 글로만..)
3번
def get_movie_code(movie_title):
"""
get_movie_code 함수는 영화 제목을 받으면 해당 영화 제목으로 검색했을 때
가장 먼저 나오는 영화의 아이디를 리턴합니다.
해당 영화의 아이디는 네이버에서 지정한대로 사용합니다.
여기에서 네이버에서 지정한 아이디란 예를 들어 다음과 같습니다:
- `https://movie.naver.com/` 에 접속
- 검색란에 영화 제목 (예: Soul) 입력 뒤 검색
- 해당 영화 페이지의 URL (예: `https://movie.naver.com/movie/bi/mi/basic.nhn?code=184517`) 의 'code=' 뒤에 나오는 숫자
파라미터:
- movie_title: 리뷰를 스크레이핑할 영화 제목이 담긴 문자열(str) 입니다.
리턴:
- 영화 아이디 번호: 네이버에서 지정한 영화의 아이디 번호가 담긴
숫자(int) 입니다.
"""
search_url = f"{BASE_URL}/search/result.naver?query={movie_title}§ion=all&ie=utf8"
page = requests.get(search_url)
soup = BeautifulSoup(page.content, 'html.parser')
res = soup.find(class_ = 'result_thumb')
res = list(res)[1] #<a href="/movie/bi/mi/basic.naver?code=192608"><img alt... 식의 값이 나온다.
res = str(res) #코드값만 찾기 쉽게 문자화
movie_code = res.split('code=')[1].split('"><img')[0] #정규표현식을 쓸 수도 있지만 잘 몰라서 나중에 써보기로.
movie_code = int(movie_code)
return movie_code- 이건 실제로 검색을 해보고 처음 나오는 영화가 어떤 클래스로 구성이 되어있는지 개발자도구를 통해 html 코드를 보고 작성해 나갔다. 내 기억엔
class = 'result_thumb'이 리스트 첫 번째 영화가 아니었던 경우에도 들어가 있었던 것 같은데, 어차피soup.find을 하면 하나만 뽑아주고 실제로 테스트해보니 잘 나와서 이렇게 했다. - 그렇게 뽑은
res에서 내가 원하는 결과를 필터링하기 위해 어떻게 해야할까 고민하다가 list, str으로 변경하는 방식을 택했다. 그리고 나서movie_code에서 split을 이용해서 원하는 부분을 뺐다.- 여기서 보통 정규표현식을 많이 쓰는 것 같긴 한데, 정규표현식을 제대로 모르기도 하고, 찾아본대로 해봐도 잘 안되서 일단 빨리 넘어가기 위해 split으로 했다. 그치만 정규표현식은 날개를 달아주는 스킬이므로 조만간 공부하는 시간을 가져야겠다.
- 마지막에 int로 바꿔주는 거 안해서 '아니 니가 원하는 건 다 해줬는데 왜 틀린건데..!!'를 여러 번 외쳤었다ㅋㅋ
- 동기 코드를 보니 이것 말고도 다른 태그를 검색해서 접근하는 방식이 여럿 사용된 것 같은데, 접근하는 과정 자체는 비슷한 것 같다.
4번
def get_reviews(movie_code, page_num=1):
"""
get_reviews 함수는 리뷰들이 담긴 리뷰 리스트를 리턴해주는 함수입니다.
각 리뷰는 다음과 같은 파이썬 딕셔너리 형태입니다:
{
'review_text': 리뷰 글이 담긴 문자열(str) 입니다,
'review_star': 리뷰 별점이 담긴 숫자(int) 입니다
}
파라미터:
- movie_code: 네이버에서 지정한 영화 아이디 번호가 담긴 숫자(int)
입니다.
- page_num: 리뷰를 몇 번째 리뷰 페이지에서 가져와야 하는지 담긴
숫자(int) 입니다. 아무것도 주어지지 않은 경우 기본값은 1 입니다.
리턴:
- 리뷰 리스트: 스크레이핑한 리뷰들이 각각 파이썬 딕셔너리로 위에 명시된
형태로 저장된 리스트입니다.
"""
review_url = f"{BASE_URL}/point/af/list.naver?st=mcode&sword={movie_code}&target=after&page={page_num}"
#범죄도시2 예시 https://movie.naver.com/movie/point/af/list.naver?st=mcode&sword=192608&target=after&page=1
page = requests.get(review_url)
soup = BeautifulSoup(page.content, 'html.parser')
review_list = []
content_all = list(soup.find_all(class_ = 'title'))
for i in range(len(content_all)): #해당 페이지에 있는 리뷰 개수만큼만 가져오도록. (참고로 한 페이지 꽉찬 경우, 한 페이지 당 리뷰가 10개 있음)
content_one = str(list(soup.find_all(class_ = 'title'))[i]) # 하나씩 불러올 것
#개별 리뷰 평점 정보
review_star = content_one.split('<em>')[1].split('</em>')[0]
review_star = int(review_star) #int로 변환!
# review_text
review_text = content_one.split('<br/>')[1].split('\n')[0] #리뷰 내용이 없는 경우 빈 값으로 나옴.
#list에 append
review_list.append({'review_text': review_text, 'review_star': review_star})
return review_list- 터미널에서 계속 테스트해보면서 적은 코드다. 기본 골격은 해당 페이지에 있는 리뷰 정보를 하나씩 꺼내와서 리뷰 평점 정보, 텍스트를 빈 리스트에 넣어 리턴해주는 거다.
- for loop 옆에 해당 주석을 달아놓은 이유는, 원래는 in range(10) 이렇게 적었다가 이러면 한 페이지에 10개 미만의 리뷰가 있을 경우 오류가 날 것 같아서 좀 더 일반화했다는 의미다.
- 리뷰 평점은 있는데 리뷰 텍스트는 없는 경우가 있었는데, 그런 경우엔 텍스트에 빈 결과가 나오도록도 했다.
- 근데 이거 진짜 간단하게도 표현이 된다..!! 포동동님꺼 나중에 다시 찾아보자.
5번
def scrape_by_review_num(movie_title, review_num):
"""
scrape_by_review_num 함수는 총 스크레이핑할 리뷰 개수를 받아 해당 개수만큼
리뷰 항목이 담긴 리뷰 리스트를 리턴합니다.
파라미터:
- movie_title: 리뷰를 스크레이핑할 영화 제목이 담긴 문자열(str) 입니다.
- review_num: 총 몇 개의 리뷰를 가져올지 정해주는 숫자(int) 입니다.
리턴:
- 리뷰 리스트: 주어진 review_num 만큼의 리뷰 항목을 담은 파이썬
리스트입니다. (각 리뷰 항목은 get_reviews 에서 명시된 파이썬 딕셔너리
형태여야 합니다.)
"""
reviews = []
movie_code = get_movie_code(movie_title)
total_page_num = math.ceil(review_num/10)
if review_num <= 10:
reviews = get_reviews(movie_code)
else:
if review_num / 10 == 0:
for i in range(1,total_page_num + 1):
reviews_list = get_reviews(movie_code, page_num=i)
for i in reviews_list:
reviews.append(i)
else:
for i in range(1,total_page_num + 1):
reviews_list = get_reviews(movie_code, page_num=i)
for i in reviews_list:
reviews.append(i)
reviews = reviews[:review_num]
return reviews- 가장 시간을 많이 썼던 문제였던 것 같다. 왜 이렇게 짜게 되었는지는 설명이 좀 필요할 것 같다.
- 네이버 영화 페이지는 한 페이지가 꽉차면 10개의 리뷰가 존재한다. 즉, 내가 원하는
review_num이 10개가 넘으면 페이지를 이동해야 하는데 어떻게 할 수 있을까?가 주요 고민 포인트였다.- (작년에 혼자 게시판 게시글 뽑아오기 했을 때는 자동으로 페이지 이동해주는 메서드를 썼었다. 근데 이번엔 그것 말고 주어진 라이브러리 내에서만 해보려고 했다.)
- 그래서 원하는 리뷰가 10의 자리에 딱 떨어지면 이전에 작성한 get_reviews를 통해 그대로 해당 페이지만큼 가져오면 되는거고, 만약 10에 딱 떨어지지 않는다면 해당 페이지까지의 모든 리뷰를 일단 리스트에 넣고, 그 다음 review_num에 지정한 숫자만큼만 슬라이싱해 가져오는 걸로 구조를 짰다.
- 만약 review_num으로 15를 넣었다면, 2페이지에 있는 리뷰 다 가져와 리스트에 넣고, 그 다음그 리스트에서 15개만 리턴.
- 근데 이게 위에
get_reviews함수가 복잡해지니 똑같이 복잡한 형태로 바뀐 것 같기도 하고?! 다른 분은 while문을 써서 쉽게 표현했다. 나중에 비슷한 작업할 때 다시 들여다봐야겠다. 멋있엉..
movie_title, page_num을 넣으면 그 페이지까지 리뷰 뽑아오기
- 이건 위에 적었던 코드 중 일부를 그대로 옮겨오기만 해도 작동하는 거라 괜찮았다.
[Part2]
도전과제.
스크레이핑한 데이터를 데이터베이스에 저장하는 파트였다.
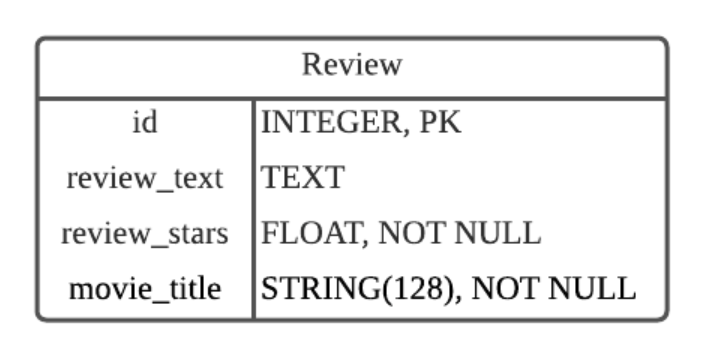
- Part2에서 part1에 있는 함수를 써야했다. 나는 part1 내용 앞에 다 가져다 붙여놓았는데,
Part_1.scrape_by_page_num(movie_title, page_num)이렇게 간단히 표현이 가능했다니!!! ㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋ 휴 하나 배웠다~ - 데이터베이스에 넣는거야 이전에 해봤던 대로 하기만 하면 되서 크게 어렵지 않았다.
def store_by_page_num(movie_title, page_num=10, conn=conn):
"""
store_by_page_num 함수는 영화 제목, 페이지 번호, 데이터베이스 커넥션 객체를
받아 주어진 영화제목의 리뷰를 총 주어진 페이지 개수 만큼 스크레이핑 한 뒤에
데이터베이스에 저장합니다.
파라미터:
- movie_title: 리뷰를 스크레이핑할 영화 제목이 담긴 문자열(str) 입니다.
- page_num: 첫 번째 페이지에서부터 스크레이핑할 페이지 개수가 담긴
숫자(int) 입니다.
- conn: 데이터베이스와 연결되 커넥션 객체
리턴:
- 별도로 없습니다.
"""
#db에 저장할 데이터
reviews = []
movie_code = get_movie_code(movie_title)
for i in range(1, page_num + 1):
reviews_list = get_reviews(movie_code, page_num=i)
for i in reviews_list:
reviews.append(i)
# 데이터 넣기
cur = conn.cursor()
for i in range(0,len(reviews)):
id_num = i + 1
t = list(reviews[i].items())
v1 = t[0][1]
v2 = t[1][1]
cur.execute("INSERT INTO Review(id, review_text, review_star, movie_title) VALUES (?, ?, ?, ?)", (id_num, v1,v2, movie_title))
conn.commit(); 여기까지 보며 전반적으로 느낀 건, 검색할 태그를 잘 정하면 전체적인 코드가 더 깔끔해지는 것 같다는 것이다.
Feeling
- 평소에는 과제 다 풀고, PR까지 한 다음에 내가 헷갈렸던 부분 바로 다른 분들 코드 보면서 배우곤 했었는데, 이 과제는 워낙 그런 부분이 많아서 따로 시간을 잡아 봐야겠다고 생각을 했었다. 근데 잘 한건 같다.
- 과제 다 했다고 끝내지 말고 다른 동기들의 코드도 잘 들여다 보며, 나와 접근 방식은 어떻게 다른지, 코드로는 그 생각을 어떻게 표현했는지 배워야겠다.
- 처음에는 깔끔한 코드에 집착하기보단 일단 작동하는 코드를 만드는데 집중하고, 나중에 실력이 쌓이면 Pythonic한 것까지 생각하라는 얘기를 들었었다. 처음부터 너무 큰 부담을 느끼지는 말자. 지금처럼 이렇게 하나씩 배워나가면 되는거다.

B2B SaaS 회사에서 Data Analyst로 일하고 있습니다.