DataFrame에서 필요한 row, column만 불러오기 위한 pandas 문법인 loc, iloc의 기본적인 내용에 대해서 정리해둔다. 맨날 헷갈려!
DataFrame 준비
(Kaggle에 오픈되어 있는 Titanic Data 입니다.)
import pandas as pd
df = pd.read_csv("train.csv")
df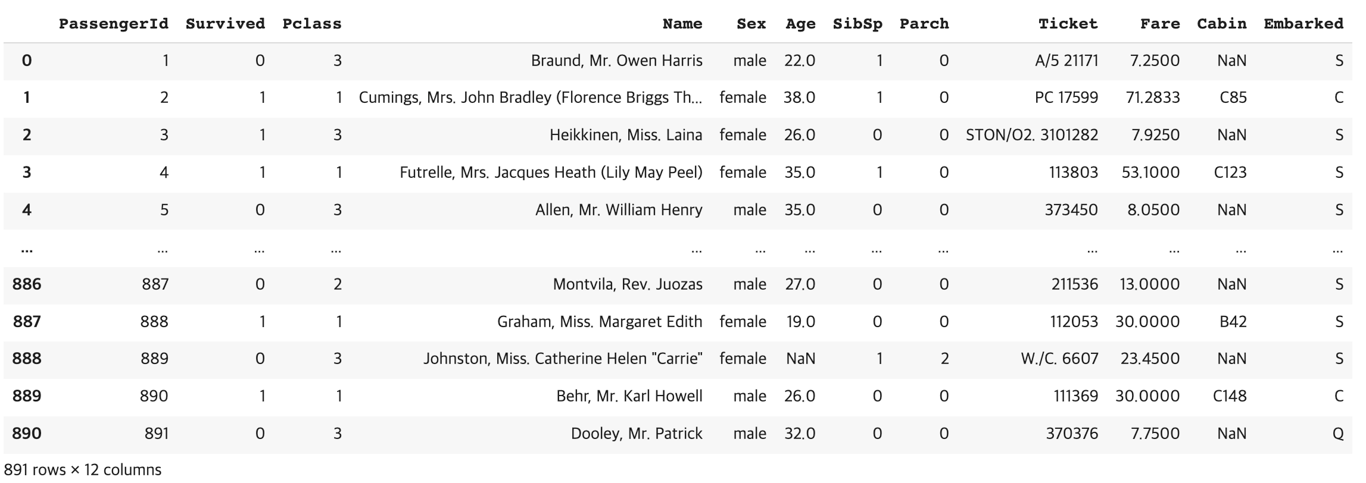
이 DataFrame에서 내가 원하는 행/열만 불러오려면 어떻게 해야할까?
df.loc[]
Access a group of rows and columns by label(s) or a boolean array.
df.loc[행 인덱싱 값, 열 인덱싱 값]
loc은 location의 약자이다.
데이터 프레임 행/열의 라벨을 통해 가져오는 방법이다.
쉽게 생각해 칼럼 '이름' 같은 것으로 생각하면 될 것 같다.
(boolean array는 우선 다루지 않겠다. 쓴 적이 없다.)
설명을 더 하기보단 예시를 쭉 나열해보겠다.
첫 번째 row 추출하기
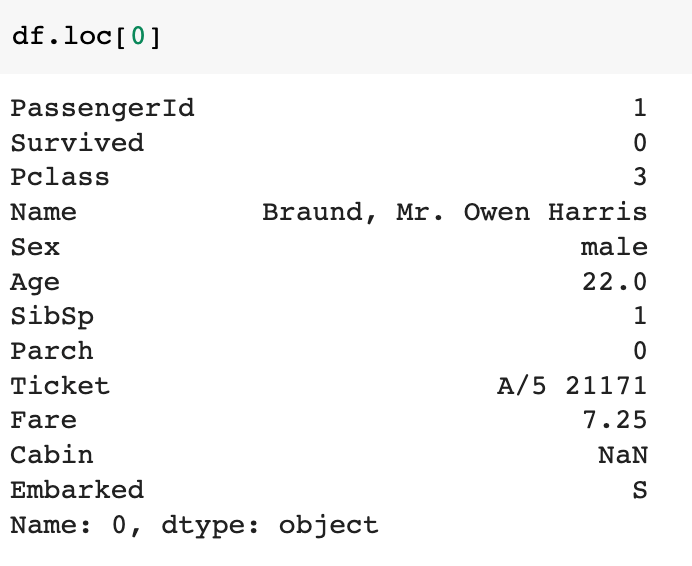
- (참고로
df.loc[[0]]으로 하면 이렇게 볼 수도 있다)
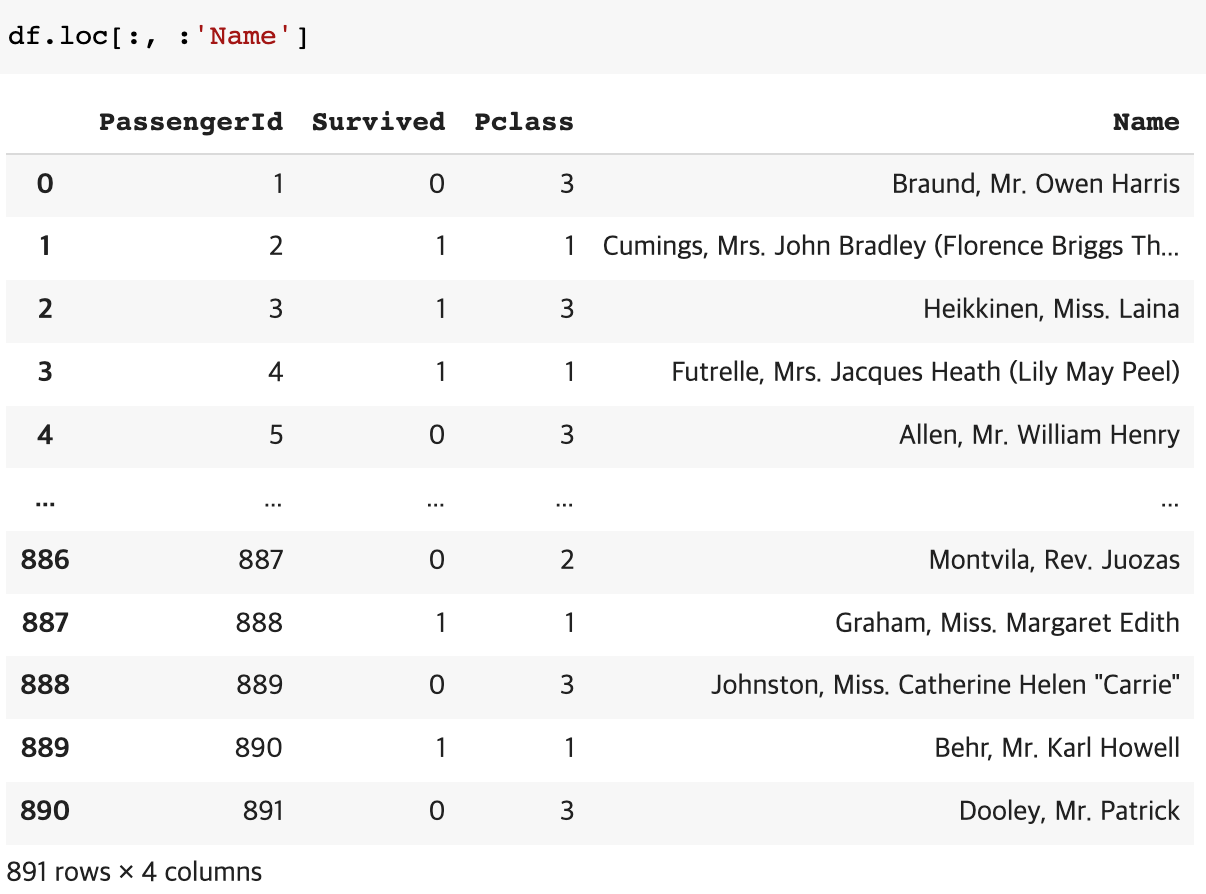
두 번째 row의 Name이 알고 싶다면?

슬라이싱을 통해서 여러 값도 가져올 수 있다.

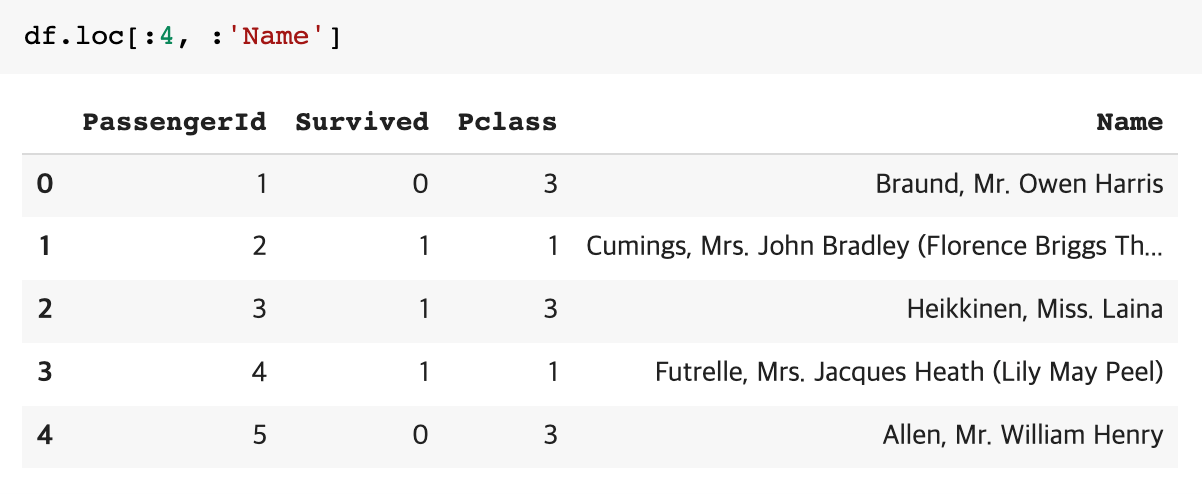
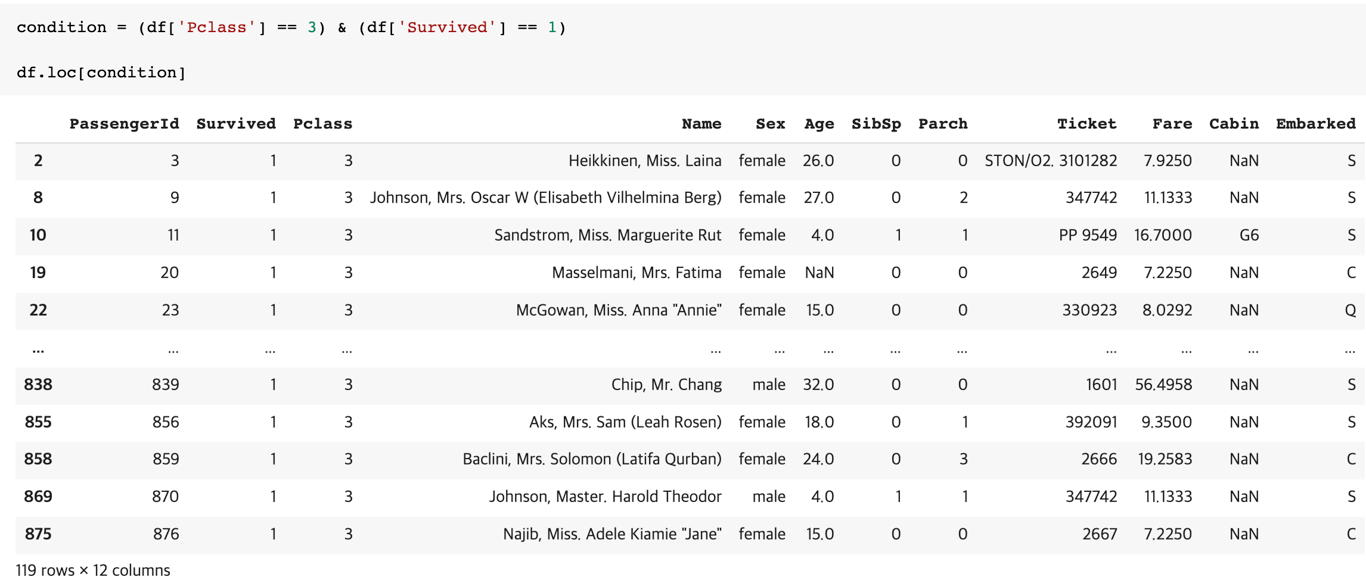
conditioning도 loc을 통해 할 수 있다
df.iloc[]
Purely integer-location based indexing for selection by position.
iloc은 Integer location의 약자이다.
데이터 프레임 행/열의 순서를 나타내는 정수를 통해 가져오는 방법이다. df.loc[]이 라벨을 사용한다면 df.iloc[]은 각 행렬의 순번을 사용하는 차이가 있다.
설명을 더 하기보단 예시를 쭉 나열해보겠다.
(보면 알겠지만 이름 대신 정수가 들어간다는 것 빼고는 동일하다)
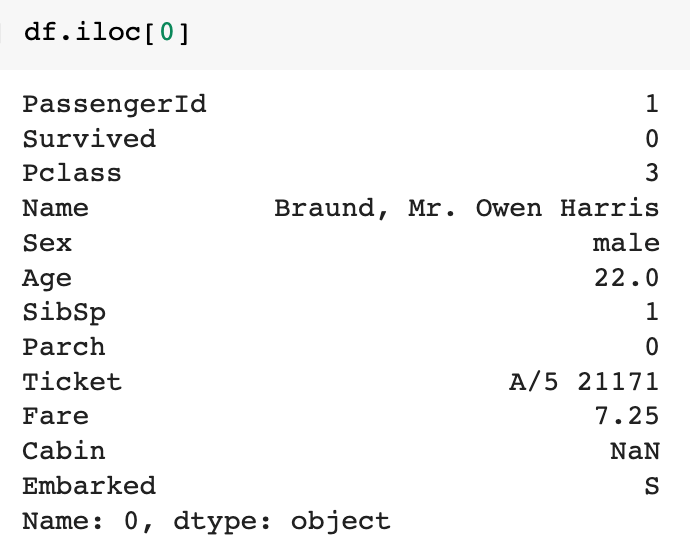
첫 번째 row 추출하기
두 번째 row의 Name이 알고 싶다면?

슬라이싱을 통해서 여러 값도 가져올 수 있다.



- 참고)
df.iloc[::2, :]식으로 활용하면, 짝수 번째에 해당하는 행만 뽑을 수 있다. 칼럼에 대해서도 마찬가지다.
이런 인덱싱도 가능하다!
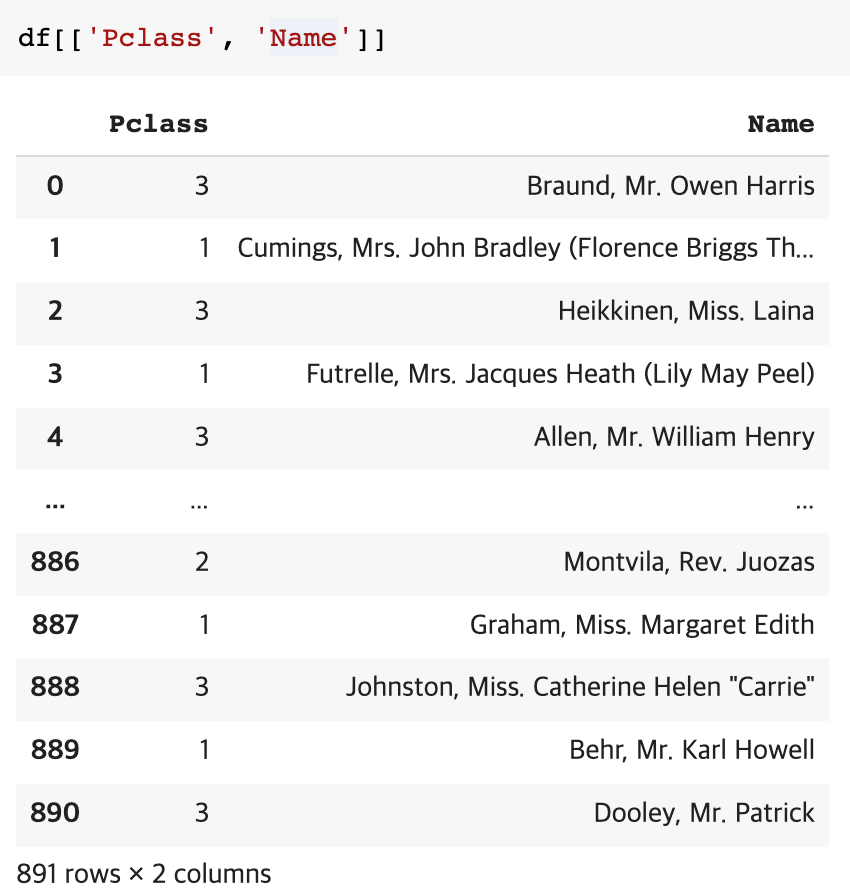
바로 인덱싱 하기 df['column명']

여러 가지도 가능하다 df[['a column', 'b column']] (안에 리스트 형태로 넣어야 한다는 것 유의)
- 참고로 리스트 슬라이싱을 할 때 칼럼은 안된다. row에 대한 슬라이싱은
df['a':'d']이런 식으로 하면 된다는데, 많이 쓰게 될지는 모르겠다. 대신 loc, iloc을 주로 쓰게 되지 않을까.
헷갈리긴 하지만, 아마 인덱싱/슬라이싱은 매우 자주 쓰게 될 것이기 때문에 시간이 지나면 자연스럽게 익숙해지지 않을까 싶다.
pandas 공식 문서를 보시려면 여기를 눌러주세요.
