당월에 방문한 순 방문자 수는 어떻게 되는지, 이전에 방문 기록이 있는 고객의 경우 그 주기가 어떻게 되는지 범주화하는 코드를 적어 보았다. 회고해 본다.
데이터 형태
분석에 사용한 것은 방문 데이터이다.
token_id별로date가 일자로 찍혀있다.- ex.
{'date' = [2023-04-08, 2023-04-08], 'token_id' = [xx555, aa888]}
- ex.
코드
# 날짜 정보를 datetime 형식으로 변환
df['date'] = pd.to_datetime(df['date'])
# 고객별로 데이터 정렬
df = df.sort_values(['token_id', 'date'])- 기본적인 준비 먼저.
# 이전 방문일 계산
df['Prev_Visit'] = df.groupby('token_id')['date'].shift()
df['Prev_Visit_Period'] = df['date'] - df['Prev Visit']token_id별로 이전 방문일을 계산하기 위해 groupby를 해준 후shift()함수를 쓰면 편하다. 시계열 데이터에서 많이 쓰인다고 하니 기억해두면 좋을 것 같다.- 아래와 같은 데이터라면
data = {'date': ['2023-04-07', '2023-04-08', '2023-04-07', '2023-04-06'], 'token_id': ['abc123', 'abc123', 'def456', 'ghi789']} df = pd.DataFrame(data)- 위 코드 실행 시 결과는 아래와 같이 나온다.
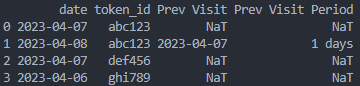
- 위 코드 실행 시 결과는 아래와 같이 나온다.
df['Prev_Visit_Period'] = df.groupby('token_id')['date'].diff()한 줄로 표현도 가능하다.diff()는 이전 값과의 차이를 반환하는 함수다.
# 고객별로 방문 주기 분류
df['Category'] = pd.cut(df['Prev_Visit_Period'].dt.days, bins=[-float('inf'), 30, 60, 90, float('inf')], labels=['30 days or less', '31-60 days', '61-90 days', 'More than 90 days'])- pandas의
cut()함수를 이용해 구간을 분류해줬다. - 참고로
bins에 적은 건 각 구간의 경계값이다. 4개의 구간에 대해 4개의 label을 붙이는 거다.
# 월별로 방문 주기 분류별 고객 수를 계산
result = df.groupby([pd.Grouper(key='date', freq='M'), 'Category', 'token_id'])['Prev_Visit_Period'].max().reset_index(name='Prev_Visit_Period') \
.groupby([pd.Grouper(key='date', freq='M'), 'Category'])['Prev_Visit_Period'].count().reset_index(name='Count')
result['Month'] = result['date'].dt.strftime('%Y-%m')
result = result.drop('date', axis=1)- 이 부분이 좀 복잡해보일 수 있는데, 내 의도를 먼저 설명해보겠다.
- 당월에 해당 고객을 범주에 count할 때, 여러 번 방문한 경우 직전 방문일과의 차이가 가장 큰 하나에 대해서만 count 하고자 했다.
- 만약 한 고객이 '1월 1일', '2월 7일'과 '2월 10일'에 방문했다고 해보자. 2월에 해당 고객을 카테고리에 분류할 때, 직전 방문일과의 차이가 가장 큰 것 하나에 대해서만, 즉 1월 1일과 2월 7일의 차이인 '31-60 days' 해당 범주에만 +1 count를 한다.
- 물론 내 의도가 정답은 아니고, 해당 데이터를 보는 목적에 따라 달라질 수 있겠다.
- 코드 첫번째 줄에서는 먼저 월별 등으로 그룹화를 해주고,
Prev_Visit_Period가 max인 것만 남기고, 두 번째 줄에서는 그 값을 할당하는 것이다.
- 근데 이 글 적으며 다시 보니 월별로 그룹화 한 후
Category, token_id로도 그룹화를 해주는데, 그렇다보니 내 의도가 정확히 안 맞아 떨어지는 코드였다. ;; - 예를 들어, 아래와 같은 데이터프레임이 있을 때,
data = {'date': ['2023-03-05', '2023-04-07', '2023-04-08', '2023-04-07', '2023-04-06'], 'token_id': ['abc123', 'abc123', 'abc123', 'def456', 'ghi789']} df = pd.DataFrame(data)abc123의 범주가 '30 days or less'랑 '31-60 days'에 하나씩 있고, 각 범주 내의 max인 것도 맞기 때문에 결과적으로 result를 봤을 때abc123의 것이 4월에 총 +2 count가 된다..
- 방문주기 계산을 하기 전에 아래 코드를 추가해서 가장 큰 것 하나만 남겨주고 나머지는 null 처리를 해주면 된다.
df['Max Prev Visit Period'] = df.groupby('token_id')['Prev Visit Period'].transform('max') df.loc[df['Prev Visit Period'] < df['Max Prev Visit Period'], 'Prev Visit Period'] = pd.NaT
# 월별로 방문한 고객 수를 계산
monthly_customers = df.groupby([pd.Grouper(key='date', freq='M'), 'token_id']).size().groupby(level=0).count().reset_index()
monthly_customers.columns = ['date', 'Visit_Customers_total']
monthly_customers['Month'] = monthly_customers['date'].dt.strftime('%Y-%m')
monthly_customers = monthly_customers.drop('date', axis=1)
# 합치기
result = result.merge(monthly_customers, on='Month')- token_id 기준으로 unique count해서 월별 순 방문자까지 찾아주면 끝!

B2B SaaS 회사에서 Data Analyst로 일하고 있습니다.