1. DB 아무거나 쓰죠?
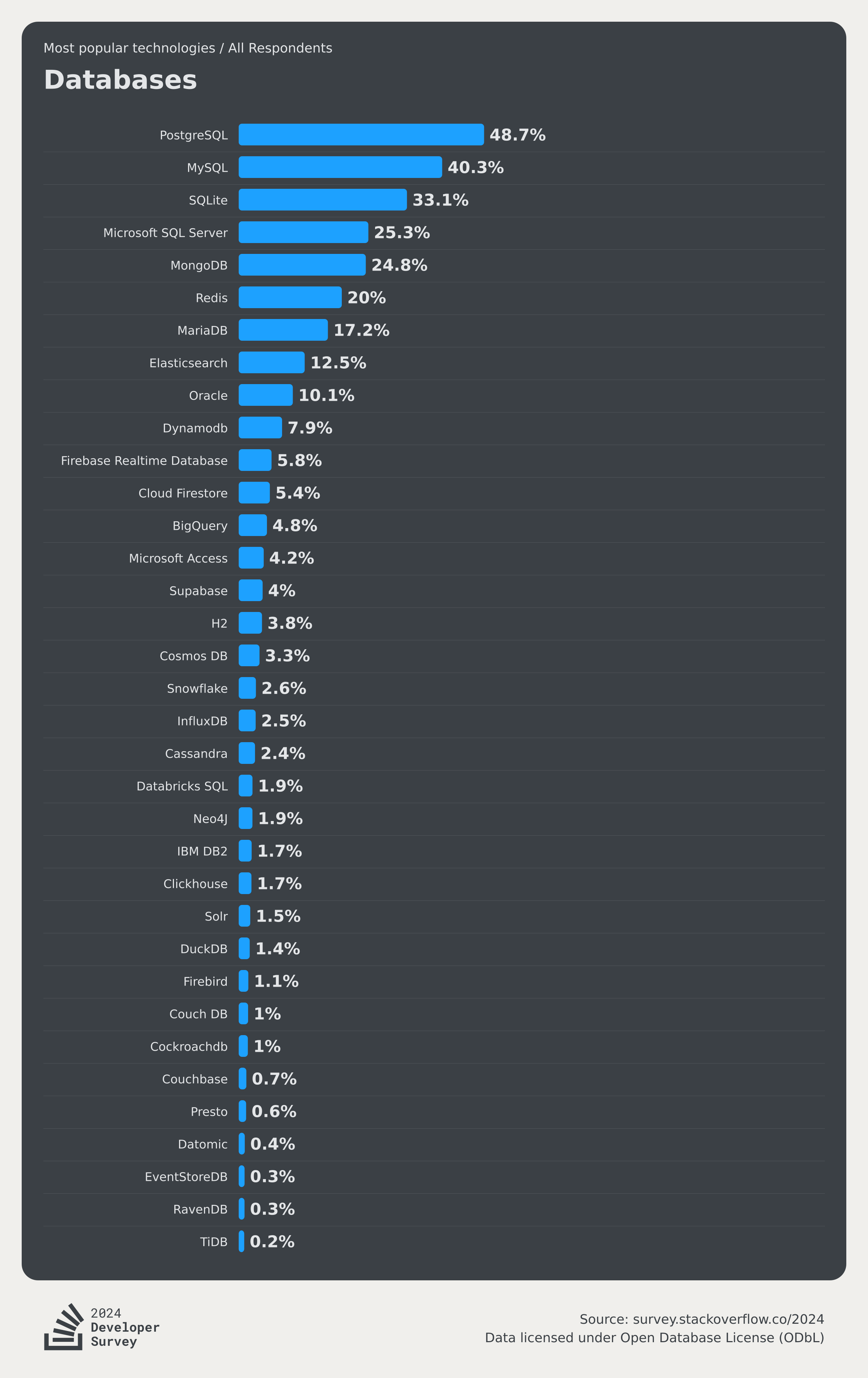
프로젝트를 시작하면 다들 기술 스택을 고민한다.
DB는 항상 MySQL을 사용했는데 최근 2024년 스택오버플로우 결산을 보니 PostgreSQL이 MySQL을 제치고 1위가 됐다. 같은 RDBMS인데 전통의 강자를 어떤 이유로 이겼는지도 궁금하고 지금 진행 중인 프로젝트에 어떤 DB를 사용하면 좋을지 고민하고 있기에 한번 싹 정리해보겠다.
1.1 DB 선택의 중요성
DB 선택은 간단해 보일 수 있으나, 시간이 지남에 따라 서비스가 확장되고 사용자 요구사항이 복잡해질수록 이 결정이 프로젝트의 성공과 실패를 좌우한다.
- 모든 서비스의 핵심 자원
- 장기적 관점에서의 확장성을 생각
- 데이터의 일관성과 무결성은 서비스 신뢰도와 직결
1.1.1 개발 속도와 유연성
- 스키마 변경 여부: 프로젝트 초기에 데이터 구조가 자주 바뀐다면, 스키마가 유연한 DB가 더 나을 수 있다. 예를 들어, 초창기 스타트업이라면 NoSQL(MongoDB 등)을 선택하여 빠른 프로토타이핑이 가능하게 하면 좋다!
- ORM 사용 편의성: RDBMS는 오랜 역사를 통해 쌓인 다양한 ORM(Object-Relational Mapping) 툴들이 있어 개발 속도를 높여줌 (JPA 등등).
1.1.2 성능과 확장성
- 수직 확장(Scale-up): 서버 사양을 업그레이드하여 성능을 높이는 방식으로, 전통적인 RDBMS가 주로 적용하는 방법.
- 수평 확장(Scale-out): 여러 대의 노드를 병렬로 연결해 처리량을 늘리는 방식으로, NoSQL이 설계상 이점을 지니는 경우가 많다.
1.1.3 유지보수 및 운영 비용
- 엔터프라이즈 솔루션의 라이선스 비용: Oracle, MS SQL Server 등의 상용 DB는 강력하지만 도입 및 운영 비용이 매우 높다.
- 오픈 소스 기반: MySQL, PostgreSQL, MongoDB 등은 도입 비용이 저렴하지만, 확장 시에는 별도의 아키텍처 설계가 필요.
- 커뮤니티와 생태계: 도입 후 문제가 발생했을 때, 얼마나 빠르게 해결할 수 있는가도 선택의 큰 요소 중 하나.

➡️ 서비스에 맞지 않는 DB를 선택하면 프로젝트는 산으로 간다는 뜻이다.
1.2 SQL vs. NoSQL
프레임워크에 따라 결정하지말고 정확히 필요한 데이터베이스를 선택하자!
1.2.1 SQL, RDBMS
- 오랜 기간 동안 관계형 데이터베이스(RDBMS)는 기업 환경에서 표준으로 활용됨. (=리소스가 많음)
- 정규화를 통해 데이터 무결성을 체계적으로 관리할 수 있고, ACID 트랜잭션 덕분에 데이터 일관성을 보장할 수 있어서 현재도 많이 활용됨.
- SQL(Structured Query Language)을 사용하는 일관성 있는 쿼리 구조 또한 개발자들이 빠르게 익히고 적용하기에 편리.
1.2.2 NoSQL
하지만... 웹 서비스가 폭발적으로 성장하면서, 빅데이터(Big Data) 시대가 도래하게된다.
초당 수천~수만 건 이상의 요청을 처리해야 하는 환경에서,
기존 RDBMS의 수직 확장 한계와 스키마 유연성 부족은 서비스에 큰 장애물이 되었다.
- 분산 환경을 전제로 한 설계로, 노드를 쉽게 추가하여 처리량을 늘릴 수 있다.
- 스키마 없는 데이터 모델을 채택하여, 프로젝트 초기에 데이터 구조가 자주 바뀌어도 빠른 개발과 반복이 가능하다.
- BASE(Basically Available, Soft-state, Eventually consistent) 특성으로, 완벽한 일관성보다는 빠른 처리와 확장성을 우선시한다.
2. RDBMS
2.1 MySQL

- 세계에서 가장 널리 사용되는 오픈 소스 RDBMS (였으나 두번째로 밀림)
- LAMP 스택(Linux, Apache, MySQL, PHP)의 핵심 요소로, 다양한 웹 호스팅 환경에서 기본 옵션처럼 취급.
2.1.1 특징과 장단점
[특징]
- 다양한 스토리지 엔진 지원
- InnoDB(트랜잭션 지원), MyISAM(간단하고 빠른 읽기/쓰기), Memory(인메모리) 등
- 엔진마다 특성이 달라, 요구사항에 맞게 선택 가능
- 간단한 설치 및 설정
- 초기 학습 장벽이 낮고, GUI 툴(phpMyAdmin, MySQL Workbench 등)도 많음
- 소~중규모 서비스까지 빠르게 적용할 수 있음
- 커뮤니티와 많은 자료
[장단점 정리]
| 장점 | 단점 | |
|---|---|---|
| 장점 | - 배우기 쉽고, 웹 호스팅 환경에서 기본적으로 제공되는 경우가 많음 - 대규모 커뮤니티와 광범위한 레퍼런스 - 스토리지 엔진을 선택해 유연성 확보 | - 일부 고급 기능(PostgreSQL 대비)이 부족할 수 있음 - 대규모 트래픽 처리 시 샤딩, 레플리케이션 설정이 복잡 - 오라클에 인수된 이후, 라이선스 정책 변화 가능성에 대한 우려도 존재 |
| 단점 | - InnoDB로 안정적인 트랜잭션 처리 가능 - 간단한 쿼리와 CRUD 중심의 애플리케이션에서 탁월한 성능 | - 일부 환경에서 정교한 튜닝이 필요할 수 있음 - 매우 큰 규모(초당 수만 트랜잭션 이상)에 대한 확장성은 다른 DB 대비 제한적 |
2.1.2 언제 쓰나요?
- 블로그, 커머스
- 워드프레스나 여러 CMS에서 기본 DB로 사용
- 쇼핑몰, 게시판 등에서 자주 활용
- 개발 시작이 쉽고, 유지 비용이 저렴하며, 대부분의 서버/호스팅 제공 업체가 기본적으로 지원
- 임베디드 환경 : MySQL을 경량화한 MariaDB, Percona 등을 변형해 사용하는 경우
2.1.3 간단한 예시 코드
-- 1. 데이터베이스 생성
CREATE DATABASE IF NOT EXISTS myapp_db;
USE myapp_db;
-- 2. 테이블 생성 (InnoDB 엔진)
CREATE TABLE users (
id INT AUTO_INCREMENT PRIMARY KEY,
username VARCHAR(50) NOT NULL,
email VARCHAR(100) NOT NULL,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
) ENGINE=InnoDB;
-- 3. 데이터 삽입 (Create)
INSERT INTO users (username, email)
VALUES ('alice', 'alice@example.com'),
('bob', 'bob@example.com');
-- 4. 데이터 조회 (Read)
SELECT * FROM users;
-- 5. 데이터 수정 (Update)
UPDATE users
SET email = 'alice@newmail.com'
WHERE username = 'alice';
-- 6. 데이터 삭제 (Delete)
DELETE FROM users
WHERE username = 'bob';2.2 PostgreSQL
2.2.1 특징과 장단점
[특징]
- 고급 SQL 기능: CTE(Common Table Expressions), 윈도우 함수, 파티셔닝 등
- JSON / Hstore 지원: 문서형 데이터 일부 기능을 RDBMS 내에서 활용 가능
- GIS(지리 정보 시스템) 확장: PostGIS라는 강력한 확장 기능으로 위치 기반 서비스 구현 가능
[장단점 정리]
| 장점 | 단점 | |
|---|---|---|
| 장점 | - ACID 트랜잭션, 풍부한 SQL 표준 기능 - 지리 정보, 반정형 데이터(JSON) 등 다양한 유형 지원 - SQL 표준 준수도가 높아 이식성(Portability) 우수 | - 초기 설정이 다소 복잡 - MySQL 대비 자료와 호스팅 지원이 적을 수 있음(최근에는 많이 개선) |
| 단점 | - 대규모 트랜잭션 처리에 강함 - 복잡한 쿼리, 통계, 분석 업무에 최적 - 윈도우 함수/CTE 등을 통한 쿼리 최적화 | - 실행 계획이 복잡해질 수 있고, 튜닝을 위한 학습 곡선이 있음 - 기능이 많아 메모리 및 디스크 사용량 증가 가능 |
2.2.2 사용 사례
-
금융, 정부, 대기업 프로젝트 : 데이터 무결성과 보안이 중요하며, 복잡한 모델링과 트랜잭션을 요구하는 시스템
-
GIS / 지도 / 위치 기반 서비스 : PostGIS 확장을 통해 고급 지리 연산을 처리 (예: 맵핑, 거리 계산, 겹치는 영역 탐색 등)
-
웹 애플리케이션 + JSON 혼합 데이터 : RDBMS의 안정성과 NoSQL 스타일 문서 저장을 함께 구현 가능
2.2.3 간단한 예시 코드
-- PostgreSQL
CREATE DATABASE myapp_db;
-- 테이블 생성
CREATE TABLE users (
id SERIAL PRIMARY KEY,
username VARCHAR(50) NOT NULL,
email VARCHAR(100) NOT NULL,
profile JSONB DEFAULT '{}',
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
-- 데이터 삽입
INSERT INTO users (username, email, profile)
VALUES (
'charlie',
'charlie@example.com',
'{"age": 30, "hobbies": ["coding", "music"]}'
);
-- JSONB 필드 쿼리
SELECT
username,
email,
profile ->> 'age' AS user_age
FROM users;
-- JSONB 필드 업데이트
UPDATE users
SET profile = jsonb_set(profile, '{age}', '31'::jsonb)
WHERE username = 'charlie';
-- 데이터 삭제
DELETE FROM users
WHERE username = 'charlie';2.3 Oracle / MS SQL Server
2.3.1 특징과 장단점
[특징]
- 고가용성 및 고성능
- Oracle의 RAC(Real Application Clusters), MS SQL Server의 클러스터링 및 Always On 기능 등을 통해 무중단 서비스와 고성능을 보장
- 엔터프라이즈 기능
- 파티셔닝, 압축, 보안(Transparent Data Encryption), 고급 모니터링, BI 솔루션(SSIS, SSRS, SSAS) 등 다양한 부가 기능이 내장
- 전문 지원 및 생태계
- 벤더(오라클, 마이크로소프트)에서 공식적인 기술 지원이 제공되며, 엔터프라이즈급 SLA(Service Level Agreement) 계약 가능
[장단점 정리]
| 장점 | 단점 | |
|---|---|---|
| Oracle | - 최고 수준의 안정성과 고가용성 - 엔터프라이즈 기능(RAC, Data Guard 등) 풍부 - 전 세계 대기업과 금융권에서 오랜 레퍼런스 축적 | - 높은 라이선스 비용 및 유지보수 비용 - 전문 DBA가 필요할 정도로 복잡한 설정 |
| MS SQL Server | - Windows/.NET 생태계와 최적 통합 - SSMS(SQL Server Management Studio)로 편리한 GUI 관리 - BI 기능(SSIS, SSRS 등) 내장 | - OS 종속성(주로 Windows 서버에서 최적) - 대규모 트래픽은 Oracle 대비 경험치가 적을 수 있음 |
2.3.2 사용 사례
- 금융권, 대기업, 공공기관
- 방대한 거래량, 복잡한 업무 로직, 즉각적인 장애 대응이 필요한 핵심 시스템에서 활용
- 강력한 보안 및 트랜잭션 처리가 중요할 때
- 엔터프라이즈 ERP/CRM
- SAP, Oracle E-Business Suite, Microsoft Dynamics 등과의 안정적 연동
- 대규모 DB에서 발생하는 복잡한 쿼리와 보고서, 대시보드 등을 처리
- 데이터 웨어하우스(DW), OLAP
- 방대한 양의 데이터를 분석하기 위한 고성능 리포팅 및 큐브(Cube) 연산, 머신러닝 모델 적용 등
- 방대한 양의 데이터를 분석하기 위한 고성능 리포팅 및 큐브(Cube) 연산, 머신러닝 모델 적용 등
2.3.3 간단한 예시 코드 (Oracle)
-- Oracle DB 예시 (SQL*Plus 환경)
-- 스키마/사용자 생성
CREATE USER myapp_user IDENTIFIED BY myapp_pw
DEFAULT TABLESPACE users
TEMPORARY TABLESPACE temp
QUOTA 100M ON users;
GRANT CREATE SESSION, CREATE TABLE, CREATE SEQUENCE, CREATE VIEW TO myapp_user;
-- 사용자 전환
CONNECT myapp_user/myapp_pw;
-- 테이블 생성
CREATE TABLE users (
id NUMBER GENERATED ALWAYS AS IDENTITY PRIMARY KEY,
username VARCHAR2(50) NOT NULL,
email VARCHAR2(100) NOT NULL,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
-- 데이터 삽입
INSERT INTO users (username, email)
VALUES ('alice', 'alice@example.com');
COMMIT;
-- 데이터 조회
SELECT * FROM users;
-- 데이터 수정
UPDATE users
SET email = 'alice@newmail.com'
WHERE username = 'alice';
COMMIT;
-- 데이터 삭제
DELETE FROM users
WHERE username = 'alice';
COMMIT;3. NoSQL

잘 모르는 내용이에요 죄송합니다. 하지만 열심히 작성했어요.
3.1 문서형(Document) DB
3.1.1 특징
- JSON(또는 BSON) 같은 문서 형식으로 데이터를 저장
- 테이블 스키마가 고정되지 않고, 유연한 구조를 가질 수 있음
- 데이터를 문서 단위로 관리하고, 문서 내부 필드에 대해 인덱싱, 검색을 지원
3.1.2 대표 예시: MongoDB
- 특징: 스키마가 유연하며, 복잡한 조인 대신 중첩 문서를 활용해 빠른 개발 가능
- 장점
- 데이터 구조가 빈번히 바뀌어도 대응이 쉬움
- 높은 수평 확장성(Sharding), 대규모 트래픽 처리에 유리
- 개발 생산성(프로토타이핑)에 강점
- 단점
- RDBMS 대비 ACID 트랜잭션이 제한적 (최근 버전에서는 트랜잭션 기능이 많이 보충 중)
- 복잡한 조인이나 그룹화(aggregation)는 비교적 난이도가 있음
- 대규모 데이터 모델링 시, 적절한 구조 설계 필수
3.1.3 사용 사례
- 로그, 이벤트 데이터 수집: 빠르게 변동되는 스키마, 대용량 처리
- 프로토타입, MVP(최소 기능 제품): 프로젝트 초기 빠른 개발/수정에 유리
- 실시간 분석(메트릭, 모니터링): BSON 문서 구조로 여러 필드를 유연하게 저장
3.1.4 간단한 예시 코드 (MongoDB)
// 1. 데이터베이스 및 컬렉션 선택
use myProject;
// 2. 문서 삽입
db.users.insertMany([
{ username: "alice", email: "alice@example.com", hobbies: ["reading", "cycling"] },
{ username: "bob", email: "bob@example.com" }
]);
// 3. 문서 조회
db.users.find({ username: "alice" });
// 4. 문서 수정
db.users.updateOne(
{ username: "bob" },
{ $set: { email: "bob@newdomain.com" } }
);
// 5. 문서 삭제
db.users.deleteOne({ username: "alice" });3.2 키-값(Key-Value) DB
3.2.1 특징
- 단순한 키-값 쌍 형태로 데이터를 저장
- In-memory 구조를 사용하거나 디스크 기반으로도 동작
- 매우 빠른 조회/쓰기 성능으로, 캐싱, 세션 관리, 실시간 순위 계산 등에 유리
3.2.2 대표 예시: Redis
- 특징: 메모리 기반 저장소, 다양한 자료구조(String, Hash, List, Set 등) 제공
- 장점
- 초고속 읽기/쓰기 (In-memory)
- Pub/Sub, Lua 스크립트, 트랜잭션 등 부가기능 풍부
- 간단한 설치/구성
- 단점
- 메모리 용량이 중요한 제한 요소 (디스크 RDB, AOF 등 보조 기능이 있지만, 여전히 메모리에 의존)
- RDBMS처럼 복잡한 쿼리나 조인 불가
3.2.3 사용 사례
- 캐시 서버: DB 부하를 줄이고, 빠른 응답을 위해 결과를 저장
- 세션 관리: 웹 서비스의 로그인 세션이나 사용자 상태 관리
- 실시간 통계/랭킹: 게임 순위, 투표 집계, 대시보드 집계 등
3.2.4 간단한 예시 코드 (Redis - CLI)
# 1. 키-값 삽입
SET user:1 "alice"
SET user:2 "bob"
# 2. 키-값 조회
GET user:1
# "alice"
# 3. 키 삭제
DEL user:23.3 컬럼 패밀리(Column-Family) DB
3.3.1 특징
- 컬럼 그룹(Column Family) 단위로 데이터를 저장하고 관리
- 구글의 Bigtable, 아마존의 Dynamo 논문에서 영향을 받아 발전한 구조
- 수평 확장(Sharding)이 기본이며, 대규모 분산 환경에서 높은 쓰기/읽기 처리량 보장
3.3.2 대표 예시: Cassandra
- 특징: 노드 간 데이터 자동 분산/복제, 장애가 발생해도 무중단 운영 가능
- 장점
- 고가용성, 무중단 운영 (한 노드 장애 시에도 정상 처리)
- 빠른 쓰기 성능, 지리적으로 분산된 데이터센터 간 동기화 가능
- 특정 패턴의 대용량 데이터(로그, 타임시리즈 등)에 최적화
- 단점
- 스키마 설계가 독특해 초기 학습 곡선이 높음
- 복잡한 조인이나 조건 검색에 제약이 많음 (쿼리 모델링 먼저 고민해야 함)
3.3.3 사용 사례
- SNS, 메시지, 로그 저장: 선형 확장성과 빠른 쓰기 성능이 요구되는 서비스
- 분산 환경: 여러 리전에 걸쳐 글로벌 서비스를 운영할 때, 지연 시간 최소화
- 시간 순 데이터: 타임시리즈, 모니터링, IoT 센서 데이터 등
3.3.4 간단한 예시 코드 (CQL - Cassandra Query Language)
-- 1. 키스페이스(Keyspace) 생성
CREATE KEYSPACE IF NOT EXISTS myapp
WITH replication = {
'class': 'SimpleStrategy',
'replication_factor': '1'
};
USE myapp;
-- 2. 테이블 생성
CREATE TABLE users (
username TEXT PRIMARY KEY,
email TEXT,
created_at TIMESTAMP
);
-- 3. 데이터 삽입
INSERT INTO users (username, email, created_at)
VALUES ('alice', 'alice@example.com', toTimestamp(now()));
-- 4. 데이터 조회
SELECT * FROM users WHERE username = 'alice';
-- 5. 데이터 업데이트
UPDATE users
SET email = 'alice@newmail.com'
WHERE username = 'alice';
-- 6. 데이터 삭제
DELETE FROM users
WHERE username = 'alice';3.4 그래프(Graph) DB
3.4.1 개요 및 특징
- 노드(Node)와 엣지(Edge)로 데이터를 구성하여, 관계(relationship)에 최적화된 구조
- 소셜 네트워크, 추천 시스템, 네트워크 분석 등 연결 관계가 핵심인 서비스에서 강력함
- 그래프 쿼리 언어(Cypher 등)를 통해, 노드와 엣지의 연결 패턴을 빠르게 탐색
3.4.2 대표 예시: Neo4j
- 특징: Cypher 쿼리 언어를 통해, 복잡한 경로 탐색 및 패턴 매칭을 쉽게 수행
- 장점
- 깊은 관계 탐색(예: 친구의 친구, 추천 알고리즘)에 유리
- 시각화 도구를 통해 그래프 구조를 직관적으로 파악 가능
- JOIN 연산 없이 그래프 형태로 직접 연결
- 단점
- 일반적인 CRUD보다 관계 분석이 주가 되는 서비스가 아니면 과도한 선택
- 대규모 데이터 분산에 대한 노하우가 RDBMS/NoSQL 대비 적을 수 있음(최근 개선 중)
3.4.3 사용 사례
- 소셜 네트워크: 친구 관계, 팔로우/팔로잉 그래프
- 추천 시스템: 상품 추천, 경로 추천, 취향 분석
- 지식 그래프: 엔티티 간 연결 관계가 복잡한 도메인(의학, 학술연구 등)
3.4.4 간단한 예시 코드 (Cypher - Neo4j)
// 1. 노드 생성
CREATE (alice:Person { name: "Alice" })
CREATE (bob:Person { name: "Bob" });
// 2. 관계(엣지) 생성
MATCH (a:Person { name: "Alice" }), (b:Person { name: "Bob" })
CREATE (a)-[:FRIEND_OF]->(b);
// 3. 데이터 조회 - 관계 탐색
MATCH (p:Person)-[:FRIEND_OF]->(friend)
RETURN p.name AS Person, friend.name AS Friend;결론
1. SQL vs NoSQL
- SQL (RDBMS): 데이터의 일관성과 복잡한 관계를 유지해야 하는 시스템에 적합
- NoSQL: 빠르게 변하는 스키마, 대규모 트래픽, 수평 확장이 중요한 시스템에 적합
2. RDBMS 中 선택
- MySQL : 단순한 CRUD 중심의 애플리케이션, 중소규모 프로젝트에 적합
- PostgreSQL : 복잡한 쿼리와 분석, GIS 기반 서비스, 고급 SQL 기능이 필요한 프로젝트에 적합
- Oracle/MS SQL Server : 대규모 엔터프라이즈 환경, 고가용성과 강력한 보안이 필요한 시스템에 적합
3. NoSQL 中 선택
- 문서형 DB (MongoDB): 데이터 구조가 유연하고, 빠른 개발이 필요한 서비스에 적합
- 키-값 DB (Redis): 실시간 캐시, 세션 관리, 실시간 통계 등 빠른 응답이 필요한 시스템에 적합
- 컬럼 패밀리 DB (Cassandra): 대규모 분산 환경, 타임시리즈 데이터 관리에 최적화
- 그래프 DB (Neo4j): 관계 중심의 소셜 네트워크, 추천 시스템, 지식 그래프 등에서 강력
DB 선택... 프로젝트 설계 따라 고심 한번 해보면 좋을 것 같아요!
출처
https://www.quora.com/What-is-the-difference-between-SQL-NoSQL-MySQL-and-PostgreSQL
https://stackshare.io/stackups/mariadb-vs-mysql-vs-postgresql
https://fourwingsy.medium.com/graphql%EC%9D%84-%EC%98%A4%ED%95%B4%ED%95%98%EB%8B%A4-3216f404134


정말 많은 DB들이 있었네요. 프로젝트하면서 여러가지 써보면 좋을 것 같습니다.
잘 보고 갑니다.