코딩 테스트와 기초적인 파이썬 실력을 위해 공부중이던 자료구조와 알고리즘 관련 내용을 포스트하기로 결정하였다. 아무래도 남기는게 좋은 것....
공부 방식의 경우 프로그래머스 - 알고리즘 고득점 Kit의 내용을 기반으로 하였으며
1) 자료구조 / 알고리즘에 대한 간략한 설명
2) 해당 내용에 대한 여러가지 파이썬 구현 방식
3) 프로그래머스 문제 풀이
순서로 서술될 예정이다.
자료구조 / 알고리즘에 대한 간략한 설명
이번 주에는 가장 간단한 해시 구조부터 살펴보자.
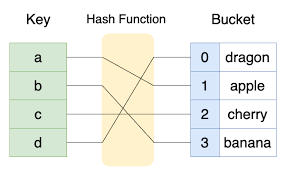
본래 해시 구조란 "데이터를 빨리 찾기 위한 자료구조" 이다.
이를 구현하기 위해 해시 구조에서 각각의 데이터는 별도의 "key" 값을 갖고, 이 key를 받아 정수으로 변환해주는 별도의 "해시 함수"를 이용하여 고유한 해시값을 계산, 이 해시값으로 데이터에 접근하는 보안이 돋보이는 구조를 가지고 있다.
기존 인덱싱 방식으로 데이터를 찾는 것과 다르게 이 해시 구조는 해시값-데이터를 저장해놓은 별도의 해시 테이블에서 해시값을 인덱스로 사용, 데이터의 주소를 찾기에 전체 메모리를 뒤지는 다른 방식들보다 압도적으로 빠른 성능을 보일 수 있는 것이다.
해시 테이블은 해시 구조의 key 값을 해시 함수에 넣어 나온 정수 값을 인덱스로, 해당하는 데이터의 실제 메모리 주소를 그 값으로 가지는 구조이다.
위 구조에 의해 해시 구조에서의 데이터 탐색, 삽입 및 삭제는 O(1)의 시간 복잡도를 가지게 된다.
파이썬에서는 딕셔너리 구조가 내부적으로 위 메커니즘을 따르므로 해시 구조 = 딕셔너리 라고 생각해도 될 법하다.
여러가지 파이썬 구현 방식
1) 딕셔너리 이용
당연하게도 해시 구조를 파이썬 환경에서 이용하기 위한 가장 간단한 방법은 딕셔너리를 그대로 사용하는 것이다.
이중 딕셔너리나 리스트를 value로 가지는 딕셔너리 등은 별도로 서술하지 않겠다.
2) hash 함수 이용
두 번째 방법은 기존 해시 구조의 특성을 파이썬에서 다시금 구현하는 것이다. 파이썬에서는 기본 내장 함수 hash를 통해 이 기능을 제공한다. 그 설명을 살펴보자.
hash(obj, /)
Return the hash value for the given object.object 타입, 어떤 자료형이든 입력으로 받아 고유한 정수값을 뱉어주는 함수이다.
이걸 어떻게 쓸 수 있을까 ?
# 참가자와 탈락자들의 명단
참가자들 = ["홍길동", "이순신", "뷁뷁뷁"]
탈락자들 = ["홍길동", "이순신"]
total_hash = 0
전체명단 = {}
for 참가자 in 참가자들:
total_hash += hash(참가자)
전체명단[hash(참가자)] = 참가자
for 탈락자 in 탈락자들:
total_hash -= hash(탈락자)
print(전체명단[total_hash])
>>> 뷁뷁뷁이처럼 고유 알고리즘에 의해 해시값은 동일 결과에 한하여 항상 같은 정수값을 내놓는다는 점을 이용, "전체 해시값의 합"을 별도로 관리하는 응용을 생각해 볼 수 있겠다.
딕셔너리에 접근하는 횟수를 줄여준다는 점에서 장점을 가지고는 있지만... 딕셔너리 자체가 데이터 접근이 워낙 빨라서 유용한지는 잘 모르겠다.
3) collections.Counter 클래스 이용
파이썬에서는 리스트, 딕셔너리 등 기본적인 자료구조의 한계를 보완해놓은 collections 라는 별도의 내장 라이브러리가 존재한다. 그 중 Counter 클래스에 대해 알아보자.
Counter 클래스는 "횟수"를 세는 딕셔너리 이다.
기존 딕셔너리에서 발전된 자료형으로 (key, value) 의 자료구조를 가지지만 value 값이 의미하는 바가 "key 값의 등장 빈도" 라는 점에서 독특하다.
이를 본래 구현하기 위해서는 딕셔너리의 키 값에 접근, 존재하지 않을 경우 1로 저장하고 존재할 경우 +1을 하는 번거로운 과정이 필요했다.
그 간단한 사용법을 살펴보자.
import collections
lst = [1, 2, 3, 4, 5, 2, 3, 5, 4, 3, 1, 3, 4, 2]
ct = collections.Counter(lst)
ct2 = collections.Counter(lst)
print(ct)
>>> Counter({3: 4, 2: 3, 4: 3, 1: 2, 5: 2})
# 본래라면 dict.get(key, -1) 을 이용해 키 값 존재 여부 확인 후 없으면 새로 생성, 있으면 +1 을 전부 해줬어야 해.
# most_common() : 등장 순서가 높은 순으로 튜플로 이루어진 리스트 반환
print(ct.most_common())
>>> [(3, 4), (2, 3), (4, 3), (1, 2), (5, 2)] # (key, value) 형식
# update(), subtract() : 새로운 key 값을 하나씩 추가/삭제 -> key가 없어지지는 않아, 음수값도 가능함
ct.update([1, 3, 2])
ct.subtract([3, 3, 3, 3 ,3, 3])
print(ct)
>>> Counter({2: 4, 1: 3, 4: 3, 5: 2, 3: -1})
# 연산자 사용 가능 : +, -, &, | -> 합집합, 교집합, 차집합이기에 집합 자체가 바뀌어
print(ct+ct2) # 두 횟수를 더해 (합)
>>> Counter({2: 7, 4: 6, 1: 5, 5: 4, 3: 3})
print(ct-ct2) # 두 횟수를 빼 (차집합) / 단, 음수값도 존재
>>> Counter({1: 1, 2: 1})
print(ct&ct2) # 두 횟수에 모두 포함 (교집합)
>>> Counter({2: 3, 4: 3, 1: 2, 5: 2})
print(ct|ct2) # 두 횟수 중 하나에 포함 (합집합)
>>> Counter({2: 4, 3: 4, 1: 3, 4: 3, 5: 2})이처럼 입력된 Iterable을 간단히 넣어주는 것만으로 원하는 딕셔너리 구조를 형성할 수 있으며 이들간의 여러 집합 계산과 순서 계산은 굉장히 유용하게 사용된다.
4) collections.defaultdict 클래스 이용
유사하게 collections 에는 defaultdict라는 클래스도 존재한다. 딕셔너리 사용 시 가장 걸리적거리는 부분 중 하나가 존재하지 않는 키 값으로 접근 시 오류가 발생한다는 점이며, dict.get(value, defaultvalue) 등의 표현을 통해 키 값 존재를 확인하는 단계가 필요했다.
이 부분을 간단하게 보완한 것이 defaultdict 이다.
defaultdict 클래스는 "기본값을 가지는 딕셔너리" 이다.
필요한 것은 오직 호출 시 기본값을 만들어주는 callable 뿐이다.
간단한 사용법만 살펴보고 넘어가자.
import collections
dct_int = collections.defaultdict(int) # 초기값 0
dct_list = collections.defaultdict(list) # 초기값 []
dct_str = collections.defaultdict(str) # 초기값 ""
dct_int["key"] += 2
dct_list["key"].append(2)
dct_str["key"] += "asdf"
print(dct_int)
>>> defaultdict(<class 'int'>, {'key': 2})
print(dct_list)
>>> defaultdict(<class 'list'>, {'key': [2]})
print(dct_str)
>>> defaultdict(<class 'str'>, {'key': "asdf"})위처럼 존재하지 않는 키 값에 접근하여 바로 작업을 할 수 있다는 것이 큰 장점이다. 내부적으로는 없는 키 값에 접근 시 초기에 주어진 callable을 호출하여 기본값을 설정하므로 __call__이 정의되어있는 모든 자료형 함수와 커스텀 함수도 사용이 가능하다.
5) collections.OrderedDict 클래스 이용
딕셔너리는 키 값이 존재하지 않으면 접근이 불가능하다는 점 외에도 내부 순서를 마음대로 조정하지 못한다는 단점도 가지고 있다. 오로지 키 값에 의존해서만 요소에 접근할 수 있다는 점은 생각보다 불편하다.
이 부분을 보완한 것이 OrderedDict 클래스이다.
OrderedDict 클래스는 "순서를 가진 딕셔너리"이다.
기존dict자료형 역시 순서를 기억하기는 하기에 조금 더 명확히는 순서를 다룰 수 있는 딕셔너리라고 하는 것이 맞겠다.
그 사용법을 살펴보자.
import collections
# OrdredDict 객체 생성
## 기존 딕셔너리도 순서를 이용하지 못할 뿐 기억은 하도록 설계되었기에 그냥 넘겨줘도 되고 새로 추가해도 괜찮다.
dt = {"a":1, "b":2, "c":3}
od = collections.OrderedDict(dt)
od
>>> OrderedDict([('a', 1), ('b', 2), ('c', 3)])
# 위치 변환
## move_to_end(last=True) 메소드를 이용하여 특정 요소를 마지막 / 첫 순서로 이동시킬 수 있다.
od.move_to_end("b")
od
>>> OrderedDict([('a', 1), ('c', 3), ('b', 2)])
od.move_to_end("c", last=False)
od
>>> OrderedDict([('c', 3), ('a', 1), ('b', 2)])
# 큐 구조 구현_FIFO
## popitem(last=True) 메소드를 이용하여 마지막 / 첫 요소를 뽑아낼 수 있다.
jobs = {"job1":"1hour", "job2":"2hour", "job3":"3hour"}
od2 = collections.OrderedDict(jobs)
while od2:
# 리스트의 pop()과 동일, 가장 마지막 요소 제거 및 반환 / (key, value)의 튜플 형식으로 반환
job, job_time = od2.popitem()
print(job, job_time)
>>> job3 3hour
job2 2hour
job1 1hour
# 스택 구조 구현_LIFO
od3 = collections.OrderedDict(jobs)
while od3:
# last 매개변수를 통해 첫 요소 제거 및 반환
job, job_time = od3.popitem(last=False)
print(job, job_time)
>>> job1 1hour
job2 2hour
job3 3hour처음 이 클래스의 존재를 알게 되었을 때는 마치 딕셔너리+리스트의 느낌으로 각 요소에 key로도 접근하고 index로도 접근이 가능한 클래스인 줄 알았지만 실상은 그렇지 않았다.
그저 특정 요소를 처음이나 끝으로 밀거나 처음이나 끝에서 요소를 꺼내는 것 뿐.... 리스트의 .pop(index=-1) 처럼 인덱스 조정도 불가능하고 생각보다는 제한적인 부분이 많은 것 같다.
그치만 큐 / 스택 구조를 구현하기에는 더할 나위가 없으므로 필요한 순서대로 OrderedDict에 삽입해주기만 한다면 굉장히 편리한 도구가 될 법도 하겠다 !
프로그래머스 문제 풀이
그럼 이제 프로그래머스-알고리즘 고득점 Kit-해시 에 있는 문제를 풀어보자. 문제 설명은 가볍게 넘기겠다.
1) 완주하지 못한 선수 Lv.1
참가자 명단과 완주자 명단을 받아 완주하지 못한 선수를 찾는 문제.
def solution(participant, completion):
answer = {}
# 해시 테이블 생성
for part in participant:
if not answer.get(part): # 없으면 None 반환
answer[part] = 1
else:
answer[part] += 1
# 키 값 하나씩 제거
try:
for comp in completion:
if answer[comp] == 1:
answer.pop(comp)
else:
answer[comp] -= 1
except:
return comp
return list(answer.keys()).pop()
solution(["marina", "josipa", "nikola", "vinko", "filipa"], ["josipa", "filipa", "marina", "nikola"])
>>> 'vinko'
가장 처음 푼 방식이다. 정직하게 읽히는 대로 풀었다.
# collections 이용해보기
from collections import Counter
def solution2(participant, completion):
# 차집합으로 key 하나 남김
ct = Counter(participant) - Counter(completion)
return ct.most_common()[0][0]횟수를 세어주는 Counter 클래스를 이용한 방식이다. .most_common() 메소드는 횟수가 많은 순부터 (key, value) 꼴의 튜플로 이루어진 리스트를 반환한다는 점.
# hash 함수 이용해보기
## 해시값은 역으로 변환이 불가능함
## 해시값은 엄청 긴 고유 실수이다.... -> "실수 연산" 으로 해결해야해
def solution3(participant, completion):
answer = 0; dic = {}
for part in participant:
answer += hash(part)
dic[hash(part)] = part
answer -= sum(hash(comp) for comp in completion)
return dic[answer]파이썬 기본 내장 함수인 hash 함수를 이용해서도 풀어보았다. 이게 더 유리한 경우가 있을까....? 보안상의 이유로 키 값을 변환하여 보관하는 것이 아니면.... 음냐
2) 폰켓몬 Lv.1
경우에 따라 가져갈 수 있는 폰켓몬의 수를 구하는 문제.
def solution(nums):
return min(len(set(nums)), len(nums)//2)
solution([3,3,3,2,2,4])
>>> 3확실히 lv.1 들은 꼬여있지 않은 느낌이다.
3) 전화번호 목록 Lv.2
전화번호부를 보고 한 번호가 다른 번호의 접두어가 되는지 확인하는 문제.
def solution(phone_book):
prefix = phone_book[0]
phone_book.sort() # 기본방식이 사전식정렬
for phone in phone_book[1:]:
if phone.startswith(prefix):
return False
prefix = phone
return True
solution(["119", "97674223", "1195524421"])
>>> False해시 문제이지만.... 해시로 풀지는 않았다. 너무 비효율적인 것 같아서....
4) 의상 Lv.2
여러 옷을 통해 만들어 낼 수 있는 전체 패션 경우의 수를 구하는 문제.
def solution(clothes):
cate_cloth = {}; answer = 1
# 자료 구조 생성
for cloth, category in clothes:
if not cate_cloth.get(category): # 없는 카테고리
cate_cloth[category] = 1
else: # 있는 카테고리
cate_cloth[category] += 1
# 계산
for length in cate_cloth.values(): # dict 자료형 for 구문 돌리기
answer *= length+1
return answer-1
solution([["yellow_hat", "headgear"], ["blue_sunglasses", "eyewear"], ["green_turban", "headgear"]])
>>> 5처음 푼 방식이다. 주어진 옷들을 각 카테고리별로 나눠야 하기에 카테고리를 키 값으로 하는 해시 구조를 이용하였다.
그러나 앞서 말했듯 딕셔너리의 키 값이 존재하지 않는 경우 별도의 처리가 필요하다는 번거로움이 존재한다. 이럴 때 ?
# defaultdict 이용하기
from collections import defaultdict
def solution(clothes):
cate_cloth = defaultdict(int); answer = 1
# 자료 구조 생성
for cloth, category in clothes:
cate_cloth["category"] += 1
# 계산
for length in cate_cloth.values():
answer += length+1
return answer - 1불필요한 코드 블록이 제거되어 훨씬 깔끔해진 모습이다.
5) 베스트 앨범 Lv.3
대망의 해시 구조의 마지막 문제이다. 가장 많이 재생된 장르 순서대로 재생 횟수 TOP 2를 수록하는 문제이다.
from collections import defaultdict
def solution(genres, plays):
answer = []
genre_totalplays = defaultdict(int) # (장르, 장르별 총 재생 횟수)
genre_songs = defaultdict(list) # (장르, [(노래 번호, 재생 횟수)])
for i, (g, p) in enumerate(zip(genres, plays)):
genre_totalplays[g] += p
genre_songs[g].append((i, p))
print(genre_totalplays)
>>> defaultdict(<class 'int'>, {'classic': 1450, 'pop': 3100})
print(genre_songs)
>>> defaultdict(<class 'list'>, {'classic': [(0, 500), (2, 150), (3, 800)], 'pop': [(1, 600), (4, 2500)]})
for genre in sorted([g for g in genre_totalplays.keys()], key=lambda x: genre_totalplays[x], reverse=True):
for i, (song, _) in enumerate(sorted(genre_songs[genre], key=lambda x: x[1], reverse=True)):
if i >= 2: break
answer.append(song)
return answer
solution(["classic", "pop", "classic", "classic", "pop"], [500, 600, 150, 800, 2500])
>>> [4, 1, 3, 0]편의성을 위해 defaultdict 클래스를 이용, 장르별 재생 횟수를 담은 딕셔너리와 각각의 노래 번호와 재생 횟수를 담은 딕셔너리를 별도로 구현하여 풀었다.
zip() 이나 sorted(iterable, key=None, reverse=False) 는 여전히 너무나 유용하다.... 이 문제에서 OrderedDict 클래스를 활용해보고 싶었지만 sorted 가 너무 유용한 나머지 손을 댈 수가 없었다.... 언제 쓰지 대체...?
아마 딕셔너리 클래스를 유지하면서 값들을 하나 하나 큐/스택으로 빼내는 알고리즘에서 유용할 듯 싶은데 아직은 감이 잡히지 않는다.
