1. ArrayList vs LinkedList
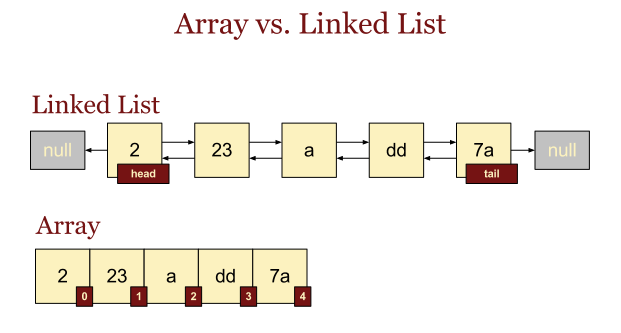
사진 출처 : http://changpd.blogspot.com/2014/08/arraylist-linkedlist-java.html
ArrayList 는 index가 있고, LinkedList는 각 원소마다 앞, 뒤 원소의 위치 값을 가지고 있다. (내부적으로 양방향의 연결 리스트. 참조하려는 원소에 따라 처음부텉 정방향 또는 역순으로 순회 가능)
💡
ArrayListvs 일반 배열
ArrayList는 기본적으로 배열을 사용하지만 일반 배열과는 다르다.
일반 배열은 처음에 메모리를 할당할 때 크기를 지정해주지만, ArrayList는 크기를 지정하지 않고 동적으로 값을 삽입하고 삭제할 수 있다.
조회/삽입/삭제
1) 조회
ArrayList는 LinkedList와 달리 각 데이터의 idx를 가지고 있고 무작위 접근이 가능하기 때문에 해당 idx의 데이터를 한 번에 가져올 수 있다.
LinkedList는 순차적 접근이기 때문에 검색의 속도가 느리다.
2) 삽입
가장 끝 인덱스에 삽입
ArrayList 와 LinkedList 모두 O(1)의 시간복잡도를 가지지만, ArrayList 의 경우 삽입시 공간이 가득 찰 경우 공간을 1.5배로 할당해주는 더블링이 일어나고, 이럴 경우에는 O(n)의 시간복잡도가 소요됩니다.
인덱스 중간에 삽입
ArrayList는 데이터를 삽입, 삭제하고 새로운 공간에 나머지 데이터들을 복사해주어야 하기 때문에 O(n)
LinkedList는 탐색하는 데 O(n)의 시간복잡도. 실제 삽입 행위는 노드끼리 연결만 처리해주면 되므로 O(1)의 시간복잡도. 결론적으로 O(1) * O(n) = O(n)
💡 DETAIL
LinkedList의 경우 Node를 선언하는 등 객체를 생성하고 메모리를 할당해야하는 비싼 작업이 수행되기 때문에 실제 수행시간에서 차이가 발생하게 됩니다. (O(1)에서 생략된 상수항의 매우 크다) “new” 연산은 항상 큰 부담!!
3) 삭제
ArrayList는 삭제한 만큼 자리를 맞춰주는 과정이 필요하기 때문에 O(n)
LinkedList는 가리키고 있는 주소 값만 변경해주면 되기 때문에 ArrayList에 비해 효율적 → 경우에 따라 다르다.
💡 DETAIL
삭제 연산 역시 시간복잡도는 O(n)로 둘다 동일하지만, 실제 수행시간에서는 큰 차이
ArrayList는 삭제 이후 나머지 엘리먼트들을 모두 복사하는 꽤 비싼작업을 O(n)으로 실행하기에 시간이 오래 걸릴 수 밖에 없지만,
LinkedList의 경우 비교적 비용이 적게드는 탐색에 O(n)가 소요되고 실제 삭제 연산은 노드의 연결만 바꿔주면 되기에 O(1)이 소요됩니다.
💡 순차적으로 추가/삭제하는 경우 ArrayList가 LinkedList보다 빠르다
큰 차이는 아니지만,
처음 또는 마지막 데이터부터 순차적으로 데이터를 쭉 삭제하면 각 요소들의 재배치가 필요하지 않기 때문에 ArrayList도 빠르다.
💡 중간 데이터(비순차적)를 추가/삭제하는 경우 LinkedList가 ArrayList보다 빠르다.
중간 요소를 추가/삭제 하는 경우, LinkedList 는 각 노드 간 연결만 변경해주면 되기 때문에 처리 속도가 빠르다. ArrayList는 각 요소들을 재배치해 추가할 공간을 확보하거나 빈 공간을 채워야하기 때문에 처리속도가 늦다.
결론
비슷한 시간 복잡도라도 ArrayList는 인덱스 끝에서의 삽입과 삭제가 빠르고, LinkedList는 인덱스 중간에서의 삽입과 삭제가 빠르다.
로직상 배열의 끝에 삽입할 경우가 많다면 LinkedList 보다는 ArrayList를 사용하고, 배열의 중간 값을 삭제할 경우가 많다면 LinkedList를 사용하자!
2. Thread Safe 란
Multi-Thread 상황에서 함수, 변수, 객체에 동시 접근이 발생해도 프로그램 실행에 문제가 되지 않는 것을 의미
Java에서 Thread Safe를 유지하는 방법
- Confinement(제한)
지역 변수는 각 스레드의 자체 스택에 저장되고, 스택은 고유한 영역으로 동시접근이 발생하지 X
- Immutable(불변)
변수에 변경 불가능한 참조를 사용 ex. private final
데이터를 바꿀 수 있는 setter 메소드를 쓰지 않도록 작성
- Thread-safe한 자료구조 사용
-
thread-safe하지 않은 자료 구조 :
List,Set,Map,ArrayList,HashSet,HashMap등 -
멀티 스레딩 환경에서 사용할만한 thread-safe한 자료구조 :
Vector,Hashtable,Collections.synchronizedXXX
ex1
List<String> list = Collections.synchronizedList(new ArrayList<String>());
private static Map<Integer,Boolean> cache = Collections.synchronizedMap(new HashMap<>());ex2
public static synchronized void add(int value){
count += value;
}스레드가 synchronized 자료구조에 접근하면 lock 을 걸고 다른 스레드의 접근을 제한한다.
그러나 lock으로 인해 병렬적 요소를 처리할 수 없다면? 따라서, ConcurrentXXX를 사용한다.
3+ Concurrent
‘java.util.concurrent’ 패키지에 담겨 있다.
Map<K,V> map = new ConcurrentHashMap<K,V>();
Queue<E> queue = new ConcurrentQueue<E>();Concurrent 자료구조를 사용하면 동시 작업할 수 있는 스레드의 양을 설정할 수 있다.
전체적인 동시성 처리를 제공하는 synchronized에 비해 아주 작은 단위에서 동시성 처리를 제공한다.
read와 write를 구분하여 synchronized 보다 효율적인 처리를 진행한다.
병렬성을 최대한 확보한 자료구조다.
