MyBatis 등으로 RDBMS에 직접 쿼리 작성이 익숙한 인간이라서 JPA 엔티티가 조금만 복잡해져도 ORM과 RDBMS의 패러다임 불일치 때문에 원하는대로 테이블을 정규화하기 까다로웠다.
때문에 성능이나 N+1 등의 문제와는 별개로 JPQL로 직접 쿼리를 작성했었다.
조금은 원할하게 원하는대로 (+객체지향적으로) 테이블을 설계하고 JPA로 구현된 로직을 좀 더 쉽고 구체화 할 수 있도록 정리할 필요를 느꼈다.
테이블 설계
엔티티를 구성해보기 위해, DB에 직접 여러 연관관계가 있는 DB테이블을 먼저 설계해본다.
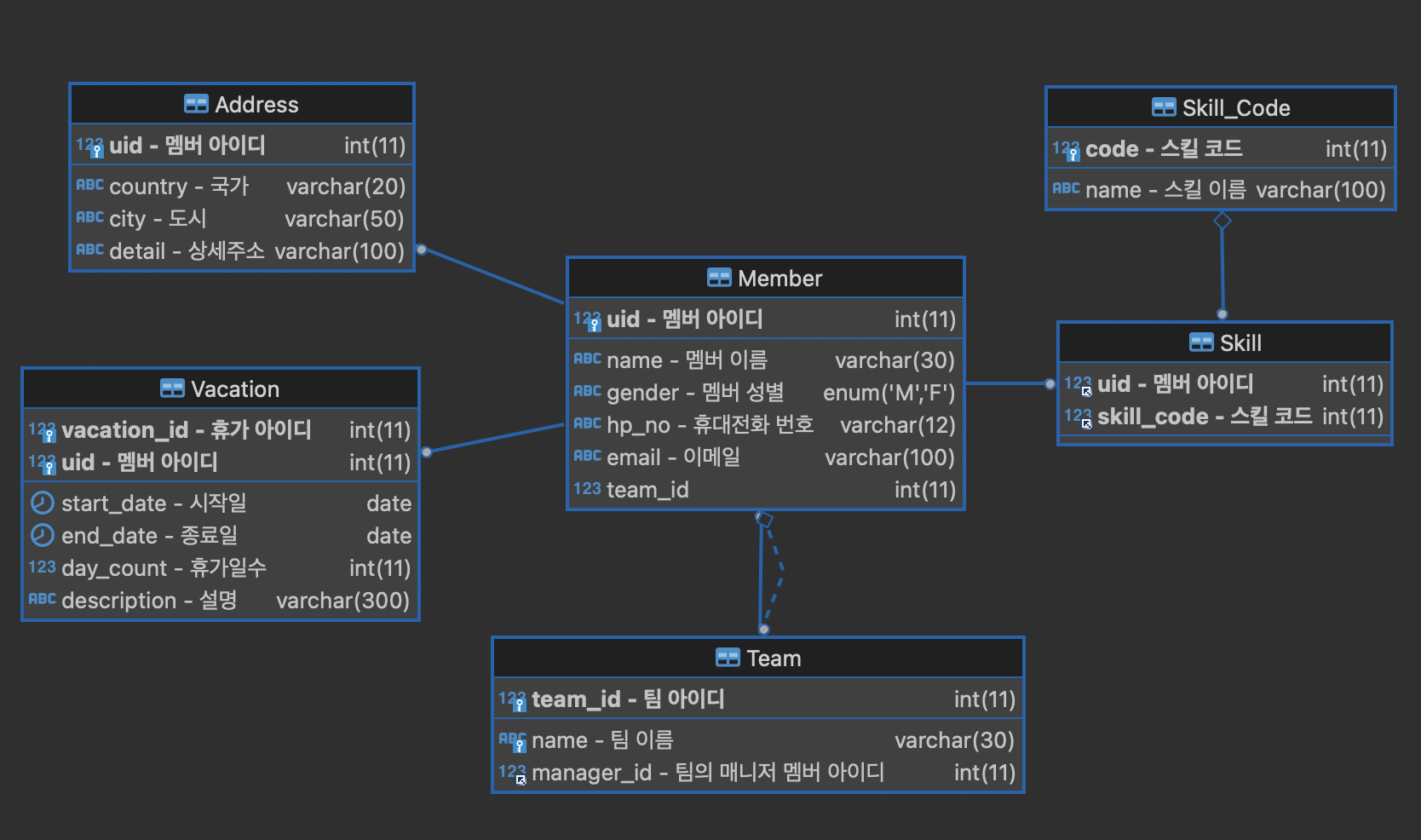
위 그림으로 멤버기준 연관관계를 맺는다.
- Address 테이블 (OneToOne)
멤버 한명 당 하나의 주소를 갖는다. - Team 테이블 (OneToMany/ManyToOne)
멤버 한명 당 하나의 팀을 가지지만, 팀은 여러 멤버를 갖는다. - Skill 테이블 (ManyToMany)
멤버는 여러개의 스킬을 가질 수 있고, 스킬 또한 여러 멤버를 가질 수 있다.
번외 : Vacation 테이블은 복합키로 구성한다.
OneToOne
1:1 연관관계이다. 연관관계를 맺는 키가 있는 곳이 주인이 되기 때문에
이 경우에 Member 엔티티에 선언해준다.
JoinColumn을 통해서 조인될 컬럼을 선언해줄 수 있다.
name은 선언되는 Member의 조인될 컬럼이며
referencedColumnName은 Address 엔티티의 조인될 컬럼이다.
(쉽게 SQL에서 name은 FROM절의 컬럼, referencedColumnName은 JOIN ON절의 컬럼)
@Entity
@Getter
@Table(name = "Member")
public class Member {
@Id
int uid;
String name;
char gender;
String hp_no;
String email;
@OneToOne(cascade = CascadeType.ALL)
@JoinColumn(name = "uid", referencedColumnName = "uid")
private Address address;
}CascadeType
부모, 자식 간의 영속성을 설정하는 옵션 중 하나인 CascadeType.ALL을 선언해준 이유는 Address와 Member가 1:1 관계를 맺고 있고 데이터 무결성을 유지하기 위해 사용되었다.
멤버는 하나의 주소를 가지고 있고 그 반대의 경우도 마찬가지이기 때문에 멤버 엔티티의 저장, 수정, 삭제 시 자식 엔티티(또는 자식 테이블)도 저장, 수정, 삭제가 일어나게 만든다.
ALL 외에도 세부적으로 다른 CascadeType 옵션들이 있다.
- CascadeType.PERSIST
부모 엔티티가 영속상태가 되면 자식 엔티티도 영속 상태가 되도록 한다.
ALL과 다른점은 부모 엔티티가 저장될 때 자식 엔티티를 함께 저장하지만,
삭제될 때는 자식 엔티티는 삭제되지 않는다.
즉 생성될 때(Transient 상태)만 영속성을 전이한다. - CascadeType.MERGE
병합(또는 수정)이 부모 엔티티에서 일어나게 된다면 자식 엔티티에서도 변경이 일어난다.
위 예시에서 멤버의 uid 값이 변경되면 Address의 uid 또한 같은 값으로 변경된다. - CascadeType.REMOVE
마찬가지로 부모 엔티티가 삭제 시, 자식 엔티티도 삭제된다.
위 예시에서 멤버의 uid가 10인 값을 삭제한다면,
자식 엔티티인 Address에서 또한 uid가 10인 엔티티가 삭제된다.
실행쿼리 (단방향)
- 단건조회쿼리
SELECT member0_.uid as uid1_1_,
member0_.email as email2_1_,
member0_.gender as gender3_1_,
member0_.hp_no as hp_no4_1_,
member0_.name as name5_1_
FROM Member member0_
WHERE member0_.uid = ?
---
SELECT address0_.uid as uid1_0_0_,
address0_.city as city2_0_0_,
address0_.country as country3_0_0_,
address0_.detail as detail4_0_0_
FROM Address address0_
WHERE address0_.uid = ?- 전체조회쿼리 (FindAll)
SELECT member0_.uid as uid1_1_0_,
address1_.uid as uid1_0_1_,
member0_.email as email2_1_0_,
member0_.gender as gender3_1_0_,
member0_.hp_no as hp_no4_1_0_,
member0_.name as name5_1_0_,
address1_.city as city2_0_1_,
address1_.country as country3_0_1_,
address1_.detail as detail4_0_1_
FROM Member member0_
LEFT
OUTER
JOIN Address address1_
ON member0_.uid = address1_.uid단건조회는 왜 두개의 쿼리가 실행되는가
단건조회라도 하나의 쿼리로 불러오는게 효율적이라고 생각했다.
하지만 연관 엔티티 수(N) 만큼 쿼리를 실행시키는게 더 효율적인 경우가 있어
JPA는 N개의 쿼리를 더 실행한다.
- 필드가 많은 경우
모든 연관관계를 포함한 하나의 쿼리는 DB에 부하를 줄 수 있다.
만약 필드가 많고 연관된 엔티티들이 복잡한 경우, 데이터베이스의 부담이 커질 수 있다.
- 캐시의 효율을 위해
JPA는 따로 설정해주지 않아도 영속성 컨텍스트(Persistence Context)를 통해 엔티티를 관리하고 캐시 기능을 제공한다.
이 기능으로 자주 사용되는 데이터가 저장되어 성능을 향상시킬 수 있는데
하나의 쿼리로 JOIN을 통해 모든 연관관계의 정보를 불러온다면
캐시 메모리의 효율성이 낮아지는 원인이 될 수 있다.
물론 연관관계만큼 N개의 쿼리를 더 실행하는 것이 항상 효율적인건 아니다. (ex. N+1)
기타 성능문제로 한번의 쿼리만 실행시키고 싶다면 JPQL이나 EntityManager의 createNativeQuery 메소드 등을 사용해야 한다.
InvalidDefinitionException
에러 내용)
com.fasterxml.jackson.databind.exc.InvalidDefinitionException:
No serializer found for
class org.hibernate.proxy.pojo.bytebuddy.ByteBuddyInterceptor
and no properties discovered to create BeanSerializer
(to avoid exception, disable SerializationFeature.FAIL_ON_EMPTY_BEANS)
(through reference chain: com.study.Entity.Team["manager"]->
com.study.Entity.Member$HibernateProxy$VjcA2Ldi["hibernateLazyInitializer"])일단 Team의 manager는 Member와 OneToOne 연관관계이다.
멤버아이디를 입력받아 매니저도 설정할 수 있다고 가정했을때, 저런 예외를 마주칠 수 있다.
일단 이 예외가 일어나는 이유는 입력데이터가 팀의 이름과, 매니저의 아이디라고 할 때,
getReferenceById로 Member객체를 가져온다면, 이 객체는 프록시 객체이다.
이 때, JSON 객체로 직렬화할때,
프록시 객체(Entity.Member$HibernateProxy$VjcA2Ldi)이기 때문에 직렬화를 할 수 없기 때문이다.
그래서 엔티티 자체를 반환하지 않고 DTO 클래스로 변환해서 반환한다면 저런 예외는 일어나지 않는다.
또는 위 에러의 설명처럼 disable SerializationFeature.FAIL_ON_EMPTY_BEANS 처리를 해주거나 getReferenceById이 아니라 findById 등의 메소드를 사용한다면 이 경우에서 저런 예외는 일어나지 않는다.
양방향 연관관계
위 예시는 Member에서 Address를 단방향으로 참조하고 있었다.
즉, 주소를 조회하면 그 주소와 1:1 관계인 멤버는 확인할 수 없다는 뜻이다.
그런데 Address를 조회해도 Member에 대한 정보도 조회되게 하고 동시에 그 반대도 가능하게 하고싶다면?
무한 루프에 빠지게 된다.
(Member의 Address필드 참조 -> Address에서 Member의 참조 -> 반복...)
가장 쉬운 방법은 엔티티에 @JsonIdentityInfo 를 붙여서 객체 식별자를 통해 중복을 방지하는 방법이 있다.
때문에 @id 정보가 추가된 것을 확인 할 수 있다.
(클라이언트에게 전달할 때는 DTO로 감싸서 보이지 않게 해주자)
예시)
@JsonIdentityInfo(generator = ObjectIdGenerators.IntSequenceGenerator.class)
public class Member {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
int uid;
// ... 생략
@OneToOne(cascade = CascadeType.ALL)
@JoinColumn(name = "uid", referencedColumnName = "uid")
private Address address;
}
...
@JsonIdentityInfo(generator = ObjectIdGenerators.IntSequenceGenerator.class)
public class Address {
@Id
int uid;
// ... 생략
@OneToOne(mappedBy = "address")
@JoinColumn(name = "uid", referencedColumnName = "uid")
private Member member;
}무한루프를 방지하지만, Address를 전체조회한다면 N+1 문제가 생긴다.
JPQL의 JOIN FETCH를 사용해서 해결하자
@Query("SELECT a FROM Address a JOIN FETCH a.member")
List<Address> findAll();공유 PK 사용
Member와 Address 각각 uid 라는 공유 PK를 사용할 때 저장 시, 상황에 따라 같은 PK값으로 들어가지 않을 수 도 있다.
실제로 위 코드에서 Member와 Address를 동시에 저장했을때 Member 테이블에는 uid가 1, Address에는 0가 들어가서 데이터 무결성이 깨질 수 있다.
(데이터베이스에서 생성된 시퀸스가 각각의 엔티티마다 +1이 되기 때문이며 Address에는 @GeneratedValue가 선언되지 않았기 때문)
만약 멤버가 저장될 때, 주소가 필수이면서, 테이블이 따로 나뉘어져 저장되게 하고싶다면 Member에서 생성된 같은 값의 PK가 Address에도 들어가게 설정해줘야 한다.
부모의 PrimaryKeyJoinColumn은 OneToOne관계에서 PK로 조인되게 하는 옵션이며,
MapsId는 PK를 FK로 사용하는 옵션이다.
때문에 @MapsId를 사용할 경우에는 @JoinColumn과 달리 외래키를 생성하는 것이 아니라, 같은 값을 공유하는 기본키를 사용하므로 외래키 제약조건이 생성되지 않을 수 있다.
실제로 데이터베이스에 저장될 때는 Address 엔티티에서 @Id로 선언한 uid가 아니라 JPA 구현체에서 자동으로 생성하는 외래 키 이름 규칙에 따라서 member_uid로 저장된다.
저장 시 양방향 연관관계를 가지고 있음으로 Member의 필드인 Address에도 Member를 설정해줘야 한다.
결과
@Entity
@Getter
@Table(name = "Member")
@JsonIdentityInfo(generator = ObjectIdGenerators.IntSequenceGenerator.class)
public class Member {
@Id
@GeneratedValue(strategy = GenerationType.SEQUENCE)
int uid;
String name;
char gender;
String hp_no;
String email;
@OneToOne(cascade = CascadeType.ALL, fetch = FetchType.EAGER)
@PrimaryKeyJoinColumn
private Address address;
}
@Entity
@Getter
@Table(name = "Address")
@JsonIdentityInfo(generator = ObjectIdGenerators.IntSequenceGenerator.class)
public class Address {
@Id
int uid;
String country;
String city;
String detail;
@OneToOne(mappedBy = "address")
@MapsId
private Member member;
public void setMember(Member member) {
this.member = member;
}
}
// service
public Member saveMember(Member member){
member.getAddress().setMember(member);
return memberRepo.save(member);
}- 멤버 조회 결과
{
"uid": 1,
"name": "Karina",
"gender": "F",
"hp_no": "010-1111-2222",
"email": "karina@aespa.com",
"address": {
"uid": 1,
"country": "Korea",
"city": "Seoul",
"detail": "Yongsan-gu",
"member": 1
}
}- 멤버 조회시 실행되는 쿼리
SELECT member0_.uid as uid1_1_0_,
address1_.member_uid as member_u4_0_1_,
member0_.email as email2_1_0_,
member0_.gender as gender3_1_0_,
member0_.hp_no as hp_no4_1_0_,
member0_.name as name5_1_0_,
member0_.team_id as team_id6_1_0_,
address1_.city as city1_0_1_,
address1_.country as country2_0_1_,
address1_.detail as detail3_0_1_
FROM Member member0_
INNER
JOIN Address address1_
ON member0_.uid = address1_.member_uid- 주소 조회 결과
{
"uid": 1,
"country": "Korea",
"city": "Seoul",
"detail": "Yongsan-gu",
"member": {
"uid": 1,
"name": "Karina",
"gender": "F",
"hp_no": "010-1111-2222",
"email": "karina@aespa.com",
"address": 1
}
}- 주소 조회시 실행되는 쿼리
SELECT address0_.member_uid as member_u4_0_0_,
member1_.uid as uid1_1_1_,
address0_.city as city1_0_0_,
address0_.country as country2_0_0_,
address0_.detail as detail3_0_0_,
member1_.email as email2_1_1_,
member1_.gender as gender3_1_1_,
member1_.hp_no as hp_no4_1_1_,
member1_.name as name5_1_1_,
FROM Address address0_
INNER
JOIN Member member1_
ON address0_.member_uid = member1_.uid"member": 1, "address": 1 각각의 의미는 연관관계에 있는 엔티티의 PK이다.
공유PK 를 사용하지 않는 Team의 manager_id와 Member의 uid는
Team -> Member 단방향으로 설정되어도 무방함으로@Entity public class Team { //... 생략 @OneToOne @JoinColumn(name = "manager_id") Member manager; }팀 엔티티에만 설정하도록 하자
OneToMany / ManyToOne
1:N 관계에는 한 팀은 여러멤버를 가지고 한 멤버는 한 팀을 가지는 멤버-팀의 관계가 대표적이다.
이 경우 Team에서 Member에 대해서 OneToMany, Member에서 Team에 대해서 ManyToOne관계가 된다.
@Entity
@Getter
public class Team {
@Id
@Column(name = "team_id")
@GeneratedValue(strategy = GenerationType.IDENTITY)
int id;
// ... 생략
@OneToMany(mappedBy = "team", fetch = FetchType.EAGER)
@PrimaryKeyJoinColumn
List<Member> members;
}
@Entity
@Getter
@Table(name = "Member")
@JsonIdentityInfo(generator = ObjectIdGenerators.IntSequenceGenerator.class)
public class Member {
@Id
@GeneratedValue(strategy = GenerationType.SEQUENCE)
int uid;
// ... 생략
@OneToOne(cascade = CascadeType.ALL, fetch = FetchType.EAGER)
@PrimaryKeyJoinColumn
Address address;
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "team_id")
private Team team;
}위 처럼 OneToMany / ManyToOne 양방향 관계이기 때문에 서로 함께 설정해야 한다.
주의점
의도하지 않은 자식 엔티티의 삭제
위와 같은 경우엔, 팀이 없는 멤버가 존재할 수 있음으로 팀 삭제 시, 멤버가 삭제가 되면 안된다.
CascadeType을 ALL, 또는 REMOVE 등으로 설정 하면 의도치 않은 Member 엔티티의 삭제가 일어날 수 있으므로 영속성 전이 옵션에 대해서 알고 넘어가야 한다.
외래키 값의 관리 (중간 테이블 생성 방지)
ManyToOne 관계에서 외래키를 관리하는 주체는 Many 쪽이다. 참고
ManyToOne 쪽에서 외래 키를 설정하고, 연관 엔티티를 저장하기 위해
OneToMany 쪽에서 mapped By로 주인 엔티티를 명시해줘서 외래키를 제대로 설정해줘야 한다.
외래키 설정이 제대로 설정하지 않았다면, 의도치 않은 중간테이블이 생길 수 있다.
위 예시의 경우 Member테이블에서 @JoinColumn(name = "team_id") 으로
Team테이블의 team_id 컬럼을 참조하는 외래키를 만들 수 있다.
N+1 문제
위 예시의 경우
Team을 조회할 때 연관된 Member 엔티티들도 EAGER 로딩 설정에 의해 함께 조회된다.
이때 각각의 Member 엔티티의 team 필드를 접근할 때, LAZY 로딩 설정에 의해 Member의 수(N) 번의 Team 조회 쿼리가 추가로 실행될 수 있다.
즉 1번의 Team 조회, Member의 수(N) 가 따로 쿼리를 실행시켜 조회된다.
이 경우를 FETCH JOIN 을 통해 해결했다고 가정한다면
ex)
@Query("SELECT t FROM Team t JOIN FETCH t.members WHERE t.id = :id")
Team findByIdWithMembers(@Param("id") int id);이젠 EAGER로 설정된 Address 필드때문에 N+1 문제가 발생할 수 있다.
(멤버수 만큼의 address필드 조회(N) + FETCH JOIN으로 한번의 쿼리)
address필드를 LAZY로 바꿔도 마찬가지였다.
또한 계속 findByIdWithMembers 메소드로 조회한다면 N+1 문제가 발생한다.
JOIN FETCH 로 참조된 멤버 엔티티(t.members)의 각 필드의 로딩 전략으로
주소를 조회하는 쿼리를 실행시키기 때문이다.
로딩전략을 수정하여 위 FETCH JOIN을 사용하지 않으면서
List<Member> members 필드를 Lazy로 변경한다면 N+1 문제를 수정할 수 있어보인다. 하지만 members 필드를 사용해야만 한다면 Address 엔티티에 대한 N+1 문제가 해결되지 않는다.
이 가정들을 토대로 문제를 정리해보면
- 멤버들의 주소 필드는 사용되지 않는다.
- 하나의 팀을 조회 시 팀에 속한 멤버들의 일부 정보(이름)을 반환하기 위해 불러와야한다.
1번 문제를 해결하기 위해 가장 쉽게 생각할 수 있는 방법은 FETCH JOIN으로
Address 엔티티까지 같이 불러오는 방법이 떠오른다.
N+1 문제는 해결할 수 있지만 상황에 따라 사용되지 않는 테이블이 조인된다면 부담이 될 수 있다.
@Query("SELECT t " +
" FROM Team t " +
" JOIN FETCH t.members m " +
" LEFT JOIN FETCH m.address a " +
" WHERE t.id = :id")
Team findByIdWithMembers(@Param("id") int id);또한 Member 필드를 사용하면(2번 문제) OneToOne 관계인 address를
LAZY로 변경해도 N+1문제를 해결할 수 없다.
이 문제는 근본적으로 해결할 수가 없다.
지연 로딩이 동작하는 방식은 LAZY 전략으로 설정되어있는 엔티티를 프록시 객체로 가져온다.
하지만 프록시 객체는 Null을 담을 수 없기 때문에 EAGER 방식으로 동작한다. 참고
그럼 위 JPQL을 최적화를 해야될 것 같다.
성능적인 측면에서 Address 테이블을 조인으로 조회하기 부담스럽고, 아래 DTO로 반환해야 한다고 가정했을때,
// DTO
public class TeamResponse {
private String name;
private MemberResponse manager;
private List<String> memberNames;
}아래와 같이 수정하여 모든 멤버들의 주소 정보를 조회하는 N+1문제를 해결했다.
// service
@Transactional
public TeamResponse getTeam(int id) {
// members에 대한 로딩 전략을 LAZY로 변경
Team team = repo.findById(id)
.orElseThrow(TeamNotFoundException::new);
MemberResponse manager = new MemberResponse();
manager.setName(team.getManager().getName());
// ... 생략
TeamResponse res = new TeamResponse();
res.setName(team.getName());
res.setManager(manager);
res.setMemberNames(repo.findNamesByTeamId(id)); // 이름만 불러옴
return res;
}
// findNamesByTeamId
@Query("SELECT m.name " +
" FROM Member m " +
" WHERE m.team.id = :id ")
List<String> findNamesByTeamId(@Param("id") int id);N+1 문제가 해결되고 실행되는 쿼리는 아래와 같다.
// Team 조회
SELECT team0_.team_id as team_id1_2_0_,
team0_.manager_id as manager_3_2_0_,
team0_.name as name2_2_0_,
member1_.uid as uid1_1_1_,
member1_.email as email2_1_1_,
member1_.gender as gender3_1_1_,
member1_.hp_no as hp_no4_1_1_,
member1_.name as name5_1_1_,
member1_.team_id as team_id6_1_1_
FROM Team team0_
LEFT
OUTER
JOIN Member member1_
ON team0_.manager_id = member1_.uid
WHERE team0_.team_id = ?
// Team의 manager(OneToOne)의 address 필드 조회
SELECT address0_.member_uid as member_u4_0_0_,
address0_.city as city1_0_0_,
address0_.country as country2_0_0_,
address0_.detail as detail3_0_0_,
member1_.uid as uid1_1_1_,
member1_.email as email2_1_1_,
member1_.gender as gender3_1_1_,
member1_.hp_no as hp_no4_1_1_,
member1_.name as name5_1_1_,
member1_.team_id as team_id6_1_1_
FROM Address address0_
INNER
JOIN Member member1_
ON address0_.member_uid = member1_.uid
WHERE address0_.member_uid = ?
// 필요한 이름 목록만 조회
SELECT member0_.name as col_0_0_
FROM Member member0_
WHERE member0_.team_id = ?Team, Member (manager 필드) JPA의 영속성 컨텍스트에 저장될 수 있다.
때문에 필요한 경우 캐시에서 가져와서 사용할 수도 있어 성능상의 이점도 있다.
(또는 DTO로 직접 프로젝션해서 하는 방법도 있을 수 있겠다. 참고)
ManyToMany
멤버들 스킬과 스킬은 ManyToMany 관계라고 할 수 있다.
그럼 ManyToMany로 연결하는게 편리해 보이지만 ManyToMany는 권장되지 않는다.
ManyToMany가 권장되지 않는 이유
RDBMS의 특성 상 중간테이블이 생성될 수 밖에 없다.
중간테이블이 생성되면 JPA를 활용하면서 여러 곤란한 단점들이 드러난다.
자동으로 생성되는 중간 테이블의 제약
자동으로 생성되는 중간 테이블은 두 엔티티(테이블)간의 외래키만 가지고 있다.
만약 위 예시 테이블 구조에서 Skill 테이블에 다른 쿨타임, 레벨 등의 컬럼 등을
중간 테이블에 추가하기 어렵거나 불가능하다.
또한, 엔티티가 아닌 오직 DB에만 존재하는 중간 테이블이기 때문에,
중간 테이블에 특정 조건에 따라 로우를 추가/수정/삭제하려는 경우에는
별도의 로직을 구현해야 하기 때문에 확장성이 떨어진다고 할 수 있다.
실행되는 쿼리의 복잡성
중간 테이블을 거치기 때문에 엔티티의 조회 쿼리가 복잡해진다.
만약 비교적 많은 데이터를 조회하거나 심지어 특정 멤버의 스킬들이나,
특정 스킬을 가진 멤버를 조회할때도 비교적 조인되는 테이블이 많아지고
곧 성능의 영향을 미친다.
또한 성능 최적화 등의 이유로 작성한 관련 JPQL 모두 수정해야할 여지가 있기에
유지보수 측면에서도 단점을 보인다.
데이터의 일관성/정합성 문제
중간 테이블이 자동으로 생성되는 쿼리는 아래와 같다.
CREATE TABLE Member_Skill (
members_uid Integer NOT NULL,
Skill_code Integer NOT NULL) engine = InnoDB
ALTER TABLE Member_Skill
ADD CONSTRAINT FKe2tlol3lhtiyer8ypa4u6sw2q
FOREIGN KEY (members_uid) REFERENCES Member (uid)
ALTER TABLE Member_Skill
ADD CONSTRAINT FKdl4pohd1cgckcn89nn7ev7qaa
FOREIGN KEY (Skill_code) REFERENCES Skill (code)이 경우 여러 문제가 발생할 여지가 생긴다.
중복 데이터 문제
복합키(PK)까지 자동으로 생성하지 않기 때문에 중복된
(같은 members_uid, Skill_code 컬럼) 데이터가 들어갈 수 있다.
데이터 불일치
Member와 Skill테이블에는 자동으로 생성된 Member_Skill 테이블에 대해
어떤 제약조건도 생성되지 않는다. (중간 테이블 Member_Skill에만 각 컬럼에 외래키가 생성될 뿐)
Member와 Skill테이블에 컬럼이 수정/삭제 된다면
중간 테이블까지 수정되지 않음으로 데이터의 정합성 문제가 생길 수 있다.
이 경우 중간 테이블의 정합성을 맞춰주는 로직이 요구되며
확장성이 떨어지는 원인이 된다.
그래도 굳이 위 Member - Skill - Skill_Code 의 관계를 ManyToMany로 표현하고 싶다면 아래와 같이 설정할 수 있다. (위 테이블 설계 예시와 같다.)
public class Member {
// ... 생략
@ManyToMany
@JoinTable(name = "Skill", // 중간테이블 이름
joinColumns = @JoinColumn(name = "uid"),
inverseJoinColumns = @JoinColumn(name = "skill_code"))
private List<Skill> skills;
}
public class Skill {
@Id
private int code;
private String name;
@ManyToMany(mappedBy = "skills")
private List<Member> members;
}그래도 위 중복 데이터 문제를 방지하기 위해 uniqueConstraints 옵션을 사용할 수 있다.
@ManyToMany
@JoinTable(name = "Skill",
joinColumns = @JoinColumn(name = "uid"),
inverseJoinColumns = @JoinColumn(name = "skill_code"),
uniqueConstraints = @UniqueConstraint(columnNames = {"uid", "skill_code"}))
private List<Skill> skills;uniqueConstraints 로 uid, skill_code 컬럼에 UNIQUE제약조건을 추가하여 중복 데이터 문제를 방지한다.
중복 데이터가 생기는 로직 실행 시 ConstraintViolationException 예외가 발생한다.
비슷하게
(cascade = CascadeType.ALL)추가해서 데이터 불일치 현상을 방지할수 있어 보인다.
하지만 중간 테이블은 DB에만 존재한다.(엔티티로써 관리되지 않는다는 뜻)때문에 데이터 일관성을 보장할 수 없기에 사실은 별도의 로직이 필요하다.
다른 관계로 설계변경
Member - Skill(중간테이블) - Skill_Code 구조처럼 ManyToMany를 고집하기 보단
중간 테이블을 하나의 엔티티로써 활용할 수도 있겠다.
그렇다면 Member(One) - (Many)Skill(Many) - (One)Skill_Code 구조로 OneToMany - ManyToOne 관계로 설계하는 방법이 성능/확장성/유지보수 측면에서 더 이점이 있다고 할 수 있다.
(그래서 ManyToMany는 권장되지 않나보다...)
또는 위 테이블 구조 예시의 Member - Vacation 관계처럼
복합키를 이용한 관계로 수정하는 방법도 고려할 수 있다.
휴가와 멤버의 연관관계를 생각해보면
- 특정 휴가 기간에 여러 멤버가 갈 수 있다.
- 한 멤버도 여러번 휴가를 갈 수 있다.
이 관계는 ManyToMany로도 구현이 가능할 것 같지만, 복합키를 이용한 구조로 설계하여 확정성과 추가적인 컬럼도 선언할 수 있다.
복합키 생성
JPA에서 복합키를 생성하는 방법
1. @IdClass를 사용하는 방법
// Serializable를 구현하는 PK 클래스 구현
@Data
@NoArgsConstructor
public class VacationKey implements Serializable {
private Integer vacationId;
private Integer uid;
}// Entity 구현
@Entity
@IdClass(VacationKey.class)
public class Vacation {
@Id
@Column(name = "vacation_id")
private Integer vacationId;
@Id
private Integer uid;
// ... 생략
}2. @Embeddable를 사용하는 방법
@Data
@NoArgsConstructor
@Embeddable
public class VacationKey implements Serializable {
private int vacationId;
private int uid;
}@Entity
public class Vacation {
@EmbeddedId
private VacationKey vacationPK;
// ... 생략
}3. 두가지 방법의 차이는?
공통점
- 복합키 클래스를 Serializable 인터페이스로 구현해야 한다.
- equals, hashCode 메소드가 Override 되어야 한다.
- 기본 생성자를 구현해야 한다.
@IdClass
- 비교적 RDBMS에 더 친화적이다.
- 엔티티 클래스에
@IdClass(클래스명.class)어노테이션을 지정해줘야 한다. - 엔티티 클래스의 PK로 사용될 필드들이 동일하게 선언 되어야한다.
@EmbeddedId
- 비교적 OOP에 더 친화적이다.
(때문에 KEY 자체가 재사용될 경우 더 적절하다) - 복합키 클래스에
@Embeddable어노테이션을 지정해줘야 한다. - 엔티티 클래스는 복합키 클래스 자체를 필드로 가지며
@EmbeddedId어노테이션을 지정해줘야 한다.
복합키 클래스는 왜 Serializable를 구현해야 하는가
인터페이스인 Serializable은 객체의 상태를 바이트 스트림으로 변환(직렬화),
바이트 스트림을 객체의 상태로 복원(역직렬화)하는 메커니즘을 제공한다.직렬화 참고 : https://velog.io/@cv_/자바의-직렬화
영속성 컨텍스트는 엔티티의 ID를 사용해서 엔티티를 관리한다.
다시 말해, 엔티티의 상태를 추적하고 영속화하기 위해 엔티티의 식별자(ID)를 사용한다.
때문에 JPA가 사용하는 객체는 직렬화가 가능해야 하며 단일 식별자일 경우 기본적으로 직렬화할 수 있는 타입(Primitive Type 또는 자바에서 제공하는 타입)이 들어가기 때문에 굳이 Serializable를 구현할 필요는 없다.
하지만 복합키는 말 그대로 여러개의 식별자 필드를 가지고 있다는 뜻이고 JPA가 관리를 위해 식별하기 위해서는 복합키 클래스 자체가 직렬화 되어 메모리에 올라갈 수 있어야되기 때문이다.
참고 목록
https://stackoverflow.com/questions/9271835/why-composite-id-class-must-implement-serializable
복합키 클래스의 equals, hashCode 메소드
앞서 말했듯 JPA의 영속성 컨텍스트는 엔티티의 ID(데이터베이스의 PK)를 사용해서 엔티티를 관리한다.
당연히 ID를 사용해서 동등성을 비교하고, 데이터베이스 연산(CRUD)에 필요하기 때문일 것이다.
equals 메서드는 두 객체가 동일한 값을 가지는지 비교한다.
복합키일 경우 모든 PK를 비교해야 하는데 구현하지 않는다면 동등성 비교 결과가 다르게 나올 수 있다.
hashCode 메서드는 객체의 해시 코드를 반환한다.
이 메서드를 구현하지 않으면 복합키를 사용하는 엔티티에서 해시 기반의 자료 구조(HashMap이나 HashSet 등)에서 값이 다르게 도출된다면 문제가 발생할 가능성이 있다.
결국 구현하지 않으면 값이 같더라도 동등성 비교 결과가 다르다고 나올 수 있는 큰 문제의 발생 가능성 때문에 필수로 구현해야 한다고 설명한다.
(단일 키일 경우 Integer, Long 등의 일반 타입은 내부에 이미 내부에 구현이 되어있다.)
테스트
@Test
@DisplayName("실제로는 필드값이 모두 동일할 경우 엔티티들을 동등한 것으로 인식해야 한다.")
void CompareCompositeIdAndEntity() {
VacationKey key1 = new VacationKey(1, 1);
VacationKey key2 = new VacationKey(1, 1);
Member testmember = memberRepo.findAll().get(0);
Vacation vacation1 = new Vacation();
vacation1.setVacationId(1);
vacation1.setMember(testmember);
// 기타 필드 생략..
Vacation vacation2 = new Vacation();
vacation2.setVacationId(1);
vacation2.setMember(testmember);
// 기타 필드 생략..
assertThat(key1.equals(key2)).isTrue();
assertThat(vacation1.equals(vacation2)).isTrue();
assertEquals(key1.hashCode(), key2.hashCode());
assertEquals(vacation1.hashCode(), vacation2.hashCode());
}왜 꼭 명시적으로 Override 해야될까
기본적으로 equals, hashCode 메서드는 참조 동등성(Reference Equality)를 기반으로 동작한다.
즉, 객체의 참조 주소가 동일할 때만 동일한 객체로 간주한다.
// 참조 동등성 간단 비교 예시)
Vacation vacation1 = new Vacation();
vacation1.setVacationId(1);
vacation1.setUid(100);
Vacation vacation2 = new Vacation();
vacation2.setVacationId(1);
vacation2.setUid(100);
System.out.println(vacation1.equals(vacation2)); // 결과 : false
System.out.println(vacation1.hashCode()); // 결과 : 1728445186
System.out.println(vacation2.hashCode()); // 결과 : 237410024
// 같은 값을 내포하고 있어도 참조 주소가 다르다.하지만 실제로는 동일한 값을 가진 복합키 객체들을 동등한 것으로 인식해야 한다.
어떻게 Override 해야하는가
- 자기 자신인지 비교한다.
- proxy 객체를 고려하여 실제 클래스 타입을 비교한다.
(Lazy FetchType 또는 getReferenceById 메소드로 인한 proxy 객체) - 실제 PK 값을 비교한다.
다음은 인텔리제이의 JPA-Buddy 플러그인이 자동으로 Override 해준 코드이다.
@IdClass 방식
@Getter
@Setter
public class VacationKey implements Serializable {
private int vacationId;
private int uid;
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || Hibernate.getClass(this) != Hibernate.getClass(o)) return false;
VacationKey that = (VacationKey) o;
return Objects.equals(vacationId, that.vacationId)
&& Objects.equals(getUid(), that.getUid());
}
@Override
public int hashCode() {
return Objects.hash(vacationId, uid);
}
}@Entity
@IdClass(VacationKey.class)
public class Vacation {
@Id
@Column(name = "vacation_id")
private int vacationId;
@Id
private int uid;
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || Hibernate.getClass(this) != Hibernate.getClass(o)) return false;
Vacation vacation = (Vacation) o;
return Objects.equals(getVacationId(), vacation.getVacationId())
&& Objects.equals(getUid(), vacation.getUid());
}
@Override
public int hashCode() {
return Objects.hash(vacationId, uid);
}@Embeddable 방식
@Data
@Embeddable
public class VacationKey implements Serializable {
@Column(name = "vacation_id")
private int vacationId;
private int uid;
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || Hibernate.getClass(this) != Hibernate.getClass(o)) return false;
VacationKey that = (VacationKey) o;
return Objects.equals(vacationId, that.vacationId)
&& Objects.equals(getUid(), that.getUid());
}
@Override
public int hashCode() {
return Objects.hash(vacationId, uid);
}
}@Entity
public class Vacation {
@EmbeddedId
private @Getter @Setter VacationKey key;
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || Hibernate.getClass(this) != Hibernate.getClass(o)) return false;
Vacation vacation = (Vacation) o;
return getKey() != null && Objects.equals(getKey(), vacation.getKey());
}
@Override
public int hashCode() {
return Objects.hash(key);
}
}테이블 생성 쿼리
Hibernate:
CREATE TABLE Vacation (
uid INTEGER not null,
vacation_id INTEGER not null,
PRIMARY KEY (uid, vacation_id)
) engine=InnoDB엔티티에 직접 equals, hashcode 메소드를 Overrride 할 때
주의점과 문제점에 대해서는 아래 포스트를 참고https://jaeseo0519.tistory.com/m/153
https://velog.io/@nmrhtn7898/JPA-Entity에서-equals-hashcode-사용시-발생할-수-있는-문제점#발생할-수-있는-문제점
복합키를 사용하면 @GenerateValue를 사용할 수 없다.
@SequenceGenerator도 사용할 수 없다.
@GenerateValue는 단일키를 위한 어노테이션이다.
어떤 방법을 다 써봐도 저장 시 null값(primitive type일 경우 0)이 들어가서 데이터 무결성이 깨지거나 Column 'vacation_id' cannot be null 에러가 난다.
그러므로 vacation_id의 값을 구하는 로직을 직접 구현해야한다.
@IdClass 구현예시)
@Entity
@Getter
@Setter
@NoArgsConstructor
@IdClass(VacationKey.class)
public class Vacation {
@Id
@Column(name = "vacation_id")
private Integer vacationId;
@Id
@ManyToOne
@JoinColumn(name = "uid")
private Member member;
// ... 생략
public Vacation(Integer vacationId, Member member){
this.vacationId = vacationId;
this.member = member;
}
// ... 생략
}@Transactional
public Vacation save(int id) throws MemberNotFoundException {
Member requestedMember = memberRepo.findById(id)
.orElseThrow(MemberNotFoundException::new);
Vacation vacation = new Vacation(getVacationId(requestedMember), requestedMember);
// .. 생략
return repo.save(vacation);
}
// Member로 조회 후 최대값 + 1을 삽입해준다.
private int getVacationId(Member requestedMember) {
List<Vacation> result = repo.findByMember(requestedMember);
return result.stream()
.map(Vacation::getVacationId)
.max(Integer::compareTo)
.orElse(0) + 1;
}@EmbeddedId 방식도 마찬가지이다.
@EmbeddedId 구현예시)
@Entity
@Getter
@Setter
@ToString
@RequiredArgsConstructor
public class Vacation {
@EmbeddedId
private VacationKey key;
@ManyToOne
@JoinColumn(name = "uid", insertable = false, updatable = false)
private Member member; // VacationKey의 uid와 mapping
// ... 생략
public Vacation(EmbeddedVacationKey key) {
this.key = key;
}
public int getVacationId() {
return this.key.getVacationId();
}
// ... 생략
}public VacationResponse save(int id) throws MemberNotFoundException {
Member requestedMember = memberRepo.findById(id)
.orElseThrow(MemberNotFoundException::new);
VacationKey key = new VacationKey(getVacationId(requestedMember), id);
Vacation vacation = new Vacation(key);
vacation.setMember(requestedMember);
repo.save(vacation);
return toResponse(requestedMember, vacation);
}(RDBMS는 보통 단일키 일때만 AUTO_INCRESMENT 속성을 부여할 수 있는 것과 비슷한 이유로 추정된다.)
다른 엔티티를 참조할 때, 복합키 클래스의 직렬화 문제
복합키 중 다른 엔티티를 참조하는 PK가 있을 때,
// 복합키 클래스 예시)
public class VacationKey implements Serializable {
private Integer vacationId;
private Member member;
}이 경우 Member 객체도 직렬화 대상이 되기 때문에 성능에 악영향을 끼칠 수 있다.
(객체 그래프 탐색 시 복잡성 증가, 직렬화 데이터 자체의 크기 증가)
또한 객체 지향 관점에서 복합키 클래스가 Member 엔티티를 직접 참조함으로써 단일 책임 원칙을 위반하는 것이 아닌가 의심이 들었다.
이 글을 보면 Compilation 클래스의 ID인 private User userId; 필드와 CompilationID 복합키 클래스의 private int userId; 필드가 일치 하지 않는 것을 볼 수 있다. (그럼에도 잘 동작한다.)
응용해보면
@Getter
@Setter
public class VacationKey implements Serializable {
private int vacationId;
private int member;
// ... 생략
}@Entity
@IdClass(VacationKey.class)
public class Vacation {
@Id
@Column(name = "vacation_id")
private Integer vacationId;
@Id
@ManyToOne
@JoinColumn(name = "uid")
private Member member;
// ... 생략
}@Transactional
public VacationResponse testsave(int id) throws MemberNotFoundException {
Member requestedMember = memberRepo.findById(id)
.orElseThrow(MemberNotFoundException::new);
Vacation vacation = new Vacation();
vacation.setMember(requestedMember);
vacation.setVacationId(getVacationId(requestedMember));
repo.save(vacation);
return toResponse(requestedMember, vacation); // DTO 변환 로직
}이런 방식으로 구현하는 방법도 있다.
