Thread를 알아보기 전에 프로세스(Process)에 대해 정확히 알고 가야할 필요가 있다.
프로세스라는 말을 정말 자주 접하고 알고 있었지만 명확하게 정의는 하지 못했으니까..
1. Process
프로세스란 프로그램의 정적 데이터와 명령어들이 메모리에 적재 되는 순간 프로세스라고 불리게 된다.
즉 컴퓨터에서 연속적으로 실행되고 있는 프로그램이란 뜻으로 프로세스라고 불리며
종종 스케줄링의 대상이 되는 작업(Task)이라는 용어와 거의 같은 의미로 쓰일 때도 있다.
Process는 어떻게 처리되는가
사실 CPU는 한번에 하나의 명령어만 처리할 수 있다. (Single Processing 방식)
좀 더 정확히 말하자면 CPU의 하나의 코어(Core)가 한번에 하나의 프로세스를 처리할 수 있다.
요즘은 하나의 코어만 존재하는 CPU는 거의 없으니 프로세스가 처리되는 방식은 Multi-Processing 이다.
그렇다고 누구나 알다시피 정해진 코어 수대로 작업량을 제한하지 않는다.
당장 지금 이 글을 쓰는 지금도 내 노트북에서 음악 재생과 모각코 게더타운, 카카오톡, 브라우저...
운영체제에서 사용되는 것까지 더하면 노트북의 활성상태보기에서 575개의 프로세스가 실행되고 있다고 나온다.
CPU의 코어가 575개 이상이라서 가능한것이 아닌
운영체제가 굉장히 빠르게 CPU에서 처리할 프로세스를 바꿔주고 있기 때문이다.
운영체제는 다양한 스케줄링 알고리즘을 사용하여 CPU 시간을 프로세스 사이에서 공정하게 분배하며 여러 프로세스가 동시에 실행되는 것처럼 보이게 하는 (빠른 속도로 프로세스를 번갈아가며 처리하는) 일종의 속임수 인데,
이러한 처리 방식을 멀티태스킹(Multi-Tasking)이라고 한다.
2. Thread란?
쓰레드의 사전적 의미는 프로그램 내에서 실행되는 흐름 단위를 의미하며 프로세스보다 작은 단위이다.
위 멀티태스킹처럼 여러개의 쓰레드를 동시에 실행할 수 있으며 (마찬가지로 빠른 속도로 번갈아가며) 이러한 실행 방식을 멀티쓰레드(Multi-Thread)라고 한다.
프로세스는 독립적으로 실행되며 각각 별개의 메모리를 차지하고 있는 것과 달리 쓰레드는 프로세스 내의 메모리를 공유해 사용할 수 있으며, 프로세스 간의 전환 속도보다 쓰레드 간의 전환 속도가 빠르다.
CS에서의 쓰레드 설명은 자바에서의 쓰레드와 다르지 않다.
굳이 다른점을 뽑자면 JVM의 쓰레드 스케쥴링 메커니즘을 따른다는 것 뿐.
(이 매커니즘도 운영체제 바탕으로 동작된다.)
2-1. 멀티쓰레드(Multi-Thread)
자바는 멀티쓰레드를 지원한다. 잘 알고 쓴다면 빠른 반응성과 처리 속도, 대기 시간 감소 등의 이점을 얻을 수 있다.
CPU가 여러 개일 경우 (또는 코어)에 각각의 CPU가 스레드 하나씩을 담당하는 방법으로 이러한 시스템에서는 여러 쓰레드가 실제 시간상으로 동시에 수행될 수 있기 때문이다.
또한 기본적으로 자원을 공유할 수 있기때문에 쓰레드 사이에서 상호작용 또한 용이하다.
자원을 효율적으로 활용할 수 있다는 것은 물론 처리도 빠르게 된다.
2-2. 여러가지 안정성 문제
위에서 서술한 장점은 강조한 대로 잘 알고 쓴다는 가정하에 얻을 수 있는 이점이다.
쓰레드에 대한 이해가 없다면 약간의 문제점을 겪을 수 있다.
대부분은 '공유'와 '동시성'에서 비롯되는 문제점들이며
많은 사람들이 멀티쓰레드 환경에서 안정성을 보장하는 것이 가장 중요하다고 말한다.
동시에 실행될때의 문제점 (Race Condition)
쓰레드가 동시에 수행되며 자원을 공유하기 때문에 기본적으로 같은 자원을 동시에 접근한다면, 예를 들어 자바프로그램에서 동일한 파일, 또는 변수의 내용을 변경하려고 할 때 예상치 못한 결과를 초래할 수 있다.
class Counter {
int count = 0;
public void increase() {
count++;
}
}
class CounterThread extends Thread {
private Counter counter;
public CounterThread(Counter counter) {
this.counter = counter;
}
public void run() {
for (int i = 0; i < 1000; i++) counter.increase();
}
}
public class test {
public static void main(String[] args) throws InterruptedException {
Counter counter = new Counter();
Thread t1 = new CounterThread(counter);
Thread t2 = new CounterThread(counter);
t1.start();
t2.start();
t1.join();
t2.join();
System.out.println("Count : " + counter.count); // 증가된 count 변수 출력
}
}
// 결과
// try1 : [Count : 1845]
// try2 : [Count : 2000]
// try3 : [Count : 1995]
// try4 : [Count : 1559]
...count변수를 1씩 증가시키는 간단한 기능을 만들고 쓰레드 2개를 동시에 실행시켜 1000번을 반복해서 증가시키는 간단한 기능을 만들었을때 논리적으로 2000의 값이 출력되어야 한다고 생각했지만
실제로는 2000이라는 값을 보장하지 않는다.
이런 상황을 원인은 해당 count변수에 접근제어가 제대로 이루어지지 않았기 때문이며
위와 같이 동시에 같은 자원에 접근하면서, 실행 순서나 시간에 따라 결과값이 달라지거나 예상치 못한 결과를 가져오는 현상을 Race Condition (경쟁상태 또는 경합상태) 이라고 한다.
Race Condition의 예방 방법
Mutex 방식
Mutex Lock 이라고도 불리며 Mutual Exclusion(상호 배제)를 줄여서 일컫는 말이며 가장 많이 사용되는 접근제어방법 중 하나이다.
배제라는 단어에서 유추할 수 있듯, 공유하는 자원에 대해서 하나의 쓰레드만 접근을 허용하는 매커니즘이다.
두개 이상의 쓰레드가 접근 할 수 없는 구역을 임계구역(Critical Section) 이라고 하며
간단하게 이 임계구역은 하나의 쓰레드가 진입(lock) -> 처리 -> 이탈(unlock) 할 때 까지의 영역을 일컫는다.
(synchronized는 lock과 unlock을 자동으로 처리한다.)
자바의 synchronized 키워드를 사용하는 방법과 ReentrantLock 클래스를 사용하는 방법으로 이 Mutex를 구현할 수 있다.
synchronized 예시)
class Counter {
int count = 0;
public synchronized void increase() {
count++;
}
}위 예시에서 count변수를 증가시키는 메소드에 synchronized를 선언했다.
이 경우에 결과값 2000이라는 값을 보장할 수 있으며 사용하기 가장 간단하다.
ReentrantLock 클래스를 활용한다면 아래 처럼 바꿀 수 있다.
ReentrantLock 클래스 예시)
class Counter {
private Lock lock = new ReentrantLock();
int count = 0;
public void increase() {
lock.lock();
try {
count++;
} finally {
lock.unlock();
}
}
}위 두 예시 모두 Race Condition을 방지할 수 있는 Mutex 방식의 코드이다.
ReentrantLock 클래스를 활용하는 방법이 synchronized 키워드를 활용하는 방법보다
코드블록이 더 길어진다는 단점이 있지만 그럼에도 불구하고
ReentrantLock 클래스 또한 높은 유연성 때문에 자주 활용되며 프로젝트, 또는 프로그램의 사이즈가 커지거나 복잡해진다면 synchronized 키워드의 단점 또한 드러날 수 있다.
synchronized 의 단점
- 높은 경합률 (High Contention)
synchronized키워드를 사용하여 락을 걸면,
해당 임계구역에 접근하려는 모든 쓰레드가 락을 획득하려고 경합하게 되며
경합하는 쓰레드가 많을 수록 높은 경합률(High Contention)을 가진다고 표현한다.
대기하는 쓰레드가 많아지면 성능 저하를 일으키는 원인이 되며 Deadlock에 빠질 위험 또한 증가한다.Deadlock 이란?
두개 이상의 쓰레드가 서로의 작업이 완료될때 까지 대기상태에 머물러 있으며 아무것도 처리하지 못하는 상태를 말한다. - 어려운 디버깅
synchronized키워드는 자동으로 락을 걸고 해제하기 때문에, 코드를 작성할 때 lock(), unlock() 메소드를 따로 입력하지 않아도 되는 편리함이 단점이 될 수도 있다.
이 경우 락을 건 메소드나 블록이 어디서부터 어디까지인지 쉽게 파악하기 어려워 지는 상황을 만들 수 있으며
파악하더라도 코드 수정이 곤란해질 수도 있다.
ReentrantLock 클래스의 사용이유
자바5부터 지원하는 Lock 인터페이스를 구현/확장하여 다양한 기능을 지원하기 때문에 유연성과 확장성이 높고 synchronized 키워드만 사용하는것 보다 기능을 구체화 할 수 있다.
ReentrantLock 클래스의 기능을 이용해서 위 예시를 수정해보면
class Counter {
private Lock lock = new ReentrantLock();
int count = 0;
public void increase() {
if (lock.tryLock()) {
try {
count++; // 락을 얻었을 때
} finally {
lock.unlock();
}
} else {
System.out.println("Fail!"); // 락을 얻지 못했을 때
}
}
}
... 생략
System.out.println("Count : " + counter.count); // 증가된 count 변수 출력출력 예시)
...
Fail!
Fail!
Count : 1909ReentrantLock 클래스의 tryLock() 메서드를 활용하여 임계구역에 접근하지 못할 때의 코드를 추가할 수 있고 대기상태에 빠지는 경우가 없기 때문에 DeadLock 또한 방지할 수 있다.
tryLock() 메소드는 락을 얻을 수 있다면 즉시 락을 얻으며 true를 반환하기 때문에 lock() 메소드를 생략해야한다.
정리하자면, synchronized 키워드는 메소드나 블록 단위에서만 사용할 수 있고
JVM 레벨에서 제공되는 동기화 방식이기 때문에 사용하기 간편하고 성능도 비교적 좋아서
단순한 상황에서는 synchronized 키워드를 사용하는 것이 좋으며,
ReentrantLock 클래스가 tryLock등의 더 많은 기능을 지원하기 때문에
더 복잡한 상황이나 세밀한 처리가 필요할 때 사용하는 것이 좋다.
Semaphore 방식
Mutex 방법이 단 하나의 동기화 대상 접근을 허용하지만 Semaphore는 여러개의 대상에 대해 접근을 허용할 수 있다.
예시부터 살펴보자면
public class test {
private static int count = 0;
private static Semaphore semaphore = new Semaphore(3); // 3개의 쓰레드 허용
public static void main(String[] args) {
for (int i = 0; i < 10; i++) {
Thread thread = new Thread(new Task(i));
thread.start(); // 10개의 쓰레드 실행
}
}
static class Task implements Runnable {
private int threadNumber;
public Task(int threadNumber) {
this.threadNumber = threadNumber;
}
@Override
public void run() {
try {
semaphore.acquire();
System.out.println(threadNumber + "번 쓰레드 실행!");
count++; // 공유자원 처리 가정
System.out.println("현재까지 " + count + "번째 작업 처리중...");
Thread.sleep(1000); // 1초의 작업시간 가정
System.out.println(threadNumber + "번 쓰레드 종료..");
semaphore.release();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}출력 예시)
0번째 쓰레드 실행!
3번째 쓰레드 실행!
1번째 쓰레드 실행!
현재까지 3번째 작업 처리중...
현재까지 1번째 작업 처리중...
현재까지 2번째 작업 처리중...
5번째 쓰레드 실행!
...
현재까지 10번째 작업 처리중...
9번째 쓰레드 종료..
7번째 쓰레드 종료..
4번째 쓰레드 종료..
3개의 쓰레드가 동시에 처리되며 먼저 끝나는 순서대로 다음 쓰레드가 동작하는걸 볼 수 있다.
만약 3개의 쓰레드가 동작 중, 두번째 쓰레드의 동작이 끝나서 세마포어를 해제한다면, 다음 4번의 쓰레드가 3개의 허용된 쓰레드 개수(permits)에 포함되어 세마포어를 얻는 식이다.
이때 임계구역은 acquire() 메소드부터 release() 메소드 까지이다.
이 방식은 제한을 1로 설정하게 된다면 Mutex처럼 사용할 수 있으며
Mutex를 Binary Semaphore (이진 세마포어) 라고도 말해도 무리가 아니다.
세마포어 방식은 공유자원에 대한 접근을 동시에 허용할 쓰레드의 개수가 1개 이상일 때 사용할 수 있지만, permits의 값이 1이 아니라면 공유자원에 따라 Race Condition을 완전히 해소할 수 없는 경우도 있다.
그러므로 Race Condition을 방지하기 위해서는 상황에 따라 적절하게 골라 사용하는 것이 바람직하다.
동기화가 필요한 작업이 단순하고 짧을 경우 Mutex방식(ReentrantLock, 또는 synchronized)이 가독성 측면이나 유지보수 측면에서 적합할 수 있고
(위 예시코드는 간단하지만)동기화가 필요한 작업이 복잡하며 길거나 최적화가 필요하다면
Semaphore 방식이 좀더 적절할 수 있다.
(이 경우 아래에서 언급할 동시성 컬렉션이나 Thread-safe한 클래스 활용이 권장된다.)
실행순서를 알 수가 없다.
위 두개의 예시 모두 실행할 때 마다 처리 순서가 바뀔 수 있고 실제로 순서가 뒤죽박죽이다.
그 이유는 자바의 쓰레드의 생성/실행/제거 등의 순서는 개발자가 아닌
JVM의 쓰레드 스케쥴링 메커니즘에 의해 관리되고 이 매커니즘의 바탕인 운영체제에 따라
많은 스케줄링 알고리즘(Round Robin, SRTF 등)을 사용하기 때문에
멀티쓰레드환경에서는 쓰레드들의 실행순서를 보장할 수 없다.
그러므로 멀티쓰레드 환경에서는 실행순서에 의존하지 않는 프로그래밍 기법을 지향하는 것이 바람직하다.
위 Mutex 방식에서의 tryLock()의 예시도 쓰레드를 대기상태에 놓지 않고 다른 처리를 해서
Lock이 최소화되며 Lock을 최소화하는 방법도 실행순서에 의존하지 않는 방법중 하나이다.
이 외에도 멀티쓰레드환경에서 여러 작업들이 비동기식으로, 안정적으로 처리되기 위해 많은 방법이 있다.
1. Thread-safe한 클래스 활용
위 1. 동시에 실행될때의 문제점 예시에서도 Thread-safe한 객체를 활용하는 방법으로 수정할 수 있다.
예시에서의 Counter 클래스의 필드에서 int 타입의 count 변수를 AtomicInteger 로 변경하는 방법이 있다.
예시)
AtomicInteger count = new AtomicInteger(0); // 0으로 초기화
count.incrementAndGet(); // 1 증가 및 대입AtomicInteger 클래스는 멀티쓰레드환경에서 안전하게 사용할 수 있는 정수형연산을 지원하는 클래스이며
이런 클래스들을 원자성(Atomicity)을 보장하는 클래스라고 한다.
원자성이란?
사전적 의미로는 더 이상 쪼개질 수 없는 성질을 말한다.
CS에서는 연산의 단일성 혹은 단일 연산이라고도 불리며 어떠한 연산이 한번에 실행된다는 의미를 가지고 있다.
원자성 클래스는 내부적으로 CAS(compare-and-swap) 연산 으로 동작하여
위 예시와 같은 상황에서는 synchronized 키워드나 ReentrantLock 클래스를 사용하지 않아도
2000이라는 결과값이 보장된다.
원자성(Atomicity) 클래스는 자바5부터 지원하며 java.util.concurrent.atomic 패키지가 추가됨에 따라 AtomicReference, AtomicBoolean 등 다양한 클래스가 존재한다.
CAS(Compare-And-Swap 또는 Compare-And-Set) 연산이란? 참고
Lock-Free 알고리즘에서 주로 사용되는 원자적인 연산 중 하나이며 경합없이 값을 변경하기 위해 사용되는 연산이다.
현재 쓰레드에 저장된 값과 메인 메모리에 저장된 값을 비교하여 일치하는 경우 새로운 값으로 교체하고, 일치 하지 않는 다면 실패하고 재시도를 한다.
CPU캐시에서 잘못된 값을 참조하는 가시성 문제를 해결하기 위함이다.(참고로 synchronized 블락의 경우 synchronized 블락 진입전 후에 메인 메모리와 CPU 캐시 메모리의 값을 동기화 하기 때문에 문제가 없도록 처리한다.)
Lock-Free 알고리즘이란? 참고
병렬 알고리즘 중 하나이며 Non-Blocking 알고리즘이라고도 불린다.
경합상태를 방지하기 위해 Lock 방식 대신 저수준의 하드웨어에서 제공하는 위 CAS와 같은 원자적인 연산을 사용하여 경합없이 변수를 수정하는 알고리즘이다.
2. 동시성 컬렉션(Concurrent Collection)
위의 원자성(Atomicity) 클래스말고도 비슷하게 멀티쓰레드환경에서 사용하기 용이한 컬렉션도 존재한다.
ConcurrentHashMap 같은 경우가 대표적이며 흔하게 알고 있는 자바의 Map 인터페이스를 구현한다.
좀더 정확히 말하자면 ConcurrentHashMap은 ConcurrentMap 인터페이스를 구현하며 이 인터페이스가 Map 인터페이스를 구현한다.
때문에 이 ConcurrentHashMap 는 HashMap 자료형과 사용법은 거의 같지만 내부적으로 버킷(Bucket)단위의 Lock을 지원하여 안전하게 동기화를 처리할 수 있도록 해주는 자료구조이다. (참고)
자바5부터 지원하는 동시성 컬렉션은
ConcurrentLinkedQueue,BlockingQueue,ConcurrentSkipListMap등 여러 클래스가 존재한다.
3. 쓰레드 풀 (Thread Pool)
Thread Pool 이란 쓰레드(Thread)를 미리 만들어 놓고, 관리하는 기능을 제공하는 객체를 말한다.
실행순서에 의존하지 않는 코드를 작성하는데 있어서 매우 유용하며
보통 작은 단위로 나뉘어져 있는 작업을 처리할 때 큰 효율을 보인다.
이유는 쓰레드 풀이 일반적으로 작업 큐와 쓰레드 집합으로 이루어져 있는데,
작업 큐에는 처리해야 할 작업이 들어가며 쓰레드 집합에는 미리 생성된 쓰레드들을 담고 있다.
작업 큐에 작업이 들어오면, 쓰레드 집합에서 하나의 쓰레드가 해당 작업을 처리하고,
작업이 끝나면 다시 작업 큐에서 새로운 작업을 처리함으로써 쓰레드 생성 및 소멸에 따른 비용을 줄이고, 쓰레드를 효율적으로 재사용할 수 있기 때문이다.
위 내용을 그림으로 표현하면 다음과 같다.
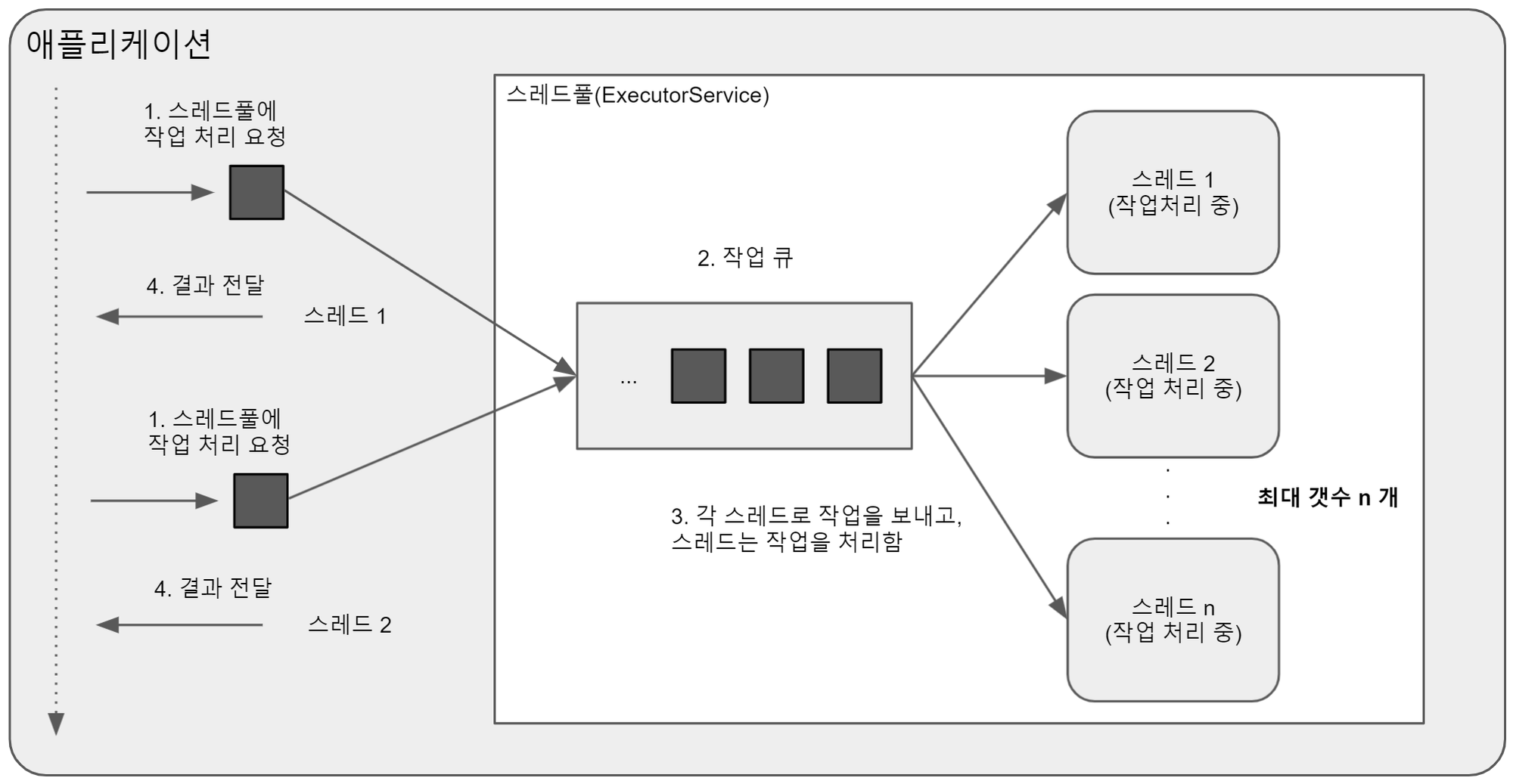
java.util.concurrent 패키지에서 제공하는 ExecutorService 인터페이스를 활용하는 방법이 가장 보편적이며 execute메소드에 Runnable구현체를 파라미터로 넘겨 작업 큐에 작업을 추가할 수 있다.
간단한 코드예시)
public class test {
public static void main(String[] args) {
// 쓰레드풀 생성
ExecutorService executor = Executors.newFixedThreadPool(5); // 최대 쓰레드 5개로 제한
for (int i = 0; i < 10; i++) {
executor.execute(new Work()); // 10개의 작업
}
executor.shutdown(); // 쓰레드풀 종료
}
static class Work implements Runnable {
@Override
public void run() {
// 작업 처리...
}
}
} 이렇게 사용할 수 있다.
주의 사항으로는 shutdown() 메소드 호출 또는 try-with-resources문을 사용해야 한다.
(try-with-resources문에서 블록이 끝날 때 쓰레드들의 라이프 사이클도 끝난다.)
그렇지 않다면 쓰레드풀이 종료되지 않아 프로그램이 계속 실행되거나, 불필요한 자원이 계속 소모되어 메모리 누수 등의 문제가 발생할 수 있다.
위 방식으로 사용하는 방식이 아래에서 설명할 자바에서 비동기 프로그래밍의 기초이다.
4. 또 다른 비동기식(Asynchronous)식 구현 방법은?
앞서 말한 Thread-safe한 클래스, 동시성 컬렉션(Concurrent Collection), 쓰레드 풀(Thread Pool)
모두 사실 포괄적으로 보면 비동기 프로그래밍 개념에 포함된다.
하지만 보통 자바에서의 비동기 프로그래밍이라고 검색해본다면
크게 콜백(Callback)방식과 CompletableFuture 객체 활용 방식으로 나눈다.
- Callback 구현
- 다른 주체 쪽에서 본(主) 주체가 전해 준 Callback 함수를 실행하는 방식
- 인터페이스,추상클래스를 활용해서 구현하는 방식, 쓰레드를 활용해서 구현하는 방식부터
람다식을 이용해서 간단하게 구현하는 방식 등이 있다.
CompletableFuture클래스 활용- 다른 주체에게 처리을 맡긴 상태에서 본(主) 주체 쪽에서도
작업 처리를 하면서 다른 주체의 결과를 확인하는 방식 - 다른 주체가 작업을 처리할 동안 또 다른 작업을 처리한다.
Future인터페이스를 구현하며 확장/개선된 기능도 지원한다.
- 다른 주체에게 처리을 맡긴 상태에서 본(主) 주체 쪽에서도
참고
Callback 구현 방법으로는 CompletionHandler를 사용하는 방식과 함수형 인터페이스(Consumer)를 활용한 방식이 설명되어 있으며
Future,CompletableFuture사용 예시도 설명되어 있다.
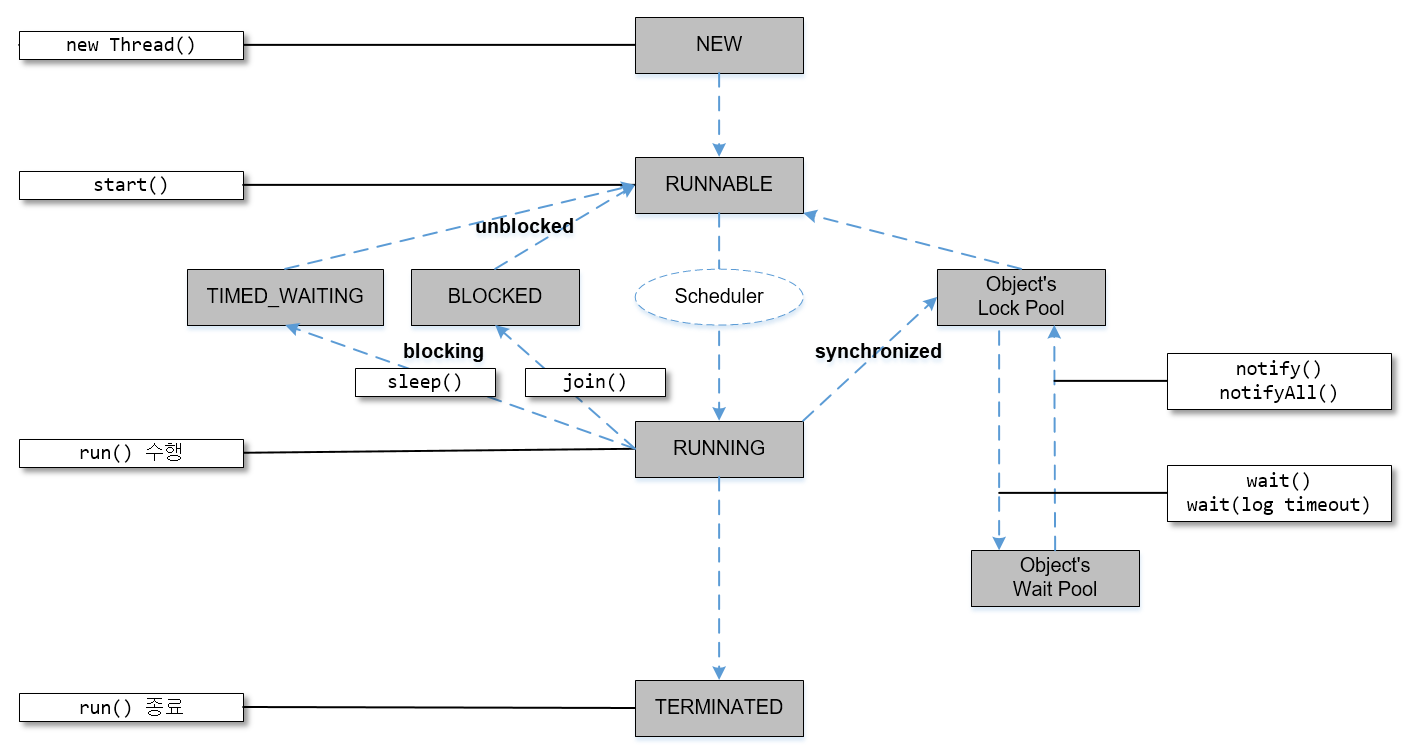
3. Thread의 생명주기(LifeCycle)
자바 멀티쓰레드 환경에서 쓰레드 생명주기 관리는 동기화 문제 만큼 중요한 이유는
안정성 문제와도 직결되며 위에서 언급한 DeadLock, Race Condition, 메모리 누수 등의 문제들을 해결하기 위해서는 쓰레드의 생명주기를 알고 관리하는 것이 중요하다.
- New
- 쓰레드 객체가 실질적으로 생성됨, 실행되지는 않는 상태
- Runnable
- start() 메소드가 호출되어 쓰레드가 언제든 실행될 준비가 된 상태
- 쓰레드 스케줄러에 의해 실행되기를 기다리고 있다
- Running
- 쓰레드 스케줄러에 의해 실행된 상태
- 쓰레드가 실질적으로 CPU를 점유하며 작업을 처리하는 상태
- Blocked
- 쓰레드가 일시적으로 중지되는 상태
- ex) 쓰레드가 synchronized 블록에서 대기 중이거나 I/O 작업을 수행 중인 경우에
이 상태가 된다
- Waiting: 이 상태의 쓰레드는 다른 쓰레드가 특정 조건을 충족할 때까지 대기
- ex) 쓰레드가 wait(), join(), park() 등의 메소드를 호출한 경우
- Terminated
- 쓰레드가 실행을 완료하거나 강제로 종료되는 단계
- 이 단계에서는 쓰레드가 더 이상 실행될 수 없음
❗️이 외에도 sleep(), yield(), interrupt() 메소드 등에 의해서 상태가 변경될 수 있음.