
연결 리스트(Linked List)
각 노드가 데이터와 포인터를 가지고 한 줄로 연결되어 있는 방식으로 데이터를 저장하는 자료구조
연결리스트의 각 노드는 다음 노드를 가리키는 포인터를 포함한다.

다음 노드를 가리키는 포인터는 다음 노드의 주소를 값으로 가지고 있다.

각 노드의 포인터 변수는 다음 노드의 데이터의 주소를 값으로 가진다. 또한 각 포인터 변수의 주소도 따로 존재한다.
(그림 속 주소는 정확하지 X, 실제 주소값은 저런 형태 아님)
단순 연결 리스트(Singly Linked List)
노드의 구성
typedef struct _Node { int data; // 저장할 데이터 struct _Node *next; // 다음 노드를 가리킬 포인터 } Node;각 노드는 저장할 데이터와 다음 노드를 가리킬 포인터로 이루어진다.
이는 노드의 구조를 선언한 것이고, 아직 노드가 생성된 것은 아니다.
연결리스트의 초기화 (init)
단순 연결 리스트는 헤드 포인터만 있으면 모든 노드를 찾을 수 있음!
가장 첫번째 노드를 가리킬 포인터 Node *head 를 전역변수로 선언하고 init() 함수를 통해 초기화한다.Node *head; void init() { head = NULL; }이렇게 헤드 포인터를 선언해주면 헤드 포인터가
NULL인 단순 연결리스트 하나가 만들어졌다고 볼 수 있다.
이제 노드를 생성해보자!
연결리스트의 삽입 (insert)
head = (Node*)malloc(sizeof(Node)); head -> data = 1; head -> next = NULL;동적 메모리 할당이므로 malloc()을 사용해주면 된다. 그 이후에는 head라는 Node의 데이터를 지정해주고 그 뒤에 연결할 노드는 아직 존재하지 않으므로 next는 NULL로 설정해준다.
현재 상태는 아래와 같다.
이번에는 노드를 연결하는 작업을 진행해보자!
new_node라는 Node를 생성해서 '2'라는 데이터를 할당해준다.
Node *new_node; // new_node 라는 노드 하나 생성 (구조체 포인터)
new_node = (Node*)malloc(sizeof(Node));
new_node -> data = 2;
new_node -> next = NULL;이제 기존에 만들어 놓았던 head Node와 방금 만든 new_node Node를 연결해주자.
Node들 간의 연결
head -> next = new_node;
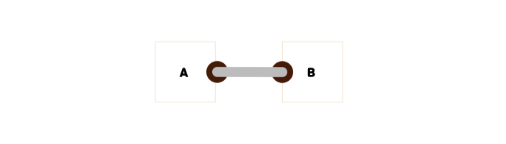
연결 리스트에서 노드를 추가하는 규칙
- 노드에 메모리 할당
- next 멤버에 다음 노드의 메모리 주소 저장
- data 멤버에 데이터 저장
- 마지막 노드라면 next 멤버에 NULL 저장
연결 리스트를 사용하는 이유
이 질문이 개발자 면접에서 은근 많이 나온다고 한다.
연결리스트와 배열의 차이점을 연결지어서 정리하면 큰 도움이 될 것 같다!
배열과 차이점
연결리스트는 논리적 순서에 따라 데이터를 입력한다. 하지만 물리적 주소는 순차적이지 않다.
인덱스를 가지고 있는 배열과는 달리 연결리스트는 인덱스 대신 현재 위치의 이전 및 다음 위치를 기억하고 있다. 때문에 한번에 데이터 접근이 가능하지 않고, 연결되어 있는 링크를 따라가야만 접근이 가능하다.
그래서 배열에 비해 속도가 떨어진다는 단점이 존재한다. 배열에 비해 구현 난이도가 높은 것도 단점이라면 단점이고..
하지만 데이터 삽입/삭제는 논리적 주소만 바꿔주면 되기 때문에 용이하다는 확연한 장점이 존재한다!
결론
데이터에 대한 접근이 빈번하게 일어나면 삽입/삭제를 할 상황이 많이 예견되지 않는다면 배열을 사용하는 것이 유리하고,
데이터에 대한 접근에 비해 삽입/삭제가 빈번하게 일어난다면 연결리스트를 사용하는 것이 좋겠다!
