implicit free list 방식으로 malloc lab을 구현하기 위해 설정한 매크로 & 할당기 초기화
#define WSIZE 4 // 워드와 헤더/푸터 사이즈
#define DSIZE 8 // 더블 워드 사이즈
#define CHUNKSIZE (1<<12) // 힙을 한번 늘릴 때 필요한 사이즈 = 이 양만큼 힙을 확장함 (4kb 분량)
#define MAX(x,y) ((x) > (y) ? (x) : (y))
/* 정렬 유지를 위해 가까운 배수로 반올림 */
#define ALIGN(size) (((size) + (DSIZE-1)) & ~0x7)
#define SIZE_T_SIZE (ALIGN(sizeof(size_t)))
/* 크기와 할당 비트를 통합해서 헤더와 푸터에 저장할 수 있는 값을 return */
#define PACK(size, alloc) ((size) | (alloc))
/* 인자 p가 참조하는 워드 읽어서 return */
/* 인자 p는 대개 (void*) 포인터. 직접적으로 역참조 불가 */
#define GET(p) (*(unsigned int*)(p))
/* p가 가리키는 워드에 val 저장 */
#define PUT(p, val) (*(unsigned int*)(p)=(val))
/* 주소 p에 있는 사이즈와 할당된 필드를 읽는다 */
#define GET_SIZE(p) (GET(p) & ~0x7)
#define GET_ALLOC(p) (GET(p) & 0x1) // 1이면 allocated 0이 free
/* 블록 포인터 bp가 주어지면, 각각 블록 헤더와 풋터를 가리키는 포인터 return */
#define HDRP(bp) ((char*)(bp) - WSIZE)
#define FTRP(bp) ((char*)(bp) + GET_SIZE(HDRP(bp)) - DSIZE)
/* 블록 포인터 bp가 주어지면, 각각 다음과 이전 블록의 블록 포인터를 return */
#define NEXT_BLKP(bp) ((char*)(bp) + GET_SIZE(((char*)(bp) - WSIZE)))
#define PREV_BLKP(bp) ((char*)(bp) - GET_SIZE(((char*)(bp) - DSIZE)))
/* 함수 선언 */
static void *find_fit(size_t asize);
static void *coalesce(void* bp);
static void placement(void *bp, size_t asize);
static void *extend_heap(size_t words);
/* 정적 전역 변수 */
static void *heap_listp; // first_fit에서 사용하기 위한 정적 전역변수
static void *next_bp; // next_fit에서 사용하기 위한 정적 전역변수
/*
* mm_init - 할당기 초기화
*/
int mm_init(void) {
/* 초기값으로 빈 힙 생성 */
if ((heap_listp = mem_sbrk(4 * WSIZE)) == (void*)-1)
return -1;
PUT(heap_listp, 0); // padding을 한 워드 크기만큼 생성
PUT(heap_listp + (1*WSIZE), PACK(DSIZE, 1)); // 프롤로그 헤더
PUT(heap_listp + (2*WSIZE), PACK(DSIZE, 1)); // 프롤로그 푸터
PUT(heap_listp + (3*WSIZE), PACK(0, 1)); // 에필로그 헤더
heap_listp += (2*WSIZE); // 프롤로그 헤더와 프롤로그 푸터 사이로 포인터 옮김
// CHUNKSIZE = 4096, 빈 힙을 CHUNKSIZE 바이트의 사용 가능한 블록으로 확장
// 공간이 없다면 return -1
if (extend_heap(CHUNKSIZE/WSIZE) == NULL)
return -1;
return 0;
}implicit free list (묵시적 가용 리스트)
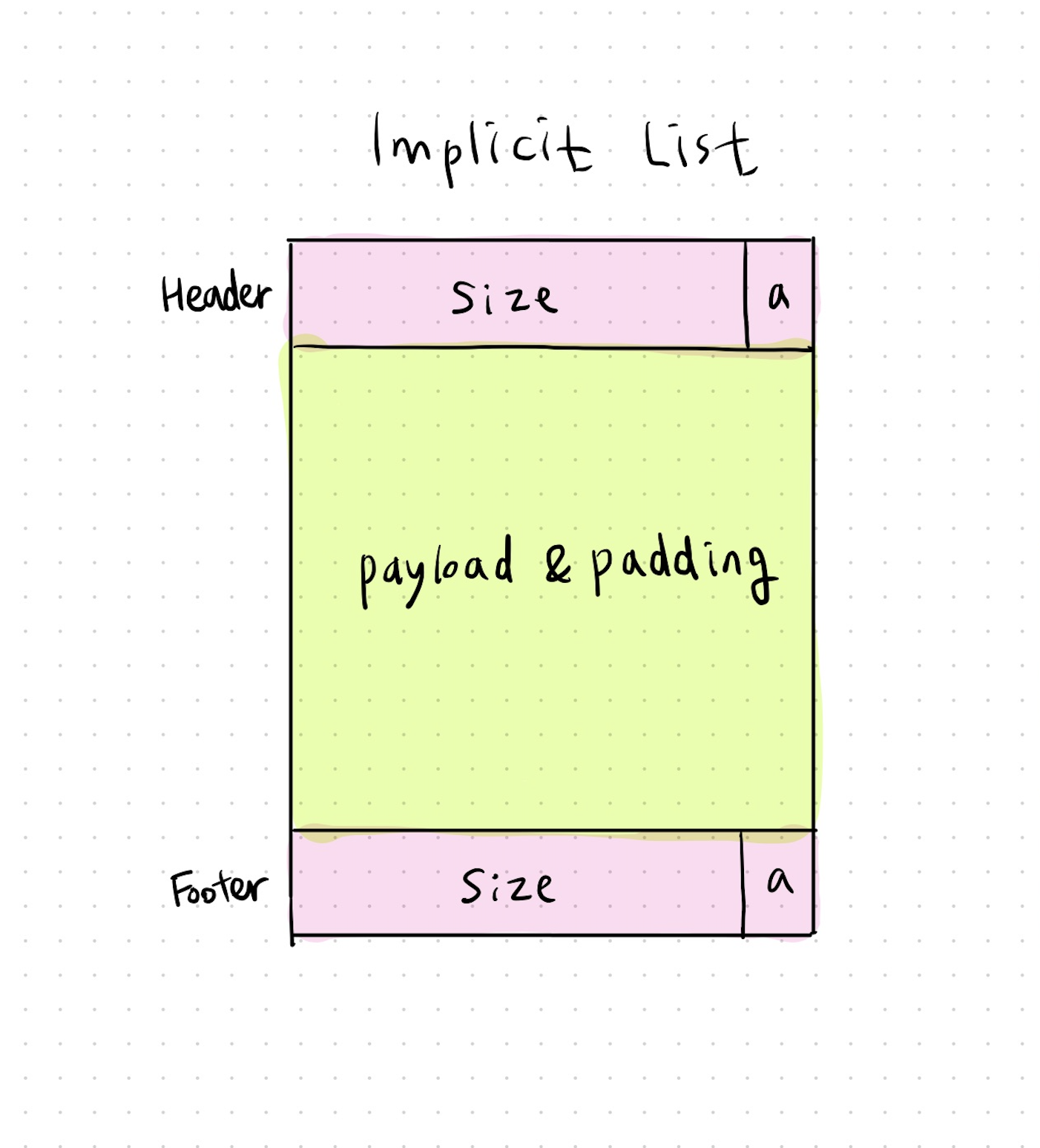
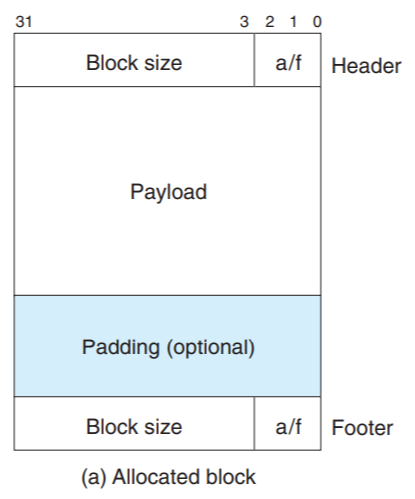
<implicit 리스트의 한 블록의 구조>
-
header: 헤더는 블록의 크기(헤더+payload+padding)와 할당 여부가 포함된다. (allocated:1, free:0)
한 블록, 즉 1word(4byte)이고 우리는 할당기가 8byte double word 정렬을 기준으로 구현할 것이다.
더블 워드 정렬 조건으로 할당되는 블록의 크기는 항상 8의 배수이고, 블록 크기의 하위 3bit는 항상 0이다.(8의 2진수 = 1000 이므로 하위 세 비트는 항상 0)
그래서 하위 3개의 비트는 다른 정보를 담기 위해 남겨둔다. 다른 정보라 하면, 블록이 할당 되었는지 아니면 가용 상태인지를 나타내기 위해 필요하다는 의미다.
위 그림의 header부분 오른쪽에 적힌 a를 보면,a=1일 때는 할당 상태,a=0일 때는 가용 상태라는 것을 나타낸다.
즉, 우리는 header를 통해 블록의 할당 상태를 알 수 있다. -
payload: application data. payload에는 malloc을 불렀을 때 요구한 데이터가 있다. (allocated blocks only)
-
padding(optional): 데이터를 채우고 난 후 남는 공간에는 패딩이 따라올 수 있다. (크기는 가변적이다) 정렬 요구사항을 만족하고, 외부 단편화를 극복하기 위해 필요할 수 있다.
-
footer: 헤더와 동일한 데이터를 가지고 있다. coalescing 시
boundary tags를 없애주기 위해 사용된다.
푸터가 필요한 이유는 가용 블록을 효율적으로 찾기 위해서이다. 이는 할당 블록에서는 오히려 메모리 사용에 방해가 된다는 말이다. 예를 들어 4byte 데이터를 할당 받는다고 할 때, 우리는 헤더 + 푸터를 포함해서 총 12byte를 할당 받아야하므로 매우 비효율적이라는 것이다.
즉, 작은 크기의 블록을 조작하는 경우메모리 오버 헤드의 위험이 존재하고 헤더와 푸터가 할당된 블록의 절반을 차지하게 될 수도 있다.
할당을 위해 알맞은 가용 공간 찾기(Finding a Free Block)
application이 K byte의 블록을 요청한다고 했을 때, allocator는 요청한 블록을 저장하기에 충분히 큰 free list를 검색한다. allocator가 이 검색을 수행하는 방법은 배치 정책에 따라서 결정된다.
- First Fit: 가용 리스트를 처음부터 검색해서 크기가 맞는 첫 번째 가용 블록을 선택
- Next Fit: first fit과 비슷하지만 검색을 리스트의 처음에서 시작하는 대신, 이전 검색이 종료된 bp에서 검색 시작하여 크기가 맞는 첫 번째 가용 블록을 선택
- Best Fit: 모든 가용 블록을 검사하여 크기가 맞는 블록들 중에 가장 작은 블록을 선택
작성한 코드(fitst fit, next fit)
/*
* find_fit - 할당할 가용 블록 크기(asize)가 가용 리스트에 있는지 탐색
*/
static void *find_fit(size_t asize) {
/* first-fit */
void *bp;
// GET_SIZE(HDRP(bp)) > 0
for (bp=heap_listp; GET_SIZE(HDRP(bp))>0; bp = NEXT_BLKP(bp)) {
// 현재, 블록이 가용 상태이고 할당하고 싶은 사이즈(asize)가 현재 블록보다 작거나 같을 때 bp 반환
if (!GET_ALLOC(HDRP(bp)) && (asize <= GET_SIZE(HDRP(bp))))
return bp;
}
// for문 종료됐다면 알맞는 크기가 없다는 것이므로 NULL 반환
return NULL;
}
static void *find_fit(size_t asize) {
/* next-fit */
void *bp;
// next_fit 전용 bp부터 찾기 시작
for (bp=next_bp; GET_SIZE(HDRP(bp))>0; bp=NEXT_BLKP(bp)) {
// 현재, 블록이 가용 상태이고 할당하고 싶은 사이즈(asize)가 현재 블록보다 작거나 같을 때 bp 반환
if (!GET_ALLOC(HDRP(bp)) && (asize <= GET_SIZE(HDRP(bp))))
return bp;
}
// 끝까지 갔는데도 없으면 다시 처음부터 돌기 시작
for (bp=heap_listp; bp!=next_bp; bp=NEXT_BLKP(bp)) {
// 현재, 블록이 가용 상태이고 할당하고 싶은 사이즈(asize)가 현재 블록보다 작거나 같을 때 bp 반환
if (!GET_ALLOC(HDRP(bp)) && (asize <= GET_SIZE(HDRP(bp))))
return bp;
}
return NULL;
}가용 블록의 분할 및 할당한 블록 배치
할당 공간 < 가용 공간 -> 내부 단편화가 발생하며 이는 메모리 낭비를 초래한다.
이러한 메모리 낭비를 해결하기 위해 필요한 공간만 할당하고, 나머지 가용 공간은 분할해서 새로운 가용 블록을 만들면 메모리를 효율적으로 사용할 수 있다.
만일 분할할 정도의 크기는 아니라면 그냥 해당 블록을 다 할당한다.
작성한 코드
/*
* placement - 할당할 크기와 맞는 블록을 찾으면(find_fit 통과) 블록을 배치
*/
static void placement(void *bp, size_t asize) {
// 여기서 현재 사이즈 = 할당이 될 블록
size_t cur_size = GET_SIZE(HDRP(bp));
// asize만큼 넣고도 나머지가 최소블록크기(16byte) 이상이라면 분할 가능
if ((cur_size - asize) >= (2*DSIZE)) {
PUT(HDRP(bp), PACK(asize, 1)); // 헤더 위치에 asize 넣고 할당 상태로 변경
PUT(FTRP(bp), PACK(asize, 1)); // 푸터 위치에 asize 넣고 할당 상태로 변경
bp = NEXT_BLKP(bp); // bp위치를 다음 블록 위치로 갱신
// asize 할당 후 남은 공간 분할해서 가용 상태로 변경
PUT(HDRP(bp), PACK(cur_size-asize, 0)); // 나머지 블록(cur-asize)은 free라는 걸 헤더에 표시
PUT(FTRP(bp), PACK(cur_size-asize, 0)); // 푸터도 표시
}
// 분할할 정도의 크기는 아니라면 그냥 할당
else {
PUT(HDRP(bp), PACK(cur_size, 1));
PUT(FTRP(bp), PACK(cur_size, 1));
}
}추가적인 힙 메모리 획득
우리가 요청한 만큼의 가용 블록이 없다면, 추가적인 힙 메모리를 요청해야 한다.
이 때 sbrk()를 호출하여 추가 메모리를 획득할 수 있다.
작성한 코드
/*
* extend_heap - 새로운 free block과 함께 heap 확장
*/
static void *extend_heap(size_t words) {
char *bp;
size_t size;
// 64bit 운영체제는 주소 단위를 8바이트로 읽기 때문에 최소 8바이트가 필요
// 짝수 * 4 = 무조건 8의 배수이기 때문에 홀수일 때 짝수로 만들어서 *4를 함
size = (words % 2) ? (words+1) * WSIZE : words * WSIZE;
// size 크기만큼 heap을 확장시킨다. 확장할 공간이 없다면 return NULL
if ((long)(bp = mem_sbrk(size)) == -1)
return NULL;
/* 가용 블럭의 헤더, 푸터 & 에필로그 헤더 초기화 */
PUT(HDRP(bp), PACK(size, 0)); // free block 헤더
PUT(FTRP(bp), PACK(size, 0)); // free block 푸터
PUT(HDRP(NEXT_BLKP(bp)), PACK(0, 1)); // new 에필로그 헤더
/* 이전 블록이 free라면 병합 */
return coalesce(bp);
}가용 블록 병합
할당기는 prev free, next free를 어떻게 병합할까? -> 경계 태그 병합
다음 가용 블록을 연결하는 것은 쉽고 효율적이다. 현재 블록의 헤더는 다음 블록의 헤더를 가리키고 있으므로 다음 블록의 가용 여부를 판단할 수 있다.
그러나 이전 블록은 현재 블록에 도달할 때까지 전체 리스트를 검색해서 이전 블록의 위치를 찾아내야 할 것이고, 이는 많은 시간이 소모될 것이다.
이러한 문제를 위해 boundary tags, 즉 footer가 필요한 이유이다. header를 복사하여 블록의 마지막에 배치한다.
작성한 코드
/*
* coalesc - 가용 블럭 생성시 통합
*/
static void *coalesce(void* bp) {
// 직전 블록의 푸터, 직후 블록의 헤더 통해 가용 여부 확인
size_t prev_alloc = GET_ALLOC(FTRP(PREV_BLKP(bp)));
size_t next_alloc = GET_ALLOC(HDRP(NEXT_BLKP(bp)));
size_t size = GET_SIZE(HDRP(bp)); // 현재 블록의 사이즈
// CASE 1: 전후 모두 할당이면
if (prev_alloc && next_alloc) {
next_bp = bp; // next_bp에 bp위치를 저장
return bp;
}
// CASE 2: 이전은 할당, 다음은 free
else if (prev_alloc && !next_alloc) {
size += GET_SIZE(HDRP(NEXT_BLKP(bp)));
PUT(HDRP(bp), PACK(size, 0));
PUT(FTRP(bp), PACK(size, 0));
}
// CASE 3: 이전은 free, 다음은 할당
else if (!prev_alloc && next_alloc) {
size += GET_SIZE(HDRP(PREV_BLKP(bp)));
PUT(FTRP(bp), PACK(size, 0));
PUT(HDRP(PREV_BLKP(bp)), PACK(size, 0));
bp = PREV_BLKP(bp); // free 시작점 변경
}
// CASE 4: 전후 모두 free
else {
size += GET_SIZE(HDRP(PREV_BLKP(bp))) + GET_SIZE(FTRP(NEXT_BLKP(bp)));
PUT(HDRP(PREV_BLKP(bp)), PACK(size, 0));
PUT(FTRP(NEXT_BLKP(bp)), PACK(size, 0));
bp = PREV_BLKP(bp);
}
next_bp = bp; // next_bp에 bp위치를 저장
return bp;
}할당 요청
/*
* mm_malloc - 가용 리스트에서 size 바이트의 메모리 블록 할당 요청
*/
void *mm_malloc(size_t size) {
size_t asize; // 블록 사이즈 조정
size_t extendsize; // heap에 맞는 fit이 없으면 확장하기 위한 사이즈
char *bp; //
// 거짓된 요청 무시
if (size == 0)
return NULL;
// 오버헤드, alignment 요청 포함해서 블록 사이즈 조정
if (size <= DSIZE)
asize = 2 * DSIZE; // 헤더와 푸터를 포함해서 블록 사이즈를 다시 조정해야되니까 DSIZE의 2배
else
/* 할당할 크기가 8바이트보다 크면 8의 배수로 맞춰줘야 하기 때문에
header+footer의 크기인 (8바이트 + 7바이트 + 할당할 크기) / 8
을 하면 나머지는 버려지고 몫만 남는데 그 몫 * 8을 하면
할당할 크기를 담을 수 있는 최소한의 크기의 8의 배수를 구할 수 있음 */
asize = DSIZE * ((size + (DSIZE) + (DSIZE-1)) / DSIZE);
// find_fit으로 asize의 크기를 넣을 수 있는 공간이 있다면
if ((bp = find_fit(asize)) != NULL) {
placement(bp, asize);
return bp; // placement를 마친 블록의 위치를 리턴
}
// find_fit 맞는게 없는 경우 = 새 가용블록으로 힙을 확장
extendsize = MAX(asize,CHUNKSIZE); // asize와 CHUNKSIZE(우리가 원래 처음에 세팅한 사이즈) 중에 더 큰거 넣음
// 확장할 공간이 더 남아있지 않다면 NULL 반환
if ((bp = extend_heap(extendsize/WSIZE)) == NULL)
return NULL;
// 확장이 됐다면, asize만큼 공간을 할당하고 잘라줌
placement(bp,asize);
return bp;
}할당 해제
메모리를 효율적으로 사용하기 위해서 더 이상 사용하지 않는 메모리를 다시 반환해줘야 한다.
작성한 코드
/*
* mm_free - 요청한 블록 반환하고, 경계 태그 연결 사용해서 상수 시간에 인접한 가용 블럭들과 병합
*/
void mm_free(void *bp) {
size_t size = GET_SIZE(HDRP(bp));
// 헤더 & 푸터 free
PUT(HDRP(bp), PACK(size, 0));
PUT(FTRP(bp), PACK(size, 0));
coalesce(bp);
}실행 결과
first fit 방식 결과

next fit 방식 결과

출처
Randal E. Bryant David R. O’Hallaron - Computer Systems A Programmer’s Perspective-Pearson (2015)
