Web Proxy
웹 프록시는 웹 브라우저와 최종 서버 간의 중간 역할을 하는 프로그램이다.
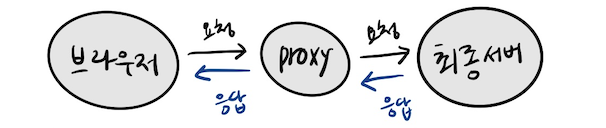
웹 페이지를 얻기 위해 브라우저가 최종 서버에 직접 연락하는 대신, 브라우저는 프록시에 연락하고, 프록시는 요청을 최종 서버로 전달한다. 최종 서버가 프록시에 응답하면 프록시는 해당 응답을 브라우저로 전송해준다.
프록시의 다양한 목적
- 방화벽 내에 있는 브라우저가 방화벽을 통해 외부 서버와만 통신할 수 있도록 하기 위해 프록시가 방화벽에 사용된다.
- 브라우저의 모든 식별 정보를 제거하여 웹 서버에 대한 브라우저의 익명성을 보장하는 익명화 도구로도 작용할 수 있다.
- 웹 객체를 캐시하여 서버의 로컬 복사본을 저장함으로써 웹 객체를 캐싱하는 데 사용될 수 있으며, 이후 요청에 대한 응답을 원격 서버와 다시 통신하는 대신 캐시에서 읽어 응답할 수 있다.
이 lab에서는 웹 객체를 캐시하는 간단한 HTTP 프록시를 작성한다.
1. 프록시를 설정하여 들어오는 연결을 수락하고, 요청을 읽고 구문 분석하여 요청을 웹 서버로 전달하고/ 서버의 응답을 읽고 해당 클라이언트에게 응답을 전달한다.
👉🏻 기본 HTTP 작업 및 소켓을 사용하여 네트워크 연결을 통신하는 프로그램을 작성하는 방법에 대한 학습이 포함됨!
2. 여러 동시 연결을 처리하기 위해 프록시를 업그레이드 한다.
👉🏻 중요한 시스템 개념인 동시성을 다루는 방법을 소개한다.
3. 최근에 액세스한 웹 콘텐츠의 간단한 주 메모리 캐시를 사용하여 *프록시에 캐싱을 추가한다.
*프록시에 캐싱을 추가한다?
프록시에 캐싱을 추가한다는 것은 프록시 서버가 웹 서버로부터 가져온 웹 객체를 저장하고, 나중에 동일한 웹 객체에 대한 요청이 들어올 때 캐시된 복사본을 사용하여 웹 객체를 다시 가져오지 않고 클라이언트에게 제공하는 기능을 의미한다.
이렇게 하면 웹 객체를 반복적으로 다운로드하는 대신 이전에 가져온 데이터를 재사용하여 웹 페이지를 더 빠르게 로드할 수 있으며, 대역폭을 절약하고 웹 서버에 대한 부하를 줄일 수 있다.
프록시 캐싱은 웹 프록시 서버의 중요한 기능 중 하나이며, 웹 성능 최적화와 대역폭 절약에 기여한다.
part 1: Sequential web proxy(순차 웹 프록시) 구현
첫 번째 단계는 HTTP/1.0GET 요청을 처리하는 기본 순차 프록시를 구현하는 것이다. (POST와 같은 다른 요청 유형은 엄격히 선택 사항!)
프록시를 시작하면, 해당 프록시는 명령줄에서 지정된 포트 번호를 기반으로 들어오는 연결을 수신 대기해야 한다.
한 번 연결이 수립되면, 프록시는 클라이언트로부터 요청을 전부 읽고 요청을 구문 분석해야 한다. 프록시는 클라이언트가 유효한 HTTP 요청을 보냈는지 여부를 판단해야 한다. 유효한 요청이라면 프록시는 적절한 웹 서버에 대한 자체 연결을 설정한 다음 클라이언트가 지정한 객체를 요청해야 한다. 마지막으로 프록시는 서버의 응답을 읽어들이고 클라이언트로 전달해야 한다.
HTTP/1.0 GET requests
웹 브라우저에서 사용자가 "http://www.cmu.edu/hub/index.html" 와 같은 url을 주소 표시줄에 입력하면, 브라우저는 아래와 유사한 라인으로 시작하는 HTTP 요청을 프록시에 보낸다
GET http://www.cmu.edu/hub/index.html HTTP/1.1이 경우, 프록시는 적어도 요청을 다음 필드로 구문 분석해야 한다.
호스트 이름인 "www.cmu.edu"와 경로 또는 쿼리 및 이를 따르는 모든 내용인 "/hub/index.html"이다.
이렇게 하면 프록시가 "www.cmu.edu"로 연결을 열고 아래와 같은 형식으로 시작하는 자체 HTTP 요청을 보내야 함을 결정할 수 있다.
GET /hub/index.html HTTP/1.0HTTP 요청의 모든 라인은 개행 문자인 '\n' 앞에 *캐리지 리턴 문자인 '\r'이 뒤따른다. 또한 모든 HTTP 요청은 빈 줄로 종료되어야 한다. "\r\n"
*carriage return?
현재 위치를 나타내는 커서 를 맨 앞으로 이동시킨다는 뜻
위의 예제에서 웹 브라우저의 요청 라인은 HTTP/1.1로 끝나는 반면, 프록시의 요청 라인은 HTTP/1.0로 끝난다. 현대의 웹 브라우저는 HTTP/1.1을 생성하지만, 프록시는 이러한 요청을 처리하고 HTTP/1.0 요청으로 전달해야 한다.
HTTP 요청은 중요한 부분이며, 심지어 HTTP/1.0 GET 요청의 하위 집합이라도 굉장히 복잡할 수 있다. 교재에서는 HTTP 트랜잭션의 일부 세부 사항을 설명하지만 완전한 HTTP/1.0 사양에 대한 내용은 RFC 1945를 참조해야 한다. 이상적으로는 HTTP 요청 구문 분석기가 RFC 1945의 관련 섹션에 따라 완전히 견고할 것이다. 다만 한 가지 주의할 점은 다중 행 요청 필드를 허용하는 사양이 있지만, 프록시는 이를 올바르게 처리할 필요는 없다. 물론 프록시가 잘못된 요청으로 인해 조기에 중단되어서는 안된다.
Request headers
이 lab에서 중요한 요청 헤더는 Host, User-Agent, Connection 및 Proxy-Connection 헤더이다.
-
언제나
Host헤더를 전송해야 한다. 이 동작은 기술적으로 HTTP/1.0 명세에 따라 승인되지 않았지만, 특히 가상 호스팅을 사용하는 특정 웹 서버로부터 합리적인 응답을 얻기 위해 필요하다.
Host헤더는 최종 서버의 호스트 이름을 나타낸다. 예를 들어 "http://www.cmu.edu/hub/index.html" 에 접근하기 위해 프록시는 다음과 같은 헤더를 보내야 한다.Host: www.cmu.edu웹 브라우저가 자체적으로 HTTP 요청에
Host헤더를 첨부할 수도 있다. 그런 경우에는 프록시가 브라우저와 동일한Host헤더를 사용해야 한다. -
아래와 같은
User-Agent헤더를 항상 전송할 수 있다.
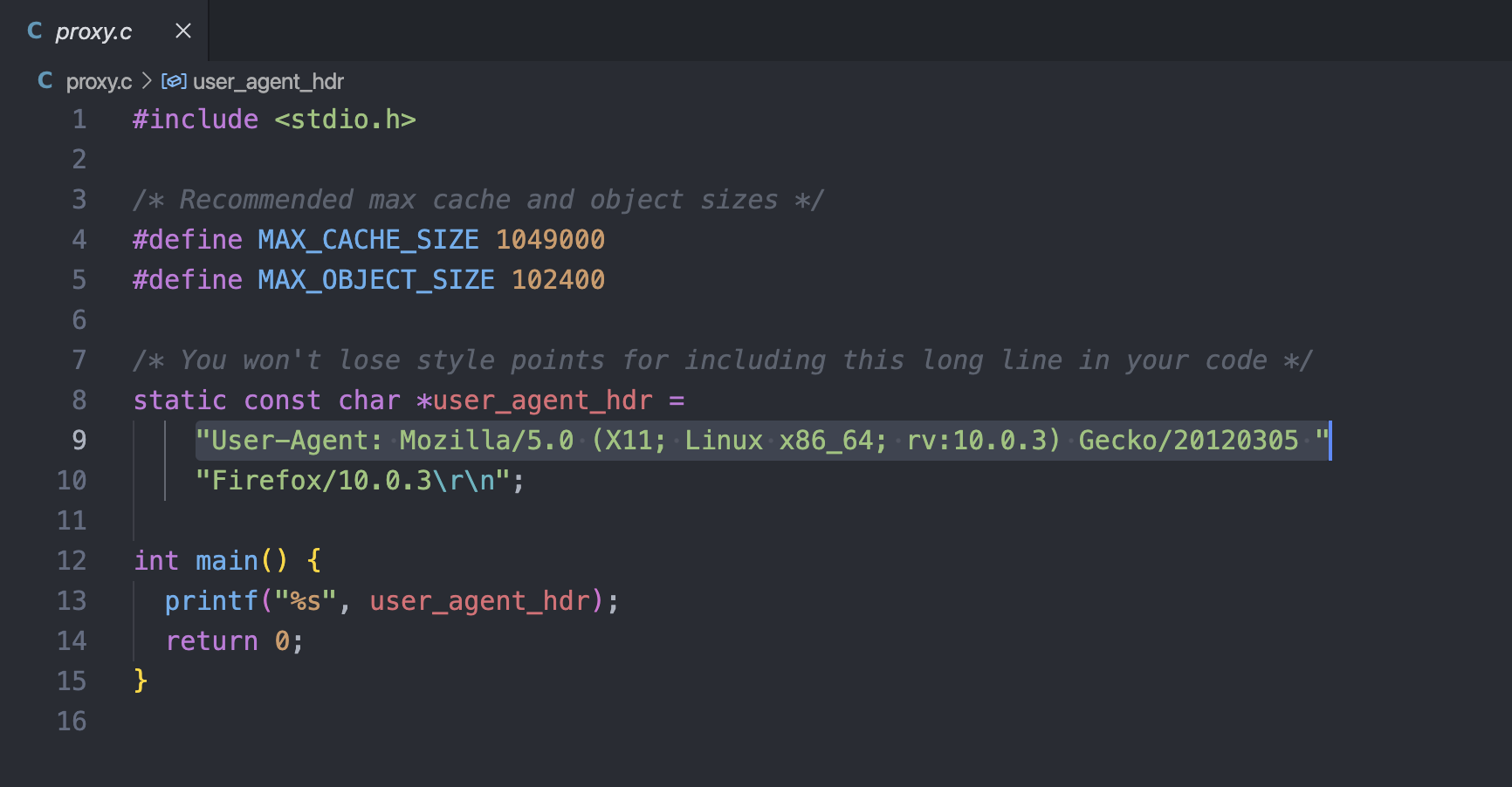
(프록시 헤더는 단일 줄로 보내야 함!)User-Agent: Mozilla/5.0 (X11; Linux x86_64; rv:10.0.3) Gecko/20120305 Firefox/10.0.3User-Agent헤더는 클라이언트를 식별하는 데 사용되며 (OS 및 브라우저와 같은 매개변수로), 웹 서버는 종종 제공하는 콘텐츠를 조작하는데 이 식별 정보를 사용한다. 이 특정 User-Agent: 문자열을 보내면 간단한 telnet 스타일 테스트 중에 얻는 콘텐츠의 질과 다양성이 향상될 수 있다. -
항상 아래와 같은
Connection헤더를 전송해야 한다.Connection: close -
항상 아래와 같은
Proxy-Connection헤더를 전송해야 한다.Proxy-Connection: closeConnection및Proxy-Connection헤더는 첫 번째 요청/응답 교환이 완료된 후에 연결을 유지할지 여부를 지정하는데 사용된다. 각 요청마다 새로운 연결을 열도록 프록시를 설정하는 것이 완벽하게 허용되며 (오히려 권장됨!), 이러한 헤더의 값으로 "close"를 지정하면 웹 서버에게 프록시가 첫 번째 요청/응답을 교환한 후 연결을 닫을 것임을 알린다.
편의상, 설명된User-Agent헤더의 값은 proxy.c 파일에 문자열 상수로 제공된다.
마지막으로, 브라우저가 HTTP 요청의 일부로 추가적인 요청 헤더를 보내면 프록시는 그것들을 변경하지 않고 그대로 전달해야 한다.
Port numbers
이 lab에서 중요한 두 가지 종류의 포트 번호가 있다.
HTTP 요청 포트 & 프록시의 수신 대기 포트
-
http 요청 포트는 http 요청의 url에서 선택적인 필드이다. 다시 말해 url은 "http://www.cmu.edu:8080/hub/index.html" 와 같은 형식일 수 있으며, 이 경우 프록시는 기본 http 포트인 80번 포트 대신 8080포트에서 호스트 "www.cmu.edu" 에 연결해야 한다. 프록시는 url에 포트 번호가 포함되어 있는지 여부에 관계없이 제대로 작동해야 한다.
-
수신 대기 포트는 프록시가 들어오는 연결을 수신하기 위해 사용해야 하는 포트이다. 프록시는 명령 줄 인수를 통해 프록시의 수신 대기 포트 번호를 지정해야 한다.
예를 들어 다음 명령으로 프록시는 포트 15213에서 연결을 수신해야 한다.
linux> ./proxy 15213기타 프로세스에서 사용되지 않는 권한 없는 수신 대기 포트(1,024보다 크고 65,536보다 작은) 중에서 선택할 수 있다. 각 프록시는 고유한 수신 대기 포트를 사용해야 하며 많은 사람들이 동시에 동일한 컴퓨터에서 작업하기 때문에 port-for-user.pl 스크립트가 제공된다. 이 스크립트를 사용하여 사용자 ID를 기반으로 포트 번호를 선택할 수 있다.
linux> ./port-for-user.pl droh
droh: 45806port-for-user.pl에서 반환하는 포트 p는 항상 짝수이다. 따라서 추가 포트 번호가 필요한 경우 (예: Tiny 서버용) 포트 p와 포트 p+1을 안전하게 사용할 수 있다.
다른 사용자 것을 간섭할 위험이 있기 때문에 무작위로 포트 번호를 선택하지 않아야 한다.
part 2: Dealing with multiple concurrent requests (동시 다발 요청 처리)
작동 중인 순차 프록시가 있으면 여러 요청을 동시에 처리하도록 프록시를 변경해야 한다.
동시 서버를 구현하는 가장 간단한 방법은 각각의 새로운 연결 요청을 처리하기 위해 새로운 스레드를 생성하는 것이다. CS:APP 12.5.5(p1044)에 설명된 사전 스레드 서버와 같은 다른 설계도 가능하다.
- 메모리 누수를 피하기 위해 스레드를 분리(detached) 모드로 실행해야 한다.
- CS:APP 교재에 설명된 open clientfd 및 open listenfd 함수는 현대적이며 프로토콜에 독립적인 getaddrinfo 함수를 기반으로 하므로 스레드는 안전하다.
part 3: Caching web objects (웹 객체 캐싱)
이 lab의 마지막 부분에서는 최근에 사용된 웹 오브젝트를 메모리에 저장하는 캐시를 프록시에 추가한다.
http는 사실 웹 서버가 제공하는 객체가 캐시되는 방법에 대한 지침과 클라이언트가 캐시를 대신 사용하는 방법을 지정할 수 있는 상당히 복잡한 모델을 정의한다. 그러나 당신의 프록시는 단순화된 접근 방식을 채택할 것이다.
당신의 프록시가 서버로부터 웹 객체를 받으면, 그 객체를 클라이언트에 전송하는 동안 메모리에 캐시해야 한다. 만약 다른 클라이언트가 동일한 서버로부터 동일한 객체를 요청하면, 프록시는 서버에 다시 연결할 필요 없이 캐시된 객체를 간단히 재전송할 수 있다.
당연히 만약 당신의 프록시가 요청되는 모든 객체를 캐시한다면 무제한의 메모리가 필요할 것이다. 또한, 일부 웹 객체가 다른 객체보다 크기 때문에 하나의 거대한 객체가 전체 캐시를 소모하여 다른 객체들이 캐시되지 못하는 경우도 있을 수 있다. 이러한 문제를 피하기 위해 프록시는 최대 캐시 크기(캐시에 저장할 수 있는 총 데이터 양, 캐시의 저장 공간 한도)와 최대 캐시 객체 크기(캐시 내에서 하나의 웹 객체가 차지할 수 있는 최대 공간)를 가지고 있어야 한다.
Maximum cache size
프록시의 전체 캐시는 다음과 같은 최대 크기를 가져야 한다.
MAX_CACHE_SIZE = 1 MiB프록시가 캐시 크기를 계산할 때, 실제 웹 객체를 저장하는 데 사용되는 byte만을 계산해야 하며, 메타데이터를 포함한 여분의 바이트는 무시해야 한다.
Maximum object size
프록시는 다음과 같이 최대 크기를 초과하지 않는 웹 객체만 캐시해야 한다.
MAX_OBJECT_SIZE = 100 KiB편의상 두 가지 크기 제한 모두 proxy.c에 매크로로 제공된다.
올바른 캐시를 구현하는 가장 쉬운 방법은 각 활성 연결에 대해 버퍼를 할당하고 서버에서 수신한 데이터를 누적하는 것이다. 버퍼의 크기가 최대 객체 크기를 초과하는 경우 버퍼를 폐기할 수 있다. 웹 서버의 응답이 최대 객체 크기를 초과하기 전에 전체를 읽는 경우 객체를 캐시할 수 있다. 이러한 방법을 사용하면 프록시가 웹 객체에 사용하는 데이터의 최대 양은 다음과 같으며, 여기서 T는 활성 연결의 최대 수이다.
MAX_CACHE_SIZE + T * MAX_OBJECT_SIZEEviction policy
프록시의 캐시는 최근에 사용되지 않은 것(LRU) 정책을 근사한 방식으로 사용해야 한다. 엄격한 LRU일 필요는 없지만 어느 정도 유사한 정책을 사용해야 한다. 객체를 읽는 것과 쓰는 것 둘 다 해당 객체를 사용한 것으로 간주된다.
Synchronization (동기화)
캐시에 대한 접근은 스레드 간에 안전해야 하며, 캐시 접근이 경쟁 상태 없이 이루어질 수 있도록 보장하는 것이 이 부분의 중요한 측면 중 하나이다.
사실 이 lab의 중요한 요구 사항 중 하나는 여러 스레드가 캐시에서 동시에 읽을 수 있어야 한다는 것이다. 캐시에 쓰기 작업은 한 번에 하나의 스레드만 수행할 수 있어야 하지만, 읽기 작업에는 이러한 제한이 없어야 한다.
따라서 캐시 접근을 하나의 큰 배타적 lock으로 보호하는 것은 허용되지 않는 해결책이다. 캐시를 분할하거나 Pthreads readers-writers locks을 사용하거나 세마포어를 사용하여 자체 readers-writers 솔루션을 구현하는 등의 옵션을 고려해보는 것이 좋다. 또한 엄격한 LRU(최근에 사용되지 않은 것을 먼저 삭제) 대체 정책을 구현할 필요는 없으며, 이로 인해 여러 리더를 지원하는 데 유연성이 제공된다.
항상 오류 및 비정상적이거나 악의적인 입력에 견고한 프로그램을 제공해야 한다. 서버는 일반적으로 장기 실행되는 프로세스이며, 웹 프록시 역시 예외가 아니다. 다양한 유형의 오류에 대한 장기 실행 프로세스의 적절한 반응에 대해 신중하게 고려해야 한다. 많은 종류의 오류에 대해서는 프록시가 즉시 종료하는 것이 적절하지 않을 것이다.
견고성은 segmentation 오류와 메모리 누수 및 파일 디스크립터 누수와 같은 오류 상황에 대한 취약성이 없어야 함을 의미한다.
Testing and debugging
단순한 자동 채점 도구 이외에도 구현을 테스트할 샘플 입력이나 테스트 프로그램은 제공되지 않을 것이다. 직접 테스트와 자신만의 테스트 툴을 만들어 코드를 디버그하고 올바른 구현 여부를 판단해야 할 것이다.
다행히도 프록시를 디버그하고 테스트할 수 있는 다양한 도구가 있다. 모든 코드 경로를 확인하고 기본 케이스, 일반적인 케이스 및 경계 케이스를 포함한 대표적인 입력 집합을 테스트한다.
Tiny web server
Handout 디렉토리에는 CS:APP Tiny 웹 서버의 소스 코드가 포함되어 있다. thttpd만큼 강력하지는 않지만, CS:APP Tiny 웹 서버는 필요에 따라 수정하기 쉬울 것이다. 또한 프록시 코드를 시작하는 합리적인 출발점이며, 드라이버 코드에서 페이지를 가져오는 데 사용되는 서버이다.
Web browsers
Mozilla Firefox의 최신 버전을 사용하여 프록시를 테스트해야 한다. "도움말 > Firefox 정보"를 방문하면 브라우저가 최신 버전으로 자동 업데이트된다.
프록시를 사용하도록 Firefox를 구성하려면 다음 단계를 따르세요:
- Firefox 브라우저를 열고 상단 메뉴에서 "도구"를 선택
- "옵션" 또는 "설정"을 클릭
- 왼쪽 메뉴에서 "고급"을 선택
- "네트워크" 아래의 "설정" 버튼을 클릭
- "프록시 설정"에서 "수동 프록시 설정"을 선택하고 필요한 프록시 정보(호스트 및 포트)를 입력
이렇게 설정한 후에는 Firefox의 프록시를 통해 대부분의 웹 사이트를 브라우징할 수 있을 것입니다.
프록시의 캐싱을 테스트할 때 주의해야 할 중요한 점은 모든 현대 웹 브라우저에는 자체 캐시가 있으며, 프록시의 캐시를 테스트하기 전에 웹 브라우저의 자체 캐시를 비활성화해야 한다는 것이다.

Handin instructions
제공된 Makefile에는 최종 제출 파일을 빌드하는 기능이 포함되어 있다. 작업 디렉토리에서 다음 명령을 실행해야 한다.
make handin이 명령을 실행하면 ../proxylab-handin.tar 라는 파일이 생성되며, 이 파일을 제출할 수 있다.
proxylab-handin.tar 솔루션 파일을 제출하려면 아래 단계를 따라야한다.
CS:APP 10장~12장에는 시스템 수준의 I/O, 네트워크 프로그래밍, HTTP 프로토콜 및 동시 프로그래밍에 관한 유용한 정보가 포함되어 있다. 또한, HTTP/1.0 프로토콜의 완전한 명세서는 RFC 1945 (http://www.ietf.org/rfc/rfc1945.txt)에서 찾을 수 있다.
Hint
-
CS:APP 10.11절에서 설명한 대로 소켓 입력 및 출력에 대해 표준 I/O함수를 사용하는 것은 문제가 될 수 있다. 대신, 우리는 csapp.c 파일에서 제공되는 Robust I/O (RIO) 패키지를 사용하는 것을 권장한다.
-
csapp.c에 제공된 오류 처리 함수는 우리의 프록시에 적합하지 않다. 왜냐하면 한 번 서버가 연결을 수락하기 시작하면 종료되지 않아야 하기 때문이다. 이 함수들을 수정하거나 직접 작성해야 한다.
-
handout 디렉토리의 파일을 마음대로 수정할 수 있다. 예를 들어 모듈성을 위해 cache 함수를 cache.c와 cache.h라는 파일로 구현할 수 있다. 물론 새로운 파일을 추가하려면 제공된 Makefile을 업데이트 해야 할 것이다.
-
CS:APP 교재 p964의 "추신"에서 설명한 대로 프록시는 SIGPIPE 신호를 무시해야 하며 EPIPE 오류가 발생한 쓰기 작업을 고요하게 처리해야 한다.
-
때로는 소켓이 조기에 닫힌 경우 read를 호출하여 바이트를 수신하면 read가 ECONNRESET 오류가 설정된 errno -1로 반환할 수 있다. 이 오류로 인해 프록시가 종료되지 않아야 한다.
-
웹의 모든 콘텐츠가 아스키문자는 아니다. 웹의 많은 콘텐츠는 이미지나 비디오와 같은 바이너리 데이터이다. 네트워크 I/O 함수를 선택하고 사용할 때 바이너리 데이터를 고려해야 한다.
-
원래 요청이 HTTP/1.1이더라도 모든 요청을 HTTP/1.0으로 전달해야 한다.
