
정미나, "유선배 SQL 개발자(SQLD) 과외노트", 시대고시기획
해당 책을 바탕으로 작성하였습니다.
그냥 개인적으로 다시 보고 공부하려고 만들었습니다.😀
성능 데이터 모델링
데이터베이스의 성능을 향상시키기 위해 설계 단계부터 성능과 관련된 사항들이 모델링에 반영될 수 있다. 성능 데이터 모델링의 방법으로는 정규화, 반정규화, 테이블 통합, 테이블 분리 등이 있다.
데이터 모델링의 순서
- 데이터 모델에 맞게 정규화를 수행.
- 데이터베이스 용량 및 트랜잭션 유형을 파악하여 성능 저하를 일으키는 부분이 없는지 검토.
- 용량과 트랜잭션 유형에 맞게 반정규화를 수행.
- 성능 향상을 위한 이력모델의 조정, PK/FK 조정, 슈퍼/서브타입 조정 등을 수행.
- 데이터 모델의 성능 검증.
정규화(Normalization)
데이터 정합성(데이터의 정확성과 일관성을 유지하고 보장)을 위해 엔티티를 작은 단위로 분리하는 과정.
제1정규형
모든 속성은 반드시 하나의 값만 가져야 한다.
- 속성값이 하나가 되도록 엔티티 분리.
- 유사한 속성이 반복되지 않도록 엔티티 분리.
제2정규형
엔티티의 일반속성은 반드시 모든 주식별자에 종속되어야 함. 주식별자가 복합식별자인 경우 일반속성이 주식별자의 일부에만 종속되면 데이터 이상 현상이 발생할 수 있음.
- 주식별자에 대한 부분종속이 없도록 엔티티를 분리.
제3정규형
주식별자가 아닌 모든 속성 간에는 서로 종속될 수 없다.
- 다른 일반속성에 종속되지 않도록 엔티티를 분리.
주의사항
지나친 정규화는 오히려 성능 저하를 일으킬 수 있다.
반정규화(De-Normalization)
데이터의 조회 성능을 향상시키기 위해 데이터의 중복을 허용하거나 데이터를 그룹핑하는 과정.
조회 성능은 향상될 수 있으나 CRUD 성능은 저하될 수 있으며 데이터 정합성 이슈가 발생할 수 있음.
반정규화는 정규화가 끝난 후 시행.
테이블 반정규화
테이블 병합
업무 프로세스상 JOIN이 필요한 경우가 많아 테이블을 통합하는 것이 성능 측면에서 유리할 경우 고려.
- 1:1 관계 테이블 병합
- 1:M 관계 테이블 병합
- 슈퍼 서브 타입 테이블 병합
테이블 분할
-
테이블 수직 분할
엔티티의 일부 속성을 별도의 엔티티로 분할(1:1 관계 성립) -
테이블 수평 분할
엔티티의 인스턴스를 특정 기준으로 별도의 엔티티로 분할(파티셔닝)
테이블 추가
-
중복 테이블 추가
데이터의 중복을 감안하더라도 성능상 반드시 필요하다고 판단되는 경우 별도의 엔티티 추가. -
통계 테이블 추가
통계치를 미리 계산하여 저장. -
이력 테이블 추가
과거 데이터를 관리. -
부분 테이블 추가
특정 속성을 자주 조회하는 경우 해당 특성만 부분 테이블로 생성.
컬럼 반정규화
-
중복 컬럼 추가
업무 프로세스상 JOIN이 필요한 경우가 많아 컬럼을 추가하는 것이 성능 측면에서 유리할 경우 고려. -
파생 컬럼 추가
프로세스 수행 시 부하가 염려되는 계산값을 미리 컬럼으로 추가하여 보관하는 방식(상품의 재고 등). -
이력 테이블 컬럼 추가
대량의 이력 테이블을 조회할 때 속도가 느려질 것을 대비하여 조회 기준이 될 것으로 판단되는 컬럼을 미리 추가해 놓는 방식(최신 데이터 여부 등).
관계 반정규화(중복관계 추가)
업무 프로세스상 JOIN이 필요한 경우가 많아 중복 관계를 추가하는 것이 성능 측면에서 유리할 경우 고려. 데이터 무결성을 깨뜨릴 위험 없이 데이터 처리 성능을 향상시킬 수 있음.
트랜잭션(Transaction)
데이터를 조작하기 위한 하나의 논리적인 작업 단위.
예 : 추천수, 쿠폰 발급 등
NULL
존재하지 않음. 값이 없음.
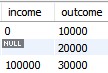
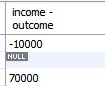
- 가로 연산 시 NULL이 포함되어 있으면 결과도 NULL.
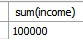
- 세로 연산 시 NULL이 포함되어 있으면 NULL값 제외.
- WHERE COL IS NULL 조건과 WHERE COL = NULL 조건은 같다?
SELECT * FROM TABLE WHERE COL IS NULL
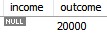
=> COL이 NULL인 인스턴스를 반환
SELECT * FROM TABLE WHERE COL = NULL
=> COL = NULL의 결과는 항상 False이므로 아무 인스턴스도 반환 X.
즉 두 조건은 다르다!
