📘SUBQUERY의 구분
위치에 따라 구분한다
- WHERE 절 : Subquery
- FROM 절 : Inlineview(페이지 그룹핑)
- SELECT 절 : ScalarQuery
실행결과 행수에 따라 구분한다
- 단일행 반환 서브쿼리(Single Row) : 메인쿼리라 일반비교연산(=,>,>,>=,<=,<>)
- 여러행 반환 서브쿼리(Multie Row) : 메인쿼리와 특수비교연산(IN, ANY, ALL)
1) 단일행 서브쿼리
- 🗒️사원의 최대 급여를 출력하시오
SELECT MAX(salary)
FROM employees;- 🗒️최대급여자의 사번, 이름, 급여를 출력하시오
SELECT employee_id, first_name, MAX(salary)
FROM employees;❌ 위의 구문은 각 사원의 최대급여를 출력하는 구문이다
아래와 같이 바꿔보자
SELECT employee_id, first_name, MAX(salary)
FROM employees
GROUP BY employee_id, first_name;✅ GROUP BY절과 함께있어야 MAX(salary)(여러행 함수)을 쓸 수 있다
서브쿼리를 이용해 위의 문제를 해결해보자
- 🗒️최대급여자의 사번, 이름, 급여를 출력하시오
1) 사원의 최대급여 계산한다 - 단일행 서브쿼리
(SELECT MAX(salary)
FROM employees;
)2) '1)'과 같은 급여를 갖는 사원 검색,출력
SELECT employee_id, first_name, salary
FROM employees
WHERE salary = (SELECT MAX(salary)
FROM employees
);- 🗒️ 성(last_name)이 'Davies'인 사원과 같은 부서에 근무하는 사원들의 사번, 성, 이름을 출력하시오
💡 employee에 있는 정보(사번, 성, 이름) - 하나의 테이블에 있는 자료들만 출력하므로 JOIN이 아닌 SUBQUERY로 처리할 수 있다
1) 성(last_name)이 'Davies'인 부서번호를 검색한다 - 단일행 서브쿼리
(
)(SELECT department_id
FROM employees
WHERE last_name = 'Davies'
)2) '1)'과같은 부서번호를 갖는 사원 검색, 출력
SELECT employee_id, last_name, first_name
FROM employees
WHERE department_id =
3) 합치기
SELECT employee_id, last_name, first_name
FROM employees
WHERE department_id = (SELECT department_id
FROM employees
WHERE last_name = 'Davies'
)
And last_name <> 'Davies';한 테이블 정보 : SUBQUERY
여러 테이블 정보 : JOIN
2) 여러행 서브쿼리
- 🗒️부서별 최대급여를 출력하시오(12)
SELECT department_id, MAX(salary)
FROM employees
GROUP BY department_id;- 🗒️부서별 최대급여자의 부서번호, 사번, 이름, 급여를 출력하시오
1) 부서별 최대 급여를 계산
(
SELECT MAX(salary)
FROM employees
GROUP BY department_id;
)2) '1)'과 같은 급여를 받는 사원 검색, 출력
SELECT employee_id, first_name, salary
FROM employees
WHERE salary = (
SELECT MAX(salary)
FROM employees
GROUP BY department_id
);⚠ 오류발생 : 메인쿼리와 일반비교연산(=,>,>,>=,<=,<>)은
단일행 서브쿼리만을 반환할 수 있다
"single-row subquery returns more than one row"
SELECT employee_id, first_name, salary
FROM employees
WHERE salary IN (
SELECT MAX(salary)
FROM employees
GROUP BY department_id
); 💡 '=' 대신 'IN'으로 대신한다.
오류 없이 출력되었지만(24) 중복이 발생했다
부서 고려를 하지 않았기 때문이다 (12) -> (24)
아래 이미지를 확인하자

왼쪽 표는 부서별 최대급여(12)를 출력한 값이다.
이 값들을 오른쪽 구문처럼 서브쿼리를 이용해서 대입하게 되면
해당 값들은 같은 사원들은 '부서별 최대급여' 사원이 아님에도
출력이 된다.
예를 들어서 아래와 같이 출력되는 부서별 급여가 있다고 할때,
| DEPARTMENT_ID | SALALY | |
|---|---|---|
| 1 | 100 | 10000 |
| 2 | 100 | 9000 |
| 3 | 100 | 12008 |
| 4 | 30 | 10000 |
| 5 | 30 | 11000 |
| 6 | 70 | 7000 |
| 7 | 70 | 8000 |
| 8 | 70 | 10000 |
30번 부서와 100번 부서의 10000의 급여를 받는 사원은
부서별 최대 급여에도 아님에도 불구하고 값이 중복해서 출력된다
즉, 하나라도 같은 값이 있으면 해당하는 값들은 모두 출력되는 것이다
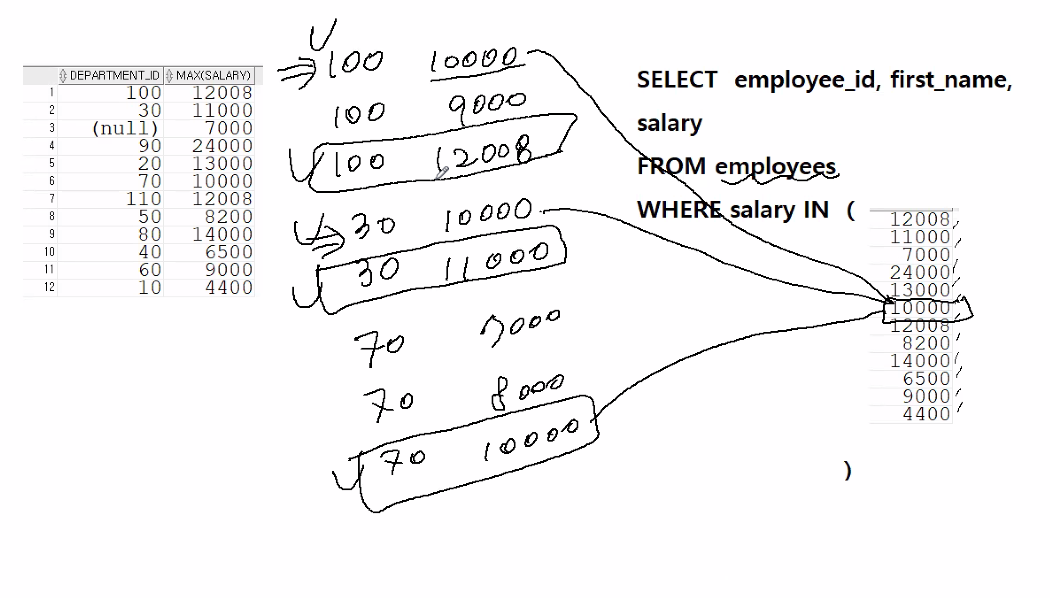
부서번호는 비교하지 않고 급여만 비교하니, 메인쿼리에서 출력이 될수 있다 (중복발생)
💡 아래와 같이 중복을 제거해보자
- 🗒️부서별 최대급여자의 (부서번호) 사번, 이름, 급여를 출력하시오 (11)
SELECT department_id, employee_id, first_name, salary
FROM employees
WHERE (department_id, salary) IN (SELECT department_id, MAX(salary)
FROM employees
GROUP BY department_id
);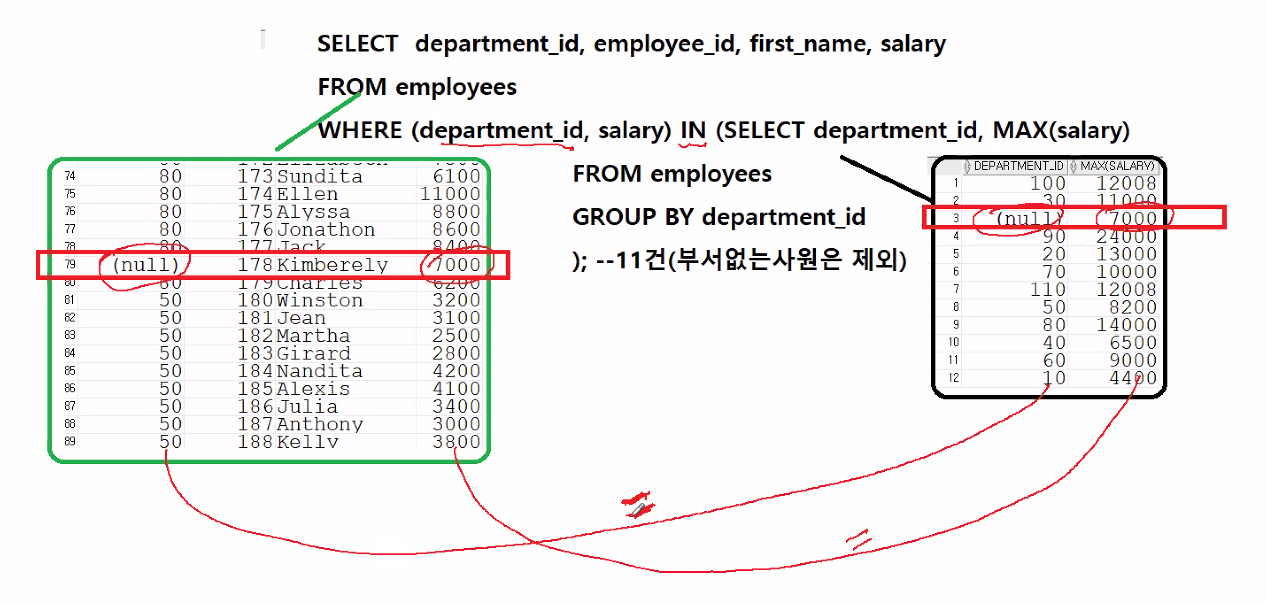
null은 null 처리 불가
- 🗒️부서없는 사람도 출력
SELECT department_id, employee_id, first_name, salary
FROM employees
WHERE (NVL(department_id,0), salary) IN (SELECT NVL(department_id,0), MAX(salary)
FROM employees
GROUP BY department_id
);- 🗒️부서별 최대 급여자를 제외한 사원의 부서번호, 사번, 이름 , 급여를
출력하시오
1) 부서별 최대급여자의 부서번호, 최대급여계산
(
SELECT MAX(salary)
FROM employees
GROUP BY department_id;
)2) 1)과 다른 부서번호, 급여를 갖는 사원을 검색, 출력한다
SELECT department_id, employee_id, first_name, salary
FROM employees
WHERE (NVL(department_id,0), salary) NOT IN (SELECT NVL(department_id,0), MAX(salary)
FROM employees
GROUP BY department_id
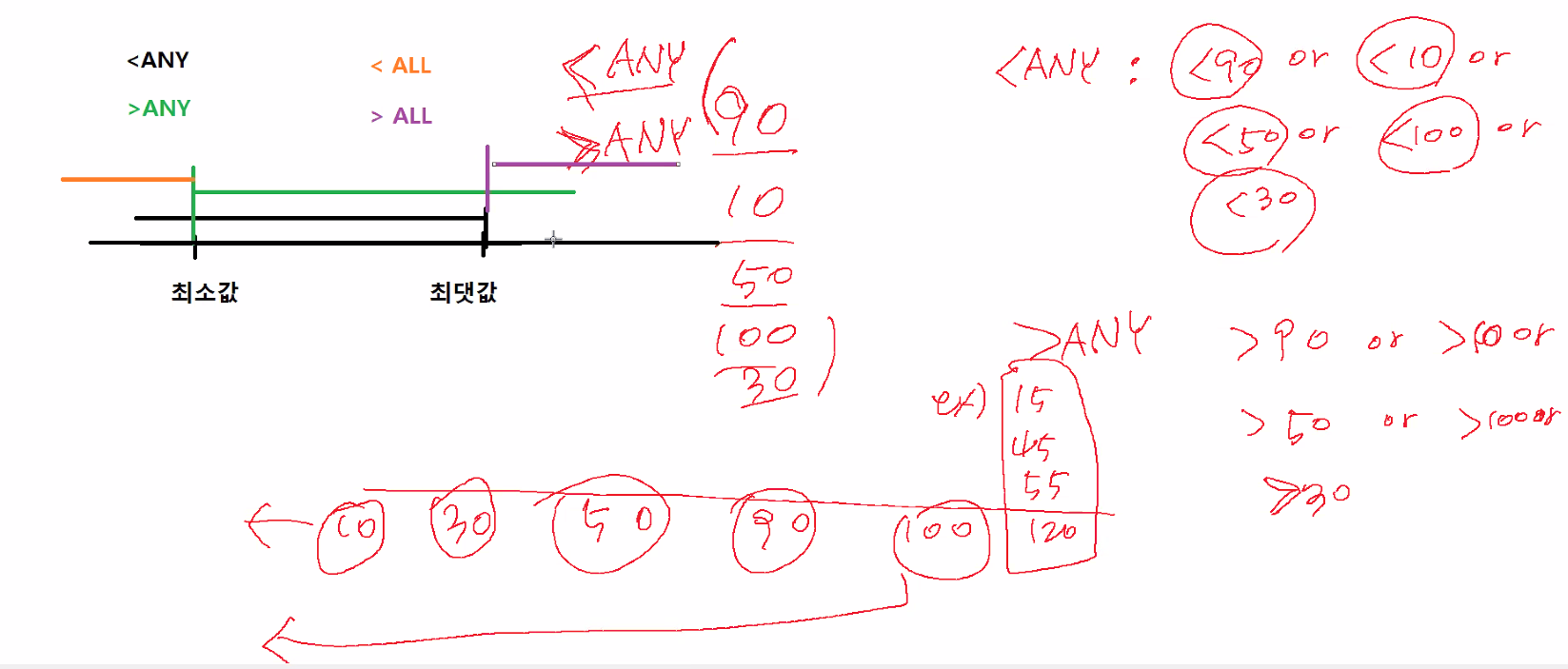
);=ANY는 IN과 같음(하나라도같다), >ANY(어떤것들보다 크다, 최솟값보다 크다), <ANY(어떤것들보다도 작다, 최댓값보다작다)
=ALL는 IN과 같음(모든것들과 같다 : 결과없음), >ALL(모든것들보다 크다, 최댓값보다 크다) <ALL(모든것들보다도 작다, 죄솟값보다 작다)
4) Inlineview
rownum 의사컬럼
행번호(rownum)는 1부터 시작한다
조건에 만족하는 행을 만나면 rownum이 1씩 증가한다
SELECT 처리순서 : FROM - WHERE - GROUP BY - HAVING - SELECT - ORDER BY
- 사원의 행번호, 사번, 급여를 출력하시오
SELECT rownum, employee_id, salary
FROM employees;- 입사일자가 '07/01/01' 이후 입사한 사원의 행번호, 사번, 급여를 출력하시오
SELECT rownum, employee_id, hire_date, salary
FROM employees
WHERE hire_date >= '07/01/01';- 입사일자가 '07/01/01' 이후 입사한 사원의 행번호, 사번, 급여를 출력하시오
단, 적은급여자부터 출력한다
SELECT rownum, employee_id, hire_date, salary
FROM employees
WHERE hire_date >= '07/01/01'
ORDER BY salary;rownum의 처리

급여기준으로 정렬된 데이터를 다시 행번호로 정렬
FROM절에 서브쿼리를사용함 - Inlineview
SELECT rownum, employee_id, hire_date, salary
FROM(
SELECT rownum, employee_id, hire_date, salary
FROM employees
WHERE hire_date >= '07/01/01'
ORDER BY salary
);예제
- 입사일자가 '07/01/01' 이후 입사한 사원의 행번호, 사번, 급여를 출력하시오
단, 적은급여자부터 5건 출력한다
처리순서를 잘 생각 : 급여가 적은 순서대로 5개의 행
SELECT rownum, employee_id, hire_date, salary
FROM(
SELECT rownum, employee_id, hire_date, salary
FROM employees
WHERE hire_date >= '07/01/01'
ORDER BY salary
)
WHERE rownum <=5; --초기값 1이 조건을 만족해서 rownum값이 1씩증가
--FROM() 안의 rownum 지워도 어차피 WHERE에서 다시 만들어짐- 입사일자가 '07/01/01' 이후 입사한 사원의 행번호, 사번, 급여를 출력하시오
단, 적은급여자부터 6행부터 10행만 출력한다
처리순서를 잘 생각 : 급여가 적은 순서대로 5개의 행
SELECT rownum, employee_id, hire_date, salary
FROM(
SELECT rownum, employee_id, hire_date, salary
FROM employees
WHERE hire_date >= '07/01/01'
ORDER BY salary
)
WHERE rownum BETWEEN 6 AND 10; -- 초기값이 1이니까 만족하는 값이 없을수밖에- 입사일자가 '07/01/01' 이후 입사한 사원의 행번호, 사번, 급여를 출력하시오
단, 적은급여자부터 6행부터 10행만 출력한다
처리순서를 잘 생각 : 급여가 적은 순서대로 5개의 행
SELECT rn, employee_id, hire_date, salary
FROM (SELECT rownum rn, employee_id, hire_date, salary
FROM(
SELECT rownum, employee_id, hire_date, salary
FROM employees
WHERE hire_date >= '07/01/01'
ORDER BY salary
)
)
WHERE rn BETWEEN 6 AND 10; -- 그냥 rownum을 쓰면 1부터 시작하는 새로운 rownum임- 입사일자가 '07/01/01' 이후 입사한 사원의 행번호, 사번, 급여를 출력하시오
단, 적은급여자부터 6행부터 10행만 출력한다
가장 안쪽 서브커리에 별칭을 주기
SELECT *
FROM (SELECT rownum rn, a.*
FROM(
SELECT rownum, employee_id, hire_date, salary
FROM employees
WHERE hire_date >= '07/01/01'
ORDER BY salary
) a
)
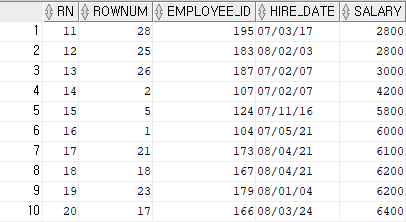
WHERE rn BETWEEN 6 AND 10;3페이지에 해당하는 첫 + 끝 행 가져와서 결과 보여줌
- 입사일자가 '07/01/01' 이후 입사한 사원의 행번호, 사번, 급여를 출력하시오
단, 적은급여자부터출력,
2페이지만 출력하고
한페이지는 최대 10개행이다
SELECT rownum, employee_id, hire_date, salary
FROM (
SELECT employee_id, hire_date, salary
FROM employees
WHERE hire_date >= '07/01/01'
ORDER BY salary
)
WHERE rownum BETWEEN 11 AND 20; --(X)SELECT *
FROM (SELECT rownum rn, a.*
FROM(
SELECT rownum, employee_id, hire_date, salary
FROM employees
WHERE hire_date >= '07/01/01'
ORDER BY salary
) a
)
WHERE rn BETWEEN 11 AND 20;