잠깐..내가 파이썬 언제 했더라?
파이썬 첫 경험은 1년 전이었다.
퇴근 후에 지하철 (편도 1시간 반 걸렸었다..TT) 에서 유튜브 틀어보고 집가서 에디터 열어보고 하면서 막 써봤던 기억이 있다. 그러다가 객체 지향에서 막혀서 진전이 없었지만 말이다.
(객체를...왜 지향해요...?)
현 시대에는 짜놓은 코드의 재사용이나 유지보수를 위해 절차지향 보다는 객체지향으로 프로그래밍한다는 것 같은데,
이 글을 쓰고 있는 나는... 그냥 뭔가를 넣고 빼고 한다는 개념으로 이해한다는게 함정인 것 같다. 클래스나 인스턴스같은 개념은 뒤로 제끼고..ㅠㅠ
그럼 지금은 왜 파이썬을 한건데?
데잇걸즈 4기 1조의 생활데이터 분석 프로젝트에서, 데잇걸즈 구성원들의 답변을 단어로 쪼개고, 그 빈도수를 추출하기 위해 사용..하긴 했다. 물론 엄청나게 삽질해서! (팀과 함께해서 즐겁기는 했다! 그런데 체력은 없었다!)
어떻게 했어?
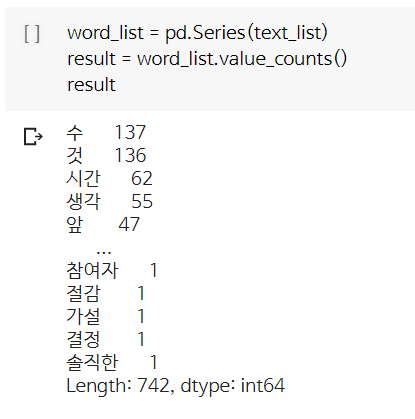
(단어 당 빈도수를 구하긴 했으나...저 상태에서 멈추면 카트라이더에서 한창 1등하고 있는데 앱 종료한거나 다름없는 상황..)
처음에는 이런식으로 진행하면 되지 않을까 생각했었다.
(1) 답변 파일(csv형태) 불러오기
(2) 단어 쪼개기
(3) 빈도수 세기
(4) 저장(이러면 얼마나 쉬울까...)
결론만 적자면 난 이러한 단계를 거쳤다!
물론 한번에 딱 나온 단계는 아니고, 하다 보면서 몇몇 단계들이 추가되었다.
(0) 적절한 라이브러리를 불러오기
(1) csv 가져오고 리스트화하기(인코딩 주의!)
(2) 글을 string 형식으로 변환
(3) 변환한 결과를 줄띄움 없이 일렬로 배치
(4) 특수문자 제거
(5) 토크나이저 사용
(6) 데이터프레임화
(7) csv로 저장(인코딩 주의!)으로 나눠질 것 같다.
이쯤되면 에러가 나인것같다..
단계를 진행하는 과정에서 겪은 에러와 유의할 점들을 정리해보려고 한다! 사실 알못이라서 코드 복붙 수준이었지만.. 에러라는 건 인생이든 기계든 항상 일어나는 거고, 거기에 대응하는 건 인간이니까 내가 인간이면 어떻게든 대응은 하겠지 싶었다.
(0) 적절한 라이브러리 불러오기
- 라이브러리: (=모듈이랑 거의 유사함) 다른 분들이 잘 만들어놓은 로직같은 건데 정말 감사하게도 내가 가져와서 쓸 수 있음.
- 대표적인 라이브러리: 데이터 분석은 pandas, 웹 크롤링은 beautifulsoup... 뭐 엄청 많다.
- 어떻게 쓰나?
pip install '라이브러리명'을 입력해서 쓰는데, 여기서 pip는 패키지 관리자라는 아이. 라이브러리를 검색해주고 실행하고 알아서 잘해주는 좋은 애다.
-
관건은? 내게 필요한 라이브러리를 찾는 것.
-
문제가 될 수 있는 것은 뭘까? 여러 라이브러리를 사용하면서 내가 필요한 것만 빼서 쓰려고 할 때.(문법적인 오류는 덤)
-
내게 필요한 라이브러리는?
나는 형태소 단위로 쪼개서 단어수를 세어야 하기 때문에 konlpy(형태소 분석 라이브러리)를 생각했었다.
이후에 OPGG 윤정환 분석가님과의 멘토링 세션에서 soynlp의 존재를 알았는데, 빈도수를 세는 기능을 soynlp에서 사용하려고 하니까 계속 문제가 됐었다.
그래서 일단은 konlpy를 사용한다는 마음가짐으로 진행했다.
(1) csv 가져오기 - 인코딩 문제
어찌 보면 제일 힘들었던 파트인 듯 하다.
- csv란 ? comma-separated values - 쉼표로 구분한 텍스트 데이터
-
문제 : csv와 한글은 극도로 상성이 안좋다. (이건 회사에서 csv로 된 데이터 뽑을 때도 자주 느꼈다...)
-
해결방법? '인코딩(문자를 읽고 쓰는 방식)'
정말 다양한 사람들이 인코딩 에러를 겪었는데, 한글 데이터를 open 할때 에러가 일어나는 일은 아주 비일비재한것 같다. 코딩할 때 open 함수를 써보면서 utf-8이든 cp949든 인코딩 방식을 써줬지만 결국 내가 얻은 해답은..
data = pd.read_csv('/content/modified_sheet.csv')
data
data.values # values를 이용하여 리스트 출력을 해보았다.
(인코딩....따로 안해줘도 된...다..??)
라는 것.
pandas 기능중에 read_csv가 있는데, 내 csv파일을 read_csv 메소드 안에 넣고 data라는 객체에 이 값을 넣어준 다음, .values 기능으로 리스트 출력을 해주면 된다!
그리고 csv 데이터는 단순히 reader로 읽어준다고 해서 되는게 아니라, 분석하고 쪼개기 위해 텍스트화 할 필요가 있다. 다른 방법도 있을 것 같은데 우선 내가 생각한 방법은
csv 데이터를 list화 -> 그 리스트를 string화 였다. 물론 여기서도 엄청난 시행착오가 있었다.
(2) 글을 string 형식으로 변환
처음엔 리스트로 빈도수 분석을 하려고 했었는데,
string으로 리스트를 처리해서 분석하는 케이스가 많다는 사실을 알았다. 그리고 그게 내 수준에서 이해하기 쉬웠다.
무한한 구글링의 결과!!!!
values = "".join(str(i) for i in data.values)
values # 스트링으로 일렬 출력
바로 리스트 형식을 스트링으로 변환해줄 수 있다는 것.
그리고 join 안에 쓰인 for 반복문은 여러 코드를 찾아보면서
csv를 line별로 쪼갠 다음 list 출력할때 쓰인다는 점을 알고 있었는데,
여기서는 아예 join()안에 들어가서 for문을 돌리게 되더라.
data.values라는, 기존에 리스트화 해놓은 값을 불러와서
string 형식으로 만들어주는 반복문에 넣어주고, 그걸 values라는 객체에 넣어서 출력해주면 된다.
..는 사실을 구글링해서 깨달았다!
