정렬 1에서는 기본적인 정렬 알고리즘의 개념과 동작 과정을 정리하였으며
정렬 2에서는 파이썬 정렬함수를 이용하여 문제풀이를 하는 방식으로 정리하였다.
정렬(Sort)
개요
데이터를 특정한 기준으로 나열하는것을 정렬이라고 하며, 오름차순 또는 내림차순으로 정렬한다. 또한 정렬문제를 풀이하다보면 다중조건을 이용해 정렬해야 하는 경우도 생긴다. 파이썬의 정렬 매소드인 sort()와 sorted()는 병합정렬(Merge Sort)을 이용하였다.
sorted()시간복잡도 : 이 보장됨.
종류
선택정렬
가장 원시적인 방법이자 직관적인 방법으로, 가장 작은 데이터를 선택해 첫번째 인덱스부터 바꾸는 과정을 반복한다. 직관적인 과정은 아래와 같다.
- 가장 작은 데이터를 선택하고, 첫번째 인덱스와 바꾼다. (탐색범위
lst[:])

- 가장 작은 데이터를 선택하고, 두번째 인덱스와 바꾼다 (탐색범위
lst[1:])

- 탐색 시작 인덱스를 늘려가며, 위 과정을 반복한다.






이때 선택정렬의 알고리즘 시간복잡도는 이며 소스코드는 아래와 같다.
for i in range(len(arr)):
min_idx = i
for j in range(i+1, len(arr)):
if arr[min_idx] > arr[j]:
min_idx = j
arr[i], arr[min_idx] = arr[min_idx], arr[i]파이썬에서
swap은a,b = b,a꼴로 사용 가능하다.
삽입 정렬
삽입 정렬은 특정한 데이터를 적절한 위치에 삽입 한다는 의미를 가지고 있다.
또한, 삽입정렬은 특정한 데이터가 적절한 위치에 들어가기 이전에, 그 앞까지의 데이터는 이미 정렬되어있다고 가정한다. 이 특성 때문에 삽입정렬 수행시 0번 인덱스가 아닌 1번 인덱스부터 탐색을 시작한다.
- 첫번째 데이터 7은 이미 정렬되어있으므로, 두번째 데이터인 5가 7의 왼쪽으로 들어갈지 오른쪽으로 들어갈지 판단한다.
7 > 5이므로, 5는 7의 왼쪽으로 이동시켜준다.


- 9가 들어갈 수 있는 위치는 총 3가지로 (5앞, 5와 7사이, 7 뒤) 정렬된 데이터 중 가장 크므로 그 자리에 둔다

- 0은 정렬된 데이터와 비교했을때 가장 작으므로 맨 앞으로 옮긴다.

- 이 과정을 반복한다.






이때 삽입정렬의 시간복잡도는 최악의 경우 의 시간복잡도를 가지나, 리스트가 거의 정렬되어있다는 가정하에 최선의 경우 의 시간복잡도를 가진다.
소스코드는 아래와 같다.
for i in range(1, len(arr)):
for j in range(1, 0, -1):
if arr[j] < arr[j-1]:
arr[j], arr[j - 1] = arr[j - 1], arr[j]
else:
break퀵 정렬
퀵 정렬은 기준을 설정한다음, 큰 수와 작은 수를 교환한 뒤 리스트를 반으로 나누는 방식으로 동작한다.
이때 기준을 피벗(pivot)이라고 한다.
이때 분할하는 방식은 아래와 같다
-
호어(Hoare)
-
피봇 값을 기준으로 큰 값을 오른쪽, 작은 값을 왼쪽으로 교차시킨다.
-
피봇 값을 중앙으로 이동시킨다 (피봇 값 왼쪽은 피봇 값보다 작고, 오른쪽은 피봇 값보다 크다. 이 과정을 파티션 또는 분할 이라고 한다.)
-
왼쪽 리스트와 오른쪽 리스트에 대해 각각 정렬을 수행하며 1, 2 과정을 반복한다 (분할이 불가능 할 때까지)
-
-
로무토(Lomuto)
- 호어 분할과 비슷하게 동작하지만 피봇이 가장 오른쪽(마지막 요소)으로 고정된다는 특징이 있다.
두 방식 모두 평균 의 시간복잡도를 갖지만, 최악의 경우 이다.
퀵 정렬은 아래와 같이 동작한다. (호어 분할)
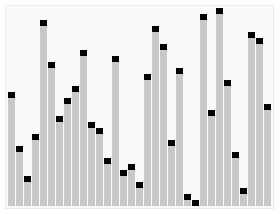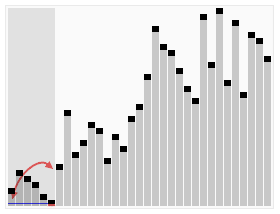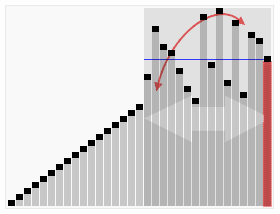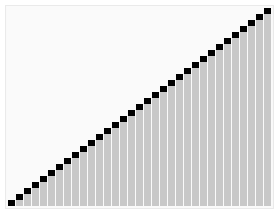
소스코드는 아래와 같다.
def quick_sort(arr):
if len(arr) <= 1:
return arr
pivot = arr[0]
tail = arr[1:]
left_side = [x for x in tail if x <= pivot]
right_side = [x for x in tail if x > pivot]
return quick_sort(left_side + [pivot] + right_side)