인프런의 자바 ORM 표준 JPA 프로그래밍 강의를 듣고 배운 내용을 정리하는 시리즈입니다.
개발을 할 때, 사용자 정보 등의 객체들은 주로 관계형 DB에 넣어서 관리한다. 이를 위해서는 직접 SQL을 작성해 개발을 했어야 하며, 다음과 같은 문제들이 발생할 수 있었다.
- '패러다임의 불일치'가 발생했다.
- 객체지향프로그래밍에서 객체에 요구하는 사항(추상화, 캡슐화, 정보은닉, 상속, 다형성 등)들을 모두 RDBMS로 커버할 수 있는 것은 아니다!
- 객체를 저장하는 보관소가 달라질 수 있다!
- RDB가 될 수도 있고, NoSQL이 될 수도 있으며, File이나 OODB가 될 수도 있다.
- 만약 이 보관소를 바꾼다고 한다면, 모든 SQL을 변경해야하는 수고가 생기게 된다.
이런 단점을 해소하기 위해서 ORM(Object-Relation Mapping)이 나왔다. (이전에 ORM 시리즈에서 ORM에 대해 기록했었다.)
오늘은 Java의 표준 ORM인 JPA가 나온 배경에 대해서 더 자세히 공부해보려고 한다.
객체와 RDB의 차이
앞서 언급했듯 객체지향 프로그래밍을 통해 만들어지는 객체와 RDBMS에서의 Relation에는 다음과 같은 차이가 존재한다.
- 상속
- 연관관계
- 데이터 타입
- 데이터 식별 방법
구체적으로 각각이 어떤 문제인지 더 자세히 알아보자.
1. 상속
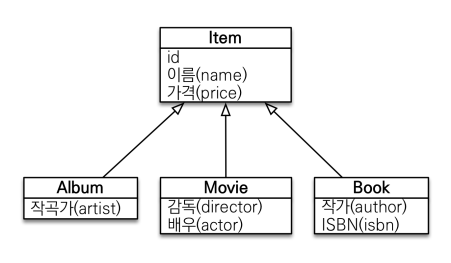
위와 같은 Item을 상속받는 객체를 만들었다고 생각해보자. Album도 Item을 상속받고, Movie도, Book도 item을 상속받는다. 이를 관계형 DB에서 표현할 수 있을까?
표현할 수는 있다. Table의 슈퍼타입과 서프타입 관계를 사용해 이런 상속 관계를 나타낼 수는 있으나, 객체지향프로그래밍에서와 같은 상속의 장점이라 생각되는 기능들이 제공되는 것은 아니다!
Album 객체를 만들어 저장하고 조회하는 과정을 생각해보자
Java에서는 간단히 아래와 같은 코드로 저장 및 조회할 수 있다.
list.add(album);
Album album = list.get(albumId);
Item item = list.get(albumId);반면 위의 Album 객체를 RDBMS에 저장한다고 했을 때, Album과 Item 객체를 따로 만든 후, 아래와 같은 SQL을 통해 각각 객체를 삽입해야 한다.
INSERT INTO ITEM ...
INSERT INTO ALBUM ...또 이를 조회하기 위해서는 더 복잡해지는데, 그 과정은 아래와 같다
- 각각 테이블에 따른 JOIN SQL 작성
- 각각의 객체 생성
- 쿼리 결과를 각 객체에 분배...
보통 위와 같은 복잡한 과정 때문에 DB에 저장하는 객체에는 상속 관계를 쓰지 않았다고 한다. (안쓰는게 생산성이 더 좋았다고..)
2. 연관관계
이번에는 객체에서 연관관계가 있는 다른 객체를 참조하는 과정을 RDBMS에서 구현할 때의 문제이다.
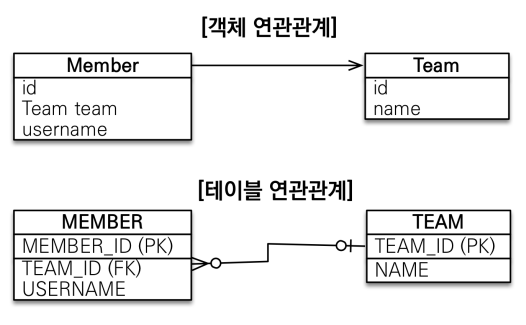
그림에서 Member의 Team 객체를 참조하기 위해 자바에서는 단순히 member.getTeam()을 통해 참조할 수 있다.
반면 RDB에서는 Foreign Key를 사용해 각 테이블을 JOIN한JOIN ON M.TEAM_ID = T.TEAM_ID 쿼리를 작성해서 참조를 구현한다.
객체를 객체지향적으로 설계한다면 다음과 같을 것이다.
class Member {
String id;
Team team;
String username;
Team getTeam(){
return team;
}
}
class Team {
Long id;
String name;
}
list.add(memeber);
Member member = list.get(memberId);
Team team = member.getTeam();반면 객체를 RDB의 테이블에 맞춰 모델링한다면 다음과 같이 모델링해야 한다.
class Member{
String id;
Team team;
String username;
}
class Team{
Long id;
String name;
}
SQL:
SELECT M.*, T.*
FROM MEMBER M
JOIN TEAM T ON M.TEAM_ID = T.TEAM_ID
public Member find(String memberId){
// SQL 실행
Member member = new Member();
// 가져온 member 정보 입력
Team team = new Team();
// 가져온 team 정보 입력
member.setTeam(team);
return member;
}이를 INSERT하기 위해서 MEMBER_ID, TEAM_ID를 사용한다면, TEAM_ID를 가져오기 위해 또 하나의 메소드를 사용해서 id를 가져와 넣어야한다.
여기까진 그럴 수 있어도, 위와 같이 객체를 조회하는 과정은 정말 복잡해진다. (SQL에서 가져온 정보를 분류하고 객체별로 나눠서 담아줘야함...)
3. 객체 그래프 탐색
객체지향 프로그래밍에서 객체는 자유롭게 그래프 탐색을 할 수 있어야한다.
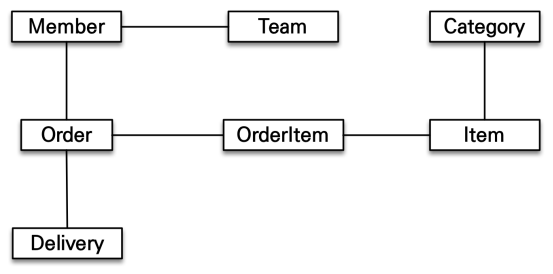
만약 Member 객체가 있다면, 해당 member가 주문한 order에 접근할 수 있어야하고, 다시 해당 정보를 이용해 orderItem에 접근할 수 있어야 한다.
이렇게 연결된 객체들을 모두 접근할 수 있을 때 '객체 그래프를 자유롭게 탐색할 수 있다'고 말한다.
반면 SQL은 처음 어떤 쿼리를 작성하냐에 따라 가져오는 객체들이 정해져 있다.
예를 들어 만약 Member의 Team table만 join해서 정보를 가져왔다면, 해당 Member의 Order 정보에는 접근할 수 없다. (애초에 가져온 정보가 없다..)
class MemberService{
...
public void process() {
Member member = memberDAO.find(memberId)l;
member.getTeam(); // 1
member.getOrder().getDelivery(); // 2
}
}예를 들어 위 코드에서 member를 가져왔다고 해서 1번에 Team 정보가 있는지 없는지 판단할 수 없고, 2번에 order와 delivery가 각각 존재하는지 아닌지 판단할 수 없다.
엔티티를 신뢰할 수 없기 때문에 쿼리를 살펴서 직접 어떤 것들을 가져오는지 살펴야 하며, 이는 객체지향 프로그래밍의 계층 분할을 어렵게 만드는 요소가 된다.
이런 문제점들이 존재했기 때문에, 객체를 자바 collection에 저장하듯 DB에 저장하고자 하는 욕구가 생겼고, 이를 위해서 Java Persistence API(이하 JPA)가 나왔다.
JPA?
JPA란 맨 처음에 설명했던 ORM의 일종으로, Java에서 표준으로 사용되는 ORM이다.
Java 애플리케이션과 JDBC API사이에서 상호작용 할 수 있도록 인터페이스를 제공하는데, 예를 들어 객체 저장과 조회의 과정은 각각 아래와 같다.
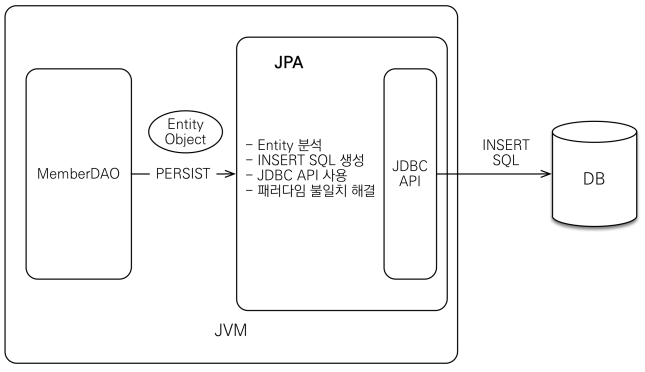
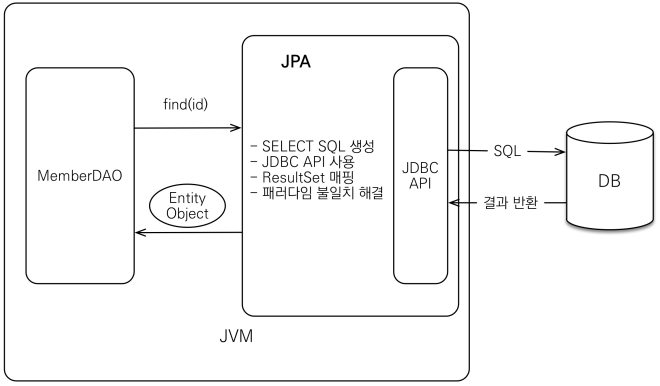
JPA 2.1 표준 명세를 구현한 구현체는 3가지: Hibernate, EclipseLink, DataNucleus가 있는데 사용자의 90%는 Hibernate를 사용한다.
위에서 언급했던 패러다임의 불일치를 해결해주는 등 JPA를 사용해야하는 이유는 당연히 많지만, 이에 대해서는 ORM 시리즈를 다루면서 다뤘으니, JPA가 가져다주는 이점들에 대해서 정리를 해보고자 한다.
1. 1차 캐시와 identity 보장
예를 들어 사용자가 똑같은 객체를 두 번 이상 조회한다고 가정해보자. 실무에서 코드가 복잡해질수록 그런 상황이 자주 발생한다고 한다.
String memberId = "100";
Member m1 = jpa.find(Member.class, memberId);
Member m2 = jpa.find(Member.class, memberId);
println(m1 == m2); // true위와 같은 상황에서 SQL은 한 번만 실행되고, m2의 객체를 조회하는 실행문에서는 캐시에 저장되어있던 객체를 가져와서 그대로 적용해주는 방식으로 사용된다.
또한 그렇게 가져온 두 객체가 완전히 같음을 보장해준다.
(마지막 print문의 출력 결과는 true!)
사실 캐시로 인한 성능 향상은 크지 않다고 한다.
2. 트랜잭션을 지원하는 쓰기 지연
트랜잭션을 커밋할 때까지 INSERT SQL을 모으고, 커밋시 JDBC BATCH SQL 기능을 사용해서 한 번에 SQL을 전송하는 방식으로 쓰기 지연을 구현한다.
이는 UPDATE나 DELETE에서도 동일하게 적용되며, 트랜잭션 커밋시 UPDATE, DELETE SQL을 실행하고 바로 커밋한다. 때문에 row lock으로 인한 시간을 최소화할 수 있다.

3. 지연 로딩(Lazy loading)
이는 ORM의 공통점이자 이로써 발생할 수 있는 문제들을 다룰 때 매우 많이 언급했었는데, 지연 로딩은 실제 객체가 사용될 때 로딩하는 방식을 말한다.
사실 모든 객체를 한 번에 가져와서 저장하는 것은 메모리적으로 낭비가 심해질 가능성이 높다.
다만, 위 코드에서 Member를 조회할 때 그것에 대한 Team 정보도 거의 항상 가져온다면, 즉시 로딩(eager loading) 모드를 해당 entity에만 켬으로써 바로 해결할 수 있다고 한다.
마무리
ORM에 대해서 많이 알고 이해했다고 생각했는데, 실제로 왜 사용하는지를 더 자세히 다루니 지금 얼마나 편한 시대에 살고 있는 것인지 체감이 확 됐다.
다만 마지막에 ORM은 객체와 RDB 위에 있는 기술이라고 언급하셨던 만큼, ORM의 사용법만큼이나 RDB에 대해서도 공부를 게을리 해서는 안되겠다는 생각이 들었다..
