네트워크 - 3. Transport Layer (3)
바로 들어가자
Principles of congestion control
congestion의 용어 정리를 먼저 해보자. congestion이란 network에서 handling할 수 없을 정도의 속도로 너무 많은 source가 보내지는 상황을 이야기한다.
congestion 때문에 발생할 수 있는 문제는 아래와 같다.
- long delay (라우터 buffer에서의 queuing delay)
- packet loss (라우터의 buffer overflow)
몇 번이고 언급했지만, flow control과 congestion control은 다르다.
- flow control: receiver가 sender에게 너무 압도 당하지 않도록 보내는 packet 수를 제한하는 것
- congestion control: network에 너무 많은 packet으로 인한 overhead(congestion)을 막기 위해 보내는 packet 수를 제한하는 것
Congestion이 발생하는 간단한 시나리오를 보자.
Scenario
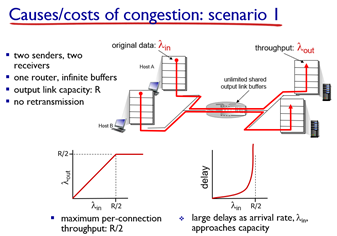
가장 먼저 무한한 버퍼를 갖는 router에 2명의 host와 2대의 서버가 있다고 하자. 그럼 2개의 flow가 있게 된다. 이 상황에서의 특징은 아래와 같다.
- buffer가 무한하기 때문에 재전송은 발생하지 않는다. (packet loss가 일어나야 재전송임)
- 아래 그래프에서 볼 수 있 듯 R/2까지만 속도가 증가하고, 더는 증가하지 않는다. (flow가 2개니까)
- 또한 라우터에 들어오는 속도가 R/2에 가까워질수록 queuing delya는 기하급수적으로 상승한다.
- 이유는 저번에도 다뤘듯, 이 속도가 average이기 때문에 실제로는 dynamic(random)해서 버퍼에 쌓이게 됨..
- congestion의 cost는 queuing delay가 된다.
이후 buffer가 유한한 상황이라고 가정해보자. buffer가 유한하면 packet loss가 발생할 수 있고, packet loss가 발생하면 retransmit도 발생한다. 즉, 실제로 보내는 양이 전체 packet 양보다 더 늘어나게 된다.
- 만약 sender가 router buffer가 사용가능할 때만 보내면 위의 상황과 같아지지만, 실제로는 buffer state를 알 수가 없다..
- 또한 loss시의 retransmit을 위해 TCP에서는 오리지날 Data를 저장할 buffer를 유지해야 한다.
- 다시 app은 그냥 tcp를 한 번 호출할 뿐이기 때문에 TCP에서 임의로 다시 application layer의 데이터를 가져올 수가 없다..!
- 재전송시 이 TCP buffer에서 데이터를 보낸다.
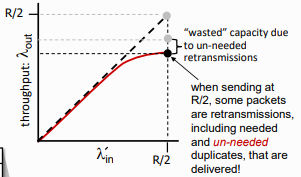
때문에 이렇게 retransmission으로 낭비된다.
또한 실제로는 Premature timeout 등으로 인한 unneeded duplicates가 존재하게 되는데, 때문에 여기서 더 손실이 발생해 최종적으로 위와 같은 그래프가 된다.
이쯤에서 congestion을 발생시키는 2가지 요인을 살펴보자
1. receiver throughput보다 더 많은 work (retransmission)
2. unneeded retransmissions: 같은 packet의 multiple copy가 link로 전달되는 상황...
마지막으로 더 많은 host가 더 많은 router을 경유해서 서버에 도달하는 시나리오이다.
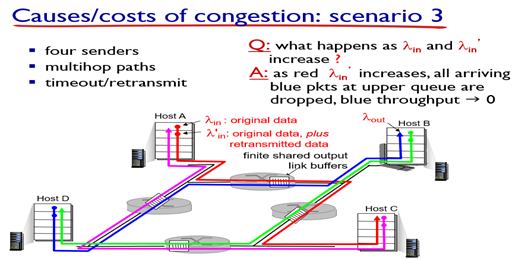
path에 2개 이상의 라우터가 있는 경우이다. 이때, 위 그림에서 빨간색 flow의 실제 in rate(람다'in)이 계속 증가한다고 가정해보자. 그렇게 되면, 같은 라우터를 공유하는 파란색 flow의 packet은 모두 버려지게 되고, blue throughput은 0에 수렴하게 된다.
- closer host가 router의 모든 data를 점유하게 되는 것.
- 점점 더 많은 packet이 버려지면, 파란색 flow의 first hop router 또한 점점 많아지는 retransmit에 의해 마비된다...
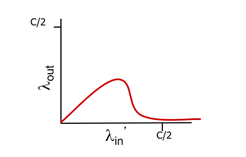
결국 최종 그래프는 위와 같다.
여기서 또다른 congestion cost (congestion의 원인)을 찾을 수 있다.
- packet drop시, 해당 packet을 위해 사용된 upstream transmission capacity와 buffering이 모두 낭비(버려짐)된다!
- 파란 flow의 throughput이 0에 가까워지면, 파란 flow에 들어간 모든 자원이 낭비되는 것이며, 그렇게되면 그 자원을 쓸 수 있었던 다른 flow들 또한 throughput이 0에 가까워진다...
- 최종적으로 네트워크 전체가 붕괴하게 된다.
- 보면 하나의 flow가 7~80%를 차지하는 순간 output rate가 급격히 감소한다.
최종적으로 요점만 살펴보자.
- throughput은 capacity를 초과할 수 없다. (이 경우 R/2)
- 최대 capacity에 가까워질 수록 delay는 증가한다.
- loss와 retransmission은 effective throughput을 감소시킨다. (보내는 양이 더 느니까..)
- Premature timeout으로 인한 un-needed duplicated packet은 또 effective throughput을 감소시킨다.
- Upstream transmission capacity와 buffering은 downstream의 packet loss를 증가시킨다.
그렇다면 이런 이유로 발생할 수 있는 congestion을 control하기 위해선 어떻게 해야될까..?
Congestion control
congestion control은 두 가지로 나눌 수 있는데, 하나는 네트워크의 도움을 아예 받지 않는 end-end congestion control이고, 다른 하나는 Network-assisted congestion control이다.
End-end congestion control
- Network로부터의 명시적 feedback 없음 (network의 정확한 상태 모름)
- loss나 delay를 관찰하면서 congestion인 것을 추론함.
- TCP에서 사용하는 접근법!
Network-assisted congestion control
- Flow가 congested router를 지나게 되면, Router가 sending/receving host에게 직접 feedback을 날린다.
- congestion level이나 sending rate 설정 등을 지시할 수 있다.
- TCP ECN, ATM, DECbit protocol 등에서 사용한다.
이걸 다음 챕터에서 더 자세히 알아보자.
TCP congestion control
이번 챕터에서 우리는 우리가 얼만큼의 data를 network로 보낼 수 있는지 알아내는 방법과, 어떻게 destination에 닿을 수 있는지 등을 자세히 배울 것이다.
여기서 주의할 점은 무턱대고 낮은 rate로 데이터를 보내면 안되는 것이, 너무 적은 data가 network상에 있으면, 이는 Network의 under utilization을 의미하게 된다. (네트워크 관계자들에게 이는 sin이다!)
또한 이렇게 하기 위해서 두 가지 접근 방법이 있을 수 있다. 바로 congestion이 발생하면 그때 처리하는 것(congestion detection)과 congestion이 발생할 것 같은 상황을 감지해서 의도적으로 피하는 것(congestion avoidance)가 그것이다.
그럼 이제부터 Dynamic한 network 상황에서 적당한(congestion이 발생하지 않는 수준에서 최대의 속도)로 데이터를 보내는 기법들에 대해서 알아보자.
AIMD: Additive Increase, Multiplicative Decrease
TCP에서 가장 많이 쓰는 기법 중 하나로, Congestion detection에 속하는 기법이다. 접근은 이제 조금씩 보내는 양을 늘리다가, congestion 발생시 sending rate를 줄이는 것이다.
- Additive Increase: loss가 감지될 때까지, 매 RTT마다 1MSS만큼 보내는 양을 늘린다.
- Multiplicate Decrease: loss 감지시, 보내는 양을 절반으로 줄인다.
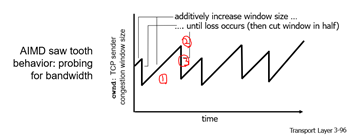
위 그래프를 보면 이해하기가 더 쉽다. (톱날 모양이라서 Sawtooth behavior라고 한다.)
Network resource는 유동적으로 변하기 때문에 따로 threshold값을 사용하진 않는다.
Q. 한 번에 줄일때 왜 발생하지 않을 정도로만 줄이지 반씩 줄이냐?
A. 실제 network에는 무수한 host들이 존재하기 때문에 너무 dynamic해서 계산을 통해 줄이는 것은 쉽지 않다. 또한, 이렇게 확 줄여야 congestion 해소가 빨라진다.
Q. MIAD(두배씩 늘리고, congestion시 1씩 감소)로 해보면 어때?
A. Congestion해소가 너무 느려진다... congestion 발생시 모든 host가 불편함을 느끼기 때문에 이를 빨리 해결하는 것도 관건임.
이 때 언제 반으로 줄이는지에 대해서도 여러 방법이 존재한다.
- Triple duplicate ACK을 통해 loss가 감지되는 경우 Cut half (= TCP Reno)
- Timeout으로 인해 loss 감지시 Cut to 1 MSS (= TCP Tahoe, 더 오래됨)
이를 통해 전체적인 TCP sending을 살펴보자.
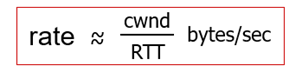
- cwnd(Congestion WiNDow)만큼의 byte를 보내고, RTT만큼 ACK을 기다린다. 그리고, 다시 그만큼 byte를 보낸다.
- TCP sender는 inflight data수가 cwnd를 초과하지 않도록 transmission을 제한한다.
- inflight data = LastByteSent - LastByteAcked
- cwnd는 network congestion을 관찰하면서 조절된다. (TCP congestion control로 구현됨)
slow start (congestion avoidance)
TCP는 connection이 시작되면, 첫 loss 전까진 지수적으로 증가한다. 이때 처음 보내는 양은 1MSS이기 때문에 라고 부른다. 이후 한계값까지 2배씩 보내는 양을 늘림(doubling).
- 해당 증가는 모든 ACK을 받았을 때 2배씩 증가시킨다.
- Host는 단순히 ACK 하나 받을 때마다 2개의 packet을 보내는 식으로 구현할 수 있다.
초기 속도는 느리지만, 기하급수적으로 증가한다.
- 1개씩 올리면 최대 throughput에 도달하기까지 시간이 너무 오래걸림...
- 당연히 bandwidth 사용률도 낮아짐..
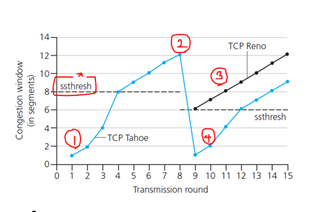
최종적으로 TCP에서 loss detection과 reaction
1. ss_threshold값까진 지수함수적으로 증가.
2. 이후 AIMD로 증가
3-1. timeout 발생시 (징후 발생, Tahoe의 경우) cwnd를 1로 초기화, ssthresh값도 다시 최종 도달한 값의 절반으로 바꿈.
4. 이후 다시 ssthresh값까진 지수함수 적으로 증가, 이후 AIMD
3-2. 혹은 3ACK 발생시, TCP Reno의 경우 해당 시점의 절반 cwnd에서부터 다시 AIMD로 증가
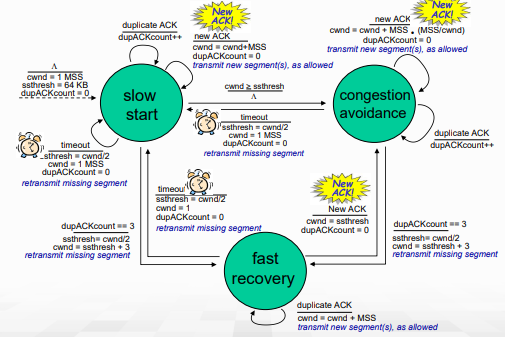
최종 TCP congestion control을 FSM으로 그린 그림이다. slow start를 보면, 처음 ssthresh값은 64KB로 설정되어 있으며, cwnd = cwnd + MSS로 doubling해주는 모습을 확인할 수 있다. 만약 cwnd가 ssthresh를 넘는 경우 congestion avoidance로 넘어가서, dupACK이 3개가 될 때까진 AIMD로 증가시킨다.
congestion avoidance에서는 dupACK이 3개가 되면 fast recovery로 넘어가고, ssthresh값을 현재 cwnd/2로 cwnd는 ssthresh+3으로 설정된다. timeout시 ssthresh는 똑같이 현재 cwnd/2로 설정하지만 cwnd 자체는 1MSS로 줄인다.
- 3dupACK의 경우 최소한의 packet이 receiver까지 도달했음을 의미한다. (덜 심각)
- 즉, timeout으로 인한게 더 심각하다! (그래서 cwnd를 1MSS로 파괴해버림)
이 fast recovery에선 여전히 window size만큼의 dupACK이 더 올 수 있기 때문에, 해당 dupACK에 대한 처리를 해준다. 최종적으로 timeout이 되면 slow start로, New ACK이 오면 congestion avoidance로 이동한다.
각각의 상황에 대해서 잘 볼 필요가 있다.
TCP CUBIC
번외로 가르쳐주신 CUBIC. 우리 학교의 김유성 교수님 논문이라고 한다.. 실제 리눅스에서 채택한 방법이라고.
만든 동기:
아무리 한 host가 congestion을 줄인다고 해도 bottleneck link의 congestion state가 드라마틱하게 변경되지는 않는다.
- Wmax는 congestion loss가 감지됐을 때의 sending rate라고 하자.
- loss시 rate와 window를 절반으로 줄이고, 처음에는 Wmax를 빠르게 키우고 Wmax에 가까워질수록 더 천천히 증가하도록 만든 것.
그래프는 아래와 같다.
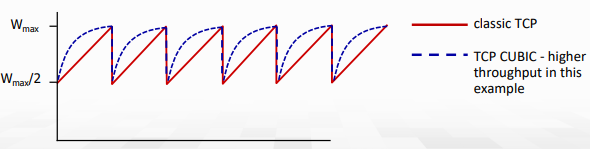
K를 TCP window가 Wmax에 가까워지는 시점이라고 하자. (K는 조절가능) 이때 window는 time과 K 사이의 거리에 3제곱으로 속도를 증가시킨다.
- K에서 멀면 더욱 빠르게 증가
- K에서 가까우면 더욱 느리게 증가
위 그래프에서 congestion이 없는 상황을 가정해 연장하면 아래 그래프가 그려진다.
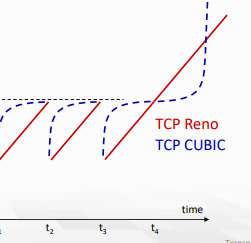
K에 가까울수록 느리고, 멀수록 빠르기 때문에 처음엔 느리게 오르다가 나중엔 급격히 오르는 모습을 볼 수 있다.
- congestion 상황은 짧은 시간내에 바뀌지 않기 때문에 해소된 후에 빠르게 다시 최대 throughput을 점유할 수 있는 방법이다.
Delay-based TCP congestion control
TCP는 일부 라우터에서 packet loss가 발생할 때까지 TCP sending rate를 증가시킨다. 이때 bottleneck link에서 packet loss가 발생하게 된다.
-
많이 보내봐야 congestted bottleneck이 존재하면, end-end throughput은 늘어나지 않는다.
-
Keep end-end pipe just full, but not fuller
- queue가 비는 것은 link under-utilization을 의미. 안좋음
- bottleneck link가 계속해서 transmitting하도록 유지, 하지만 delay나 buffering은 피하도록..
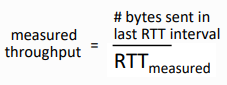
- RTT min값을 구해두고, cwnd/RTTmin을 해서, 이 값과 현재의 측정 값을 비교. 차이가 많이 나면, 선형으로 증가시키고, 차이가 적게나면 선형으로 감소시키기.
이렇게 congestion을 의도적으로 피하는 기법이 congestion avoidance이다. congestion 후에 control을 하면 이미 loss를 경험하게 되는 것이니까 좋지 않다. 반면 delay-based에서는 queue가 길어지면 sending rate를 낮춰 loss가 나기 전에 handling한다.
- 배포된 TCP들 중 일부는 이런 delay-based 접근법을 사용한다.
Explicit Congestion Notification (ECN)
TCP는 network-assisted congestion control도 구현한다.
- IP header의 2비트가 network router에 의해서 congestion시 mark된다.
- network operator에 의해서 marking할지 말지 결정됨
- congestion indication은 destination에 전달되고, destination에서는 ECE bit를 set해서 다시 sender에게 보냄으로써 congestion임을 알린다.
- IP(ECN 비트)와 TCP(C,E bit marking) 헤더 둘 다를 통해 이루어지는 cross-layer control이다.
- layer는 계층간 독립된 것이 특징이지만, 특별한 경우에는 이렇게 여러 layer가 상호작용
TCP fairness
K TCP session이 몇 R의 bandwidth를 갖는 bottlenect link를 공유할 때, 평균 rate는 R/K여야 한다.
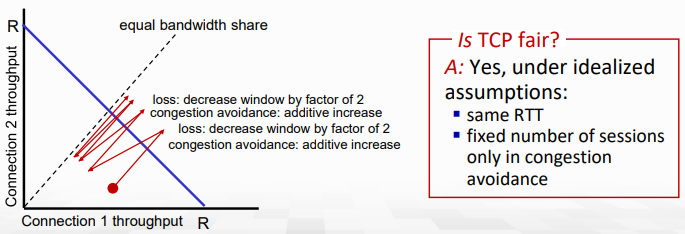
throughput이 증가함에 따라 그래프도 1의 기울기로 점점 증가한다. 그러다가 loss시 반으로 나눈다. (이 과정은 해당 점과 원점을 이은 선분에서 절반 지점으로 설정함)
이 과정이 반복되면 결국 Connection들의 Throughput은 R/2로 수렴하게 된다. 즉, TCP는 공평하다!
- 멀티미디어 app들은 congestion control을 원하지 않기 때문에 TCP를 사용하지 않고 UDP를 쓴다.
- UDP에는 명시적인 congestion control이 없다...
- 때문에 ISP에서는 UDP packet의 rate를 제한해버린다.
- 또한 TCP도 마냥 공평하지는 않다.. TCP는 app단위가 아니라 connection 단위로 공평함을 구현했기 때문이다.
- 한 app이 parallel하게 10개의 connection을 쓰고 다른 건 1개만 쓴다면 첫 번째 app이 10배 더 많은 link를 사용하게 된다.
Evolution of transport-layer functionality
정확히는 UDP를 쓰는 application layer protocol의 발전에 대해서 설명한다.
HTTP3를 다루는 장
TCP, UDP는 40년 전에 구현된 protocol이며, 지금은 여러 상황이 존재한다. TCP는 너무 엄격하기 때문에 여기서의 기능들이 점점 UDP를 쓰는 application layer로 넘어간다.
- HTTP/3: QUIC
QUIC: Quick UDP Internet Connections
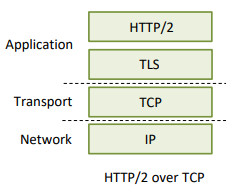
이렇게 구현되어 있던 것을 UDP 위에 TLS와 HTTP를 QUIC이 담당하는 형태로 바꼈다.
HTTP의 성능을 올리기 위해서 개발되었으며, google server, app등에 많이 배포됐다.
하나의 QUIC connection에는 여러 application-level의 stream이 multiplex된다.
- RDT, security를 분리함.
- 일반적인 congestion control 사용
- HTTP 2.1은 1개의 TCP connection을 사용했기 때문에 packet loss시 pipeline이 crash됐다. (data 더 못보냄)
- 반면 QUIC은 UDP를 쓰며 여러 stream이 있어 하나가 고장나면 다른 stream으로 보내면 된다.
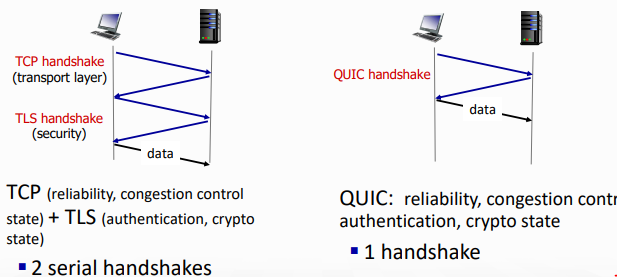
또한 TCP는 3way handshake를 사용했는데 (3RTT), QUIC은 1way이다. (1RTT)
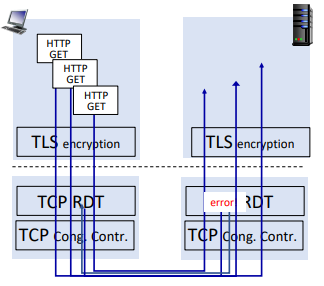
이 상황에서 만약 첫 번쨰 GET에 error가 난다면, 두 번째 GET부터는 첫 번째의 error-retransmit을 기다려야만 했다.
혹은 2.1에서는 pipelining을 통해서 small frame으로 쪼개 보냈는데, 여전히 TCP connection은 하나라서 packet loss시 window size가 반으로 갈라졌고, 이는 전체 성능이 반토막 나는 것을 의미했다.
반면 QUIC에서는 여러 stream이 있어서 하나에서 packet loss가 나도 다른 것들에서는 괜찮다.
TCP 끝... Transport layer는 delay나 bandwidth를 보장하지 않음을 기억하자..
