해당 문제는 SW Expert Academy의 문제로, 개인학습을 목적으로 게시합니다.
자료구조에 대한 충분한 이해가 있다면 쉽게 통과가 가능합니다.
이번 문제에서는 어려운 문제를 만났을 때 어떠한 사고의 흐름으로 대처해야 하는지에 대해 중점을 두고 설명하겠습니다.
Problem
문자열 집합은 알파멧 소문자로 이루어진 문자열들로 구성된 집합을 의미한다.
예를 들어 {"aba", "cdefasad", "wefawef"}은 문자열 3개로 구성된 한 개의 문자열 집합이다.
입력으로 2개의 문자열 집합이 주어졌을 때에, 두 집합에 모두 속하는 문자열 원소의 개수를 출력하는 프로그램을 작성하시오.
[입력]
첫 번째 줄에 테스트 케이스의 수 T가 주어진다.
각 테스트 케이스마다 첫 번째 줄에 두 집합의 원소의 갯수를 나타내는 두 자연수 N M(1≤N, M≤105)이 주어진다.
둘째 줄에는 첫 번째 집합의 원소 문자열들이 공백을 사이에 두고 주어진다.
셋째 줄에는 두 번째 집합의 원소 문자열들이 공백을 사이에 두고 주어진다.
각 문자열은 소문자 알파벳으로만 구성되며, 길이가 1 이상 50 이하임이 보장된다.
한 집합에 같은 문자열이 두 번 이상 등장하지 않음이 보장된다.
[출력]
각 테스트 케이스마다 첫째 줄에 ‘#x’(x는 테스트케이스 번호를 의미하며 1부터 시작한다)를 출력한 다음, 공백을 하나 사이에 두고 해당 테스트 케이스의 답을 출력한다.

Approach
- 일단 문자열을 다루는 문제라는 것을 알 수 있습니다. 저는 헤더파일을 사용하지 않는 것이 목표니, c style의 char array를 사용하여 비교를 하려면
string.h헤더 파일이 필요하거나 비교 로직을 구현하여야 합니다. 따라서comparison operator overloading이 구현되어 있는 c++의 string 클래스를 사용해보겠습니다. - 풀이 조건은 시간이
4s, 메모리가256MB입니다. 이 말은 어떤 부분에서 시간이 굉장히 많이 걸린다는 뜻인데, 그것이 문제를 풀이하는 핵심이 될 것입니다. - 데이터의 사이즈가 작으면 단순히 brute force나 정렬과 같은 여러 가지 방법으로 풀 수 있겠지만, 이 정도 크기는 탐색 문제입니다. 데이터의 중복을 검사하기 위해서는 배열 안에 같은 데이터가 존재하는지 탐색을 하여야 하기 때문이죠. 데이터가 크고, 정수가 아니기 때문에
comparison과swap에 들어가는 연산 비용이 만만치가 않습니다. 따라서 쉽게 생각하면 정렬하여 풀면 되지만 이 문제는 풀리지 않을겁니다.
실제로 그런지 하나씩 살펴보겠습니다.
처음부터 가장 좋은 알고리즘이 나오는 것은 어렵습니다.
항상 문제는 성능을 떠나서 본인이 이해할 수 있는 쉬운 방법으로 문제를 풀어보는 것부터 시작하여야 합니다.
Implement
Thinking1: Brute force
처음 보고 떠올릴 수 있는 생각은 한 집합을 미리 다 받은 다음에, 다음 집합의 원소를 받을 때마다 중복인지 아닌지 이중 for문을 돌면 될 것 같습니다.
#include<iostream>
using namespace std;
string sN[100000], sM[100000];
int main(int argc, char** argv)
{
int test_case;
int T, N, M, i, j;
scanf("%d", &T);
for(test_case = 1; test_case <= T; ++test_case)
{
int cnt = 0;
scanf("%d %d", &N, &M);
for(i = 0; i < N; i++) cin >> sN[i];
for(i = 0; i < M; i++) {
cin >> sM[i];
for(j = 0; j < N; j++){
if (sM[i] == sN[j]){
cnt++;
}
}
}
printf("#%d %d\n", test_case, cnt);
}
return 0;
}
당당하게 4초가 넘어가며 Fail입니다. 여기서 4,001ms는 4초를 아슬아슬하게 넘겼다는 의미가 아니라 4초를 넘어갔기에 더 이상 채점하지 않고 종료한 것입니다.
주어지는 문자열 집합의 수가 각각 100,000개입니다. 각 문자열의 길이 또한 최대 50이니 생각보다 상당한 데이터 길이입니다.
Thinking2: Insertion sort
그렇다면 for문을 도는 횟수를 줄여야 할 것 같습니다.
어떻게 하면 반복 횟수를 쉽게 줄일 수 있을까요?
바로 정렬을 하는 것입니다. 반복은 정렬할 때만 필요하고, 정렬이 끝난 배열에서 같은 문자열은 나란히 있을테니 말이죠.
고급 정렬 알고리즘 구현은 시간이 걸리기 때문에 단계적으로 쉬운 편에 속하는 insertion sort부터 구현해봅니다.
#include<iostream>
using namespace std;
string s[200000];
int main(int argc, char** argv)
{
int test_case;
int T, N, M, i, j;
scanf("%d", &T);
for(test_case = 1; test_case <= T; ++test_case){
scanf("%d %d", &N, &M);
int cnt = 0;
for(i = 0; i < N+M; i++) cin >> s[i];
for(i = 1; i < N+M; i++) {
for(j = i; j > 0 && s[j-1] > s[j]; j--){
string t = s[j];
s[j] = s[j-1];
s[j-1] = t;
}
}
for(i = 1; i < N+M; i++){
if(s[i - 1] == s[i]) cnt++;
}
printf("#%d %d\n", test_case, N+M-cnt);
}
return 0;
}
Thinking3: Quick sort
아쉽게도 Fail입니다. Insersion sort 정도로는 어림도 없는 것 같으니 Quick Sort를 구현해보겠습니다.
템플릿과 DFS를 사용하여 구현하였습니다.
#include<iostream>
using namespace std;
string s[200000];
template<class T>
void swap(T *list, int i, int j) {
T tmp = list[i];
list[i] = list[j];
list[j] = tmp;
}
template<class T>
void quick_sort(T *list, int start, int end) {
int st = start, e = end;
T pivot = list[(end + start) / 2];
while (st <= e) {
while (list[st] < pivot) st++;
while (list[e] > pivot) e--;
if (st < e) swap<string>(list, st, e);
st++;
e--;
}
if (e <= start || st >= end) return;
quick_sort<T>(list, 0, e);
quick_sort<T>(list, st, end);
}
int main(int argc, char** argv)
{
int test_case;
int T, N, M, i, j;
scanf("%d", &T);
for(test_case = 1; test_case <= T; ++test_case){
scanf("%d %d", &N, &M);
int cnt = N + M;
for(i = 0; i < N+M; i++) cin >> s[i];
quick_sort<string>(s,0, N+M-1);
for(i = 1; i < N+M; i++){
if(s[i - 1] == s[i]) cnt--;
}
printf("#%d %d\n", test_case, N+M-cnt);
}
return 0;
}
Conclusion: Binary Search Tree
퀵 소트까지 사용하였지만 풀리지 않습니다. 꼼수를 부려보려고 했지만, 애초에 정렬로 풀 수 있는 문제가 아니었습니다.
문제 유형을 빠르게 숙지 하여 애초에 일반적으로 이 정도의 데이터 크기는 정렬로 풀리지 않는다는 감을 습득하는 것이 중요합니다.
아까 말씀드린바와 같이 이 문제는 탐색 문제입니다. 데이터를 빠르게 찾는 것이 중요하기 때문에, 자료구조가 필수적입니다. unordered_map(Hash Table), tree와 같은 Key-Value 혹은 이진 탐색을 사용하면 가장 빠르게 찾을 수 있습니다.
물론 교집합의 개수를 찾는 문제이므로 집합 자료구조인 Set를 사용하여도 가능합니다.
쉽게 hash table을 직접 구현하려면 modular연산을 이용하면 되지만, 100,000만의 크기의 데이터를 구현하려면 Hash function이 좋지 않기 때문에 오히려 충돌 방지 알고리즘을 짜느라 더 고생할 것입니다.
그렇다면 우리가 선택할 수 있는 대안은 Binary Search Tree입니다.(set의 내부도 tree구조입니다.)
Tree 구조는 두 개의 자식 노드만을 가지고 순차적으로 넣기만 하면 되기 때문에 다음과 같이 어렵지 않습니다.
#include<iostream>
using namespace std;
template <class T>
class tree {
class node {
public:
node(T datum) :data(datum) {}
T data = NULL;
node* left = nullptr;
node* right = nullptr;
};
node* head = nullptr, * cur = nullptr;
public:
~tree(){
del(head);
}
void del(node* n){
if (n == nullptr) return;
del(n->left);
del(n->right);
delete n;
}
void input(T datum) {
if (!head) {
head = new node(datum);
return;
}
cur = head;
while (true) {
if (cur->data < datum) {
if (cur->right) cur = cur->right;
else {
cur->right = new node(datum);
break;
}
}
else {
if (cur->left) cur = cur->left;
else {
cur->left = new node(datum);
break;
}
}
}
}
bool exist(T datum) {
cur = head;
while (true) {
if (cur == nullptr) return false;
else if (cur->data == datum) return true;
else if (cur->data < datum) cur = cur->right;
else cur = cur->left;
}
}
};
int main(int argc, char** argv)
{
int test_case;
int T, N, M, i;
char tmp[51];
scanf("%d", &T);
for (test_case = 1; test_case <= T; ++test_case) {
tree<string> data;
scanf("%d %d", &N, &M);
int cnt = 0;
for (i = 0; i < N; i++) {
scanf("%s", tmp);
data.input(string(tmp));
}
for (i = 0; i < M; i++) {
scanf("%s", tmp);
if (data.exist(string(tmp))) cnt++;
}
printf("#%d %d\n", test_case, cnt);
}
return 0;
}
아슬아슬하게 통과하여 최고의 코드는 아니지만 우리 손으로 직접 구현하여 해결하는데 성공하였습니다.
빠르게 입력을 받기 위하여 cin을 사용하지 않고 scanf를 사용하였습니다.
char tmp[51];
scanf("%s", tmp);
data.input(string(tmp));string(tmp)라고 되어 있는 부분은 명시적 형변환이라고 오해할 수 있지만, string의 생성자를 호출한 것입니다.
전체적인 코드를 보면 tree 클래스와 내부에 node 클래스가 있습니다.
node 클래스를 inner class로 선언한 이유는, tree class에서만 사용하는 종속적인 클래스이기 때문에 굳이 독립적으로 두지 않고 private으로 사용할 수 있게 내부 선언을 하였습니다.
node class는 단지 data, left, right 세 개의 멤버만 가지면 됩니다.
tree class는 총 세가지의 함수를 가지고 있습니다.
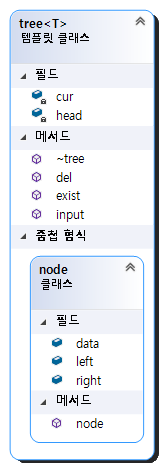
- ~tree(): 한 문제에서 여러개의 테스트케이스를 다루기 때문에 소멸자를 구현하지 않으면, 전에 만들었던 tree 객체가 소멸되더라도 tree 객체가 만든 힙 데이터들은 자동으로 사라지지 않습니다. 따라서 만들었던 node를 재귀적으로 삭제할 수 있는 del 함수를 구현하고 소멸자에서 호출되도록 하였습니다.
- input(T datum): 데이터를 입력받아 저장합니다.
- exist(T datum): tree 내에 데이터가 존재하면 true를, 아니면 false를 반환합니다.

만약 소멸자를 무시하고 구현한다면 위와 같이 약 4배 정도 메모리를 더 사용하게 됩니다.
물론 테스트 케이스가 더 커진다면 아예 통과가 불가능해지겠죠.
이 문제는 소멸자를 사용하지 않더라도 통과가 가능하지만, 우리는 공부하는 입장이니 꼭 구현하도록 합니다.
unordered_set을 사용한 풀이
추가적으로 STL 헤더파일을 사용하는 경우의 코드입니다.
일반 set과 map은 oredered STL 자료구조로 insert할 때마다 정렬이 되어 쌓입니다.
하지만 앞서 해보았듯이, 정렬만 들어가도 연산량이 상당하기 때문에 정렬을 하지 않는 unoreded STL 자료구조를 사용하는 것이 좋습니다.
실제로 일반 set과 map을 사용하면 통과가 불가능합니다.
#include<iostream>
#include<unordered_set>
using namespace std;
unordered_set<string> s;
int main(int argc, char** argv)
{
int test_case;
int T, N, M, i, cnt = 0;
char tmp[51];
scanf("%d", &T);
for (test_case = 1; test_case <= T; ++test_case) {
s.clear();
scanf("%d %d", &N, &M);
int cnt = 0;
for (i = 0; i < N; i++) {
scanf("%s", tmp);
s.emplace(string(tmp));
}
for (i = 0; i < M; i++) {
scanf("%s", tmp);
s.find(string(tmp)) == s.end()? 0:cnt++;
}
printf("#%d %d\n", test_case, cnt);
}
return 0;
}
unoreded_map을 사용한 풀이
#include<iostream>
#include<unordered_map>
using namespace std;
unordered_map<string,char> m;
int main(int argc, char** argv)
{
int test_case;
int T, N, M, i, cnt = 0;
char tmp[51];
scanf("%d", &T);
for (test_case = 1; test_case <= T; ++test_case) {
m.clear();
scanf("%d %d", &N, &M);
int cnt = 0;
for (i = 0; i < N; i++) {
scanf("%s", tmp);
m[string(tmp)];
}
for (i = 0; i < M; i++) {
scanf("%s", tmp);
m.count(string(tmp))? cnt++:0;
}
printf("#%d %d\n", test_case, cnt);
}
return 0;
}
