유니코드 조합문자를 검증하는 과정에서 알게된 내용을 기록합니다.
컴퓨터에서 키릴 문자에 강세 표현을 붙이는 것은 두 개의 문자를 조합하는 방식으로 입력해야 가능한데요.
위 방법이나 조합문자가 어떻게 작성되는지 모를 당시에
강세가 있는 키릴문자를 검증하는 과정에서, 문자열 길이가 각각 1개씩 더해져서 계산되는 것을 보고 왜 그런지 궁금해서 찾아보게 되었습니다.
그 과정에서 알게된 내용을 작성한 문서입니다.
컴퓨터가 문자를 표기하는 방법
컴퓨터가 표시할 수 있는 문자는 여러가지 종류가 존재합니다.
숫자, English, 한글, 韓子 외에도 다른나라의 문자들을 포함하고 심지어는 emoji 까지..👍
이러한 문자들은 어떻게 표기될까요?
이들도 원래대로라면 단순히 0과 1을 조합한 데이터조합이 될 수도 있지만 그건 인간이 알아보기엔 어려울 것입니다.
그래서 그러한 데이터들을 보기 좋게 변환해서 보여주기로했는데 우린 그걸 Encoding 이라 부르기로 했습니다.
ASCII
가장 처음 표준을 만든 미국에서 영문, 숫자, 일부 제한된 특수기호정도를 표기하는 ASCII가 나오기도 했고 일반적인 프로그래밍 언어 레벨에서는 이정도만 있어도 충분했습니다.
ASCII: American Standard Code for Information Interchange
Python에서 ASCII 문자열을 검증하는 방법
sentence = "Hello world. we live in society"
for character in sentence:
order = ord(character)
if 0 <= order <= 127:
print(f"{order}: {character} >> PASS")
else:
print(f"{order}: {character} >> FAIL")1 비트는 0과 1을 표현할 수 있다.
그러므로 최대 2개의 값을 표현을 할 수 있다.
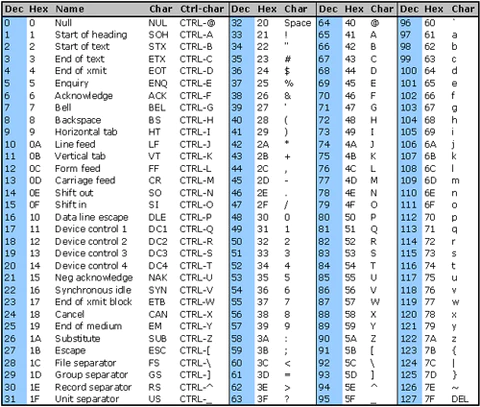
7 비트는 2^7 만큼의 값을 표현할 수 있다.
그러므로 최대 128개의 값을 표현할 수 있다.
7 비트로 구성된 128개의 문자는 실제로 보여지는 것들도 있지만, 제어를 위한 문자도 포함됩니다.
단순하게는 0 ~ 127 범위에 매핑된 문자열을 체크하면 되지만 사용하는 문자는 정해져있어서..
from string import printable
sentence = "Hello world. we live in society"
for character in sentence:
if character not in printable
print(f"{character} is not in ASCII table")위와 같이 string 모듈에 정의된 printable을 가지고 비교해도 충분합니다.
ASCII만으론 부족한데요?
이후 8-bit 프로세서가 대중화되면서 기존에 표현하지 못해서 불편했던 문자들을 떄려박아놓은 Extended ASCII 가 파생되었고, 그 뒤엔 인터넷 보급으로 무수히 많은 사용자들이 유입되었습니다.
이러한 흐름대로 시간이지나면서 여러 언어들을 지원해야할 필요성이 생겼고, 인코딩 종류도 다양해졌습니다.
결국엔 지구상에 있는 거의 모든 문자를 지원하게되면서 유니코드(UTF-8) 표준을 만들게 된 것이 현재의 이야기입니다.
Ref: Unicode table
https://unicode-table.com/en/
나중에 더 많은 문자정보가 등록되어야 하면 어쩌죠?
그런 이슈가 발생하지 않도록 현재의 유니코드 표기법은 가변너비 방식의 인코딩을 하고있습니다.
대략 이런느낌으로 계속 늘어남
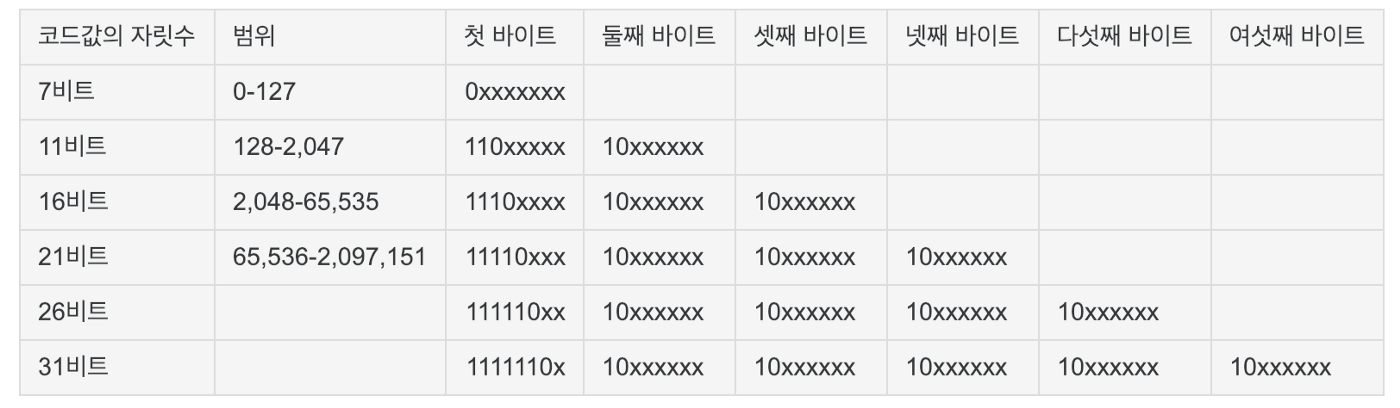
지구가 망할쯤에도 다 못쓸듯 ㅎㅎ; 아니면 다른방식이 나오거나 (아님말고)
이런 유니코드들을 조합해서 사용하여 문제가 되던 부분이 있는데요..
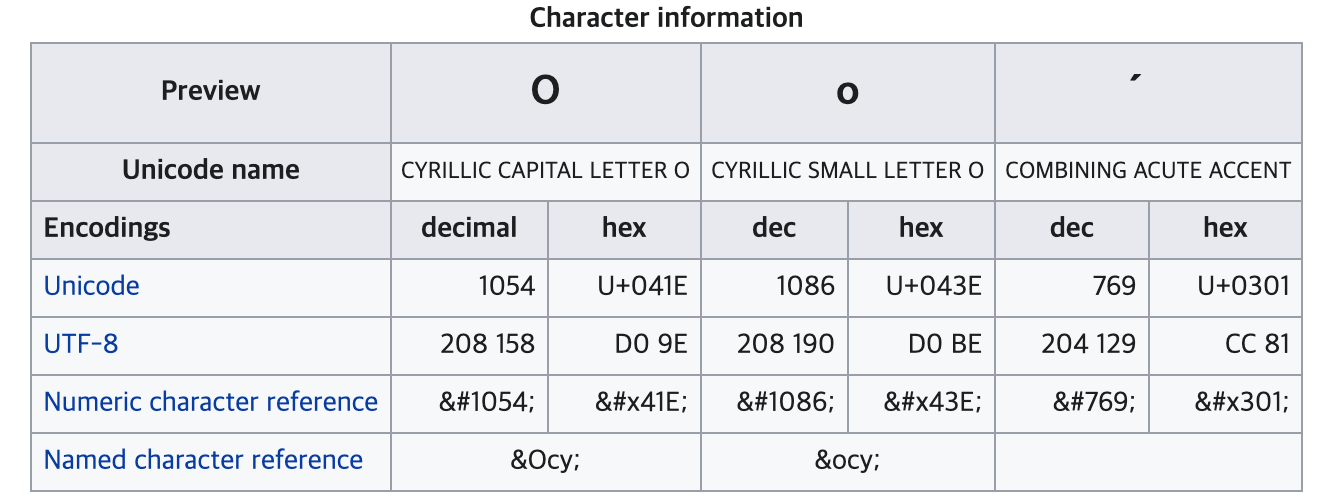
저는 최근에 키릴(Cyrillic)문자로 알파벳 o를 작성하고 강세(Accent)를 준 뒤에 만들어진 문자열 о́를 프로그래밍 레벨에서 검증하는데 어려움을 겪었습니다.
이러한 이유로 키릴문자와 강세 표현을 알아보는 시간을 가졌는데.. 그러면서 습득한 내용을 설명하고 넘어가겠습니다.
키릴문자에서의 강세를 사용하는 이유
사용예시
대문자
А́ Е́ И́ О́ У́ Ы́ Э́ Ю́ Я́ 소문자
á é и́ ó у́ ы́ э́ я́ ю́ 교육목적
러시아 및 주변 동유럽에서 사용하는 키릴문자위에 입력된 강세는 일반적인 작성예시에서 흔히 찾아볼 수 없습니다.
인쇄 및 필기된 텍스트에서는 강세가 생략되기 때문입니다.
강세를 표시하는 주된 이유는 쓰여진 문장을 어떻게 읽어야하는지 알려주기 위한 것이고, 이는 교육적인 목적을 가집니다.
즉, 러시아어를 제 2 언어로 또는 모국어로 학습하기 위한 사전이나 교과서에서만 강세를 볼 수 있습니다.
동음이의어 구분
러시아어로 된 글자 위에 강세를 두는 또 다른 이유가 있습니다.
이것은 강세가 있는 단어에 철자가 비슷하고 의미의 차이가 강세를 통해 표현되는 경우입니다.
아래와 같은 예시가 있습니다.
замо́к [za-mók] – lock
за́мок [zá-mak] – castle잘못 배치된 강세는 이상하게 들리기도 할 것이고, 때로는 강세가 단어의 전체 의미를 바꿀 수도 있습니다.
위와 같은 언어적인 특성도 있지만 다른 여러가지 이유로 강세는 문자열을 표현하는 방법에서 중요한 부분으로 자리잡게되었습니다.
조합문자를 표현하는 방식
이전 내용들에서 알게된 내용을 돌이켜보면 강세를 표기하기위해 어떻게 해야할까? 라는 생각이 듭니다.
강세 하나 표현하겠다고 강세를 붙인 문자를 더 만들어서 유니코드목록에 매핑하자니 공간을 낭비한다고 생각했을겁니다.
이러한 이유로 강세 기호를 만들어놓고 조합하여 사용하도록 하는게 더 효율적일 것 같다고 판단했을거고, 이는 조합문자 개념이 만들어진 이유중 하나일거라 예상됩니다.
Python에서의 조합문자 조회
어느정도 눈치 채셨겠지만 이전의 Python 코드예시에서 보았던 ord()는 문자를 매개변수로 받아서 유니코드 맵의 몇번째 순서로 존재하는지 반환해주는 함수입니다.
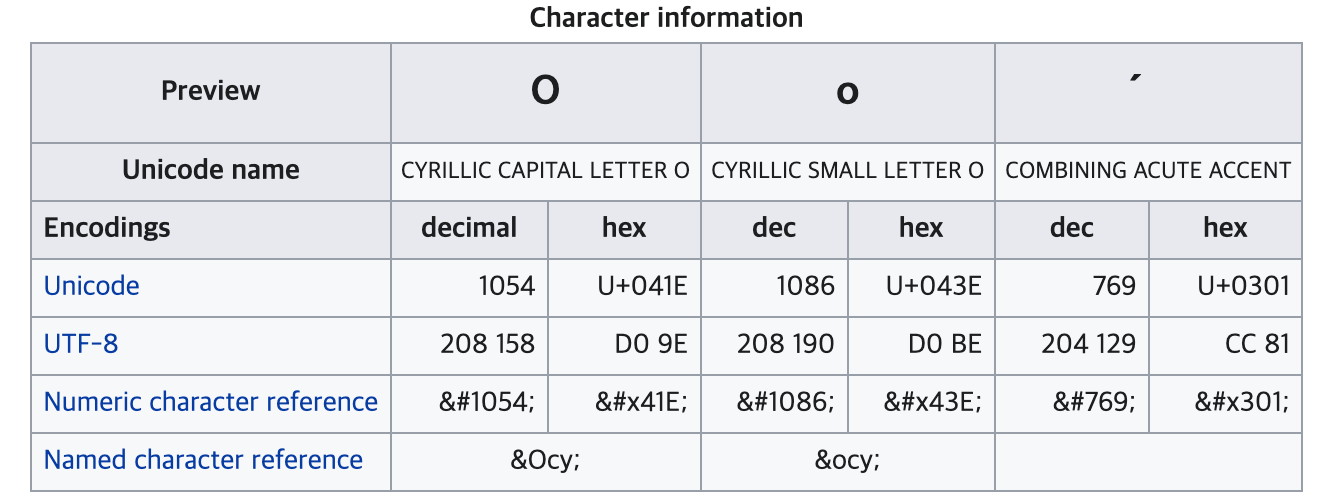
o_with_accent = 'о́'
print(o_with-accent)
>> "о́"
len(o_with_accent)
>> 2
o, accent = o_with_accent
order_o = ord(o)
order_accent = ord(accent)
hex_order_o = hex(order_o)
>> '0x43e'
hex_order_accent = hex(order_accent)
>> '0x301'위 예시에서 볼 수 있듯이..
о́ 문자는 U+043E와 U+0301
두 문자의 조합으로 이루어진 조합문자입니다.
키릴문자를 다루면서 문제가 되던 부분
이쯤되면 이게 어떤 문제를 일으키냐? 라는 생각을 하게될 수도 있고, 분명 난 하나의 문자를 입력했는데 왜 길이가 2일까? 라고 생각할 수도 있습니다.
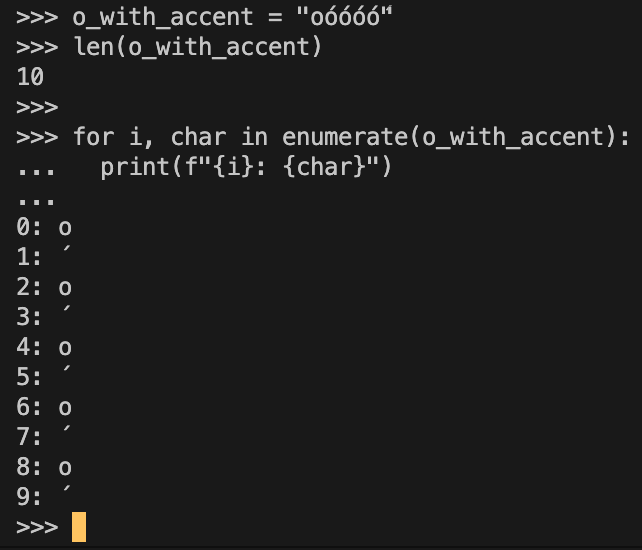
꽤 골때리는 부분이 아닐 수 없습니다.
유저가 느끼기엔 5글자 입력했는데 10글자라뇨
일부 문자열 검사 로직이나, 테스트케이스에서 이러한 문자열을 만나서 로직이 정상작동 하지 않는 상황을 상상해보면 이건 그냥 넘어갈일은 아닙니다.
강세가 있는 문자열의 문자들을 온전히 하나로 인정하는 방법
def unicode_glue(word: str) -> list:
import regex
return regex.findall(r'\X', word)
characters = unicode_glue("о́о́о́о́о́")
print(characters)
>> ['о́', 'о́', 'о́', 'о́', 'о́']
len(characters)
>> 5처음엔 문자열에 강세와 같은 부분 표현이 있으면 그 문자를 제외하고 길이를 계산해야겠다고 생각했습니다.
그런데 대체 얼마나 많은 부분 표현이 있는지도 모르겠고, 작성한다해도 누락되는 경우가 있겠다는 생각이 들었습니다.
그래서 조금 더 찾아보던 중, 자소(grapheme) 기반으로 문자열을 구분할 수 있는 방법이 있다는 내용을 알게되었습니다.
정규표현식으로 구분하려고했는데 도저히 기본 내장된 re 모듈로 해결을 못할 것 같아서 이런저런 내용을 검색하다보니 regex 모듈이 자소(grapheme) 기반의 정규표현식을 지원하고있었고 사용해보니 효과가 있었습니다.
https://pypi.org/project/regex/#:~:text=Matching%20a%20single%20grapheme%20%5CX
pypi: Regex
http://www.unicode.org/reports/tr29/
UAX #29: Unicode Text Segmentation
This annex describes guidelines for determining default segmentation boundaries between certain significant text elements: grapheme clusters (“user-perceived characters”), words, and sentences. For line boundaries, see [ UAX14 ] . Status This document has been reviewed by Unicode members...
www.unicode.org
결론
- 시대의 흐름에 따라 디지털 문자 표기방식도 다양해졌고 그만큼 복잡도가 높아진 것 같다.
- 다양한 인코딩방식의 존재의의에 대하여 생각해보는 시간을 가졌다.
- 유니코드 조합문자를 처음 다뤄보는데, 관련 문자열을 Python에서 다룰때 어떤 방식으로 다뤄야하는지 알아보았다.
실제로 사용할일이 없으면 좋겠지만 문서를 작성해보면서 이런 것들도 있구나.. 라는 인사이트를 얻는 기회가 되었다.
Ref
인코딩 관련 내용
Python 모듈 관련 내용
정규표현식 관련 내용
러시안 문자와 강세에 대한 내용
