multiple classifier
outputs = model(data).to(device)
# omitted ...
predicted = torch.argmax(outputs, axis=1)
for true_class, pred_class in zip(target, predicted):
conf_mat[true_class, pred_class] += 1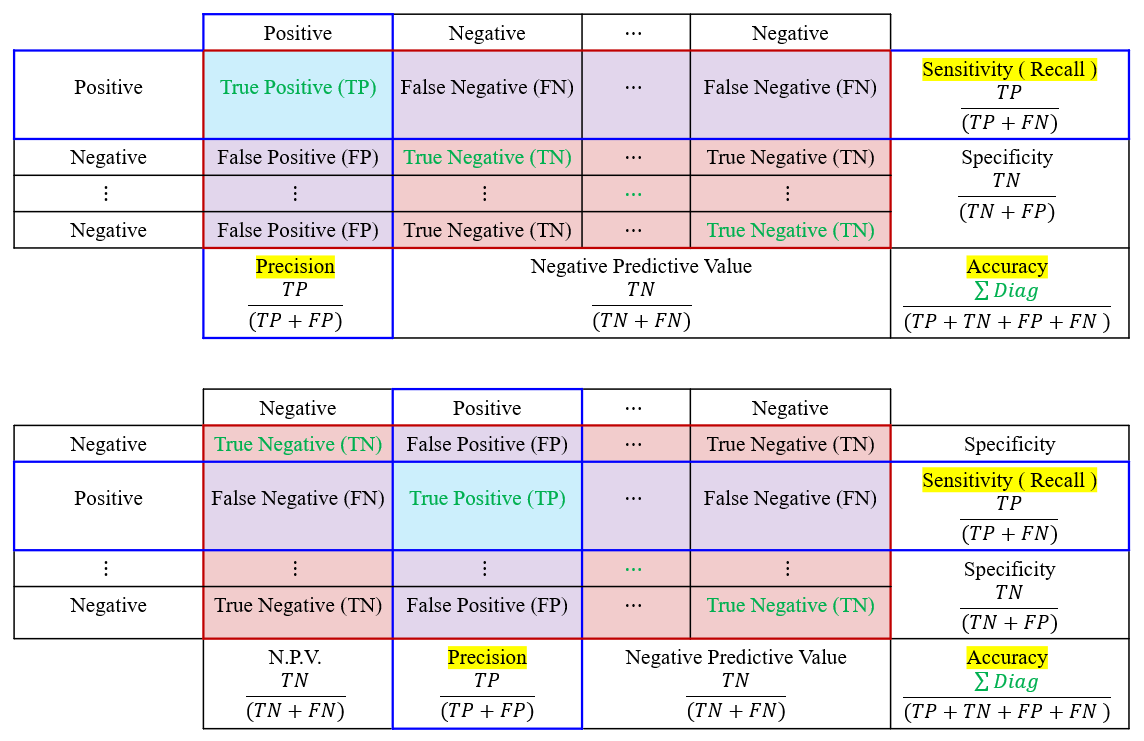
- Accuracy
def Accuracy(conf_mat):
TP = torch.diagonal(conf_mat)
return (torch.sum(TP)/torch.sum(conf_mat)).item()
- Precision ( Positive Predictive Value )
def Precision(conf_mat, class_num):
TP = torch.diagonal(conf_mat)
FP = torch.sum(conf_mat, dim=0) - TP
precision = 0.0
for i in range(class_num):
precision += TP[i] / (TP[i] + FP[i])
return precision.item()/class_num- Recall ( True Positive Rate )
def Recall(conf_mat, class_num):
TP = torch.diagonal(conf_mat)
FN = torch.sum(conf_mat, dim=1) - TP
recall = 0.0
for i in range (class_num):
recall += TP[i] / (TP[i] + FN[i])
return recall.item()/class_num- F1-Score
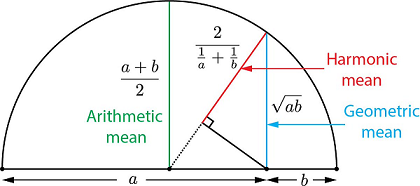
기하학적으로 이해해 보자면, 단순 평균 보다는 작은 길이 쪽으로 치우치게 되고, 따라서 큰 쪽과 작은 쪽의 사이의 값을 가진 평균을 사용하게 된다. 조화평균을 이용하므로써 산술 평균에서의 (큰 쪽의) bias 가 줄어들게 된다.
def F1Score(conf_mat, class_num):
TP = torch.diagonal(conf_mat)
FP = torch.sum(conf_mat, dim=0) - TP
FN = torch.sum(conf_mat, dim=1) - TP
f1score = 0.0
for i in range (class_num):
precision = TP[i] / (TP[i] + FP[i])
recall = TP[i] / (TP[i] + FN[i])
f1score += 2 * (precision * recall) / (precision + recall)
return f1score.item()/class_num