지난 시간 배운 Object 클래스에 이어 자바의 기본 클래스에 대해 좀 더 알아보도록 하겠다.
String
가장 먼저 배울 것은 String 클래스이다. 다른 용어들과 달리 조금은 익숙할 것이다.
우리가 자료형에 대해 배울 때 '참조 자료형'이라고 명시했던 바로 그 String, 문자열을 말하는 것이 맞기 때문이다.
우리가 그동안 생성해왔던 모든 문자열은 사실 문자열 변수를 명시하여 객체를 선언 및 생성한 것이었다.
예를 들자면, String s1 = "Hello"의 경우 s1이라는 참조형 변수를 통해 문자열 객체의 주소를 참조해왔던 것이다.
이렇게 객체를 선언할 때의 문법을 일부 생략하여 문자열 객체를 생성하는 것을 암시적 객체 생성이라고 한다.
반면, String s2 = new String("Hello")와 같이 문법을 그대로 따라 생성자를 활용해 문자열 객체를 생성하는 것을 명시적 객체 생성이라고 한다.
느꼈다시피 문자열의 경우 암시적 객체 생성을 더 많이 사용하는 편이다.
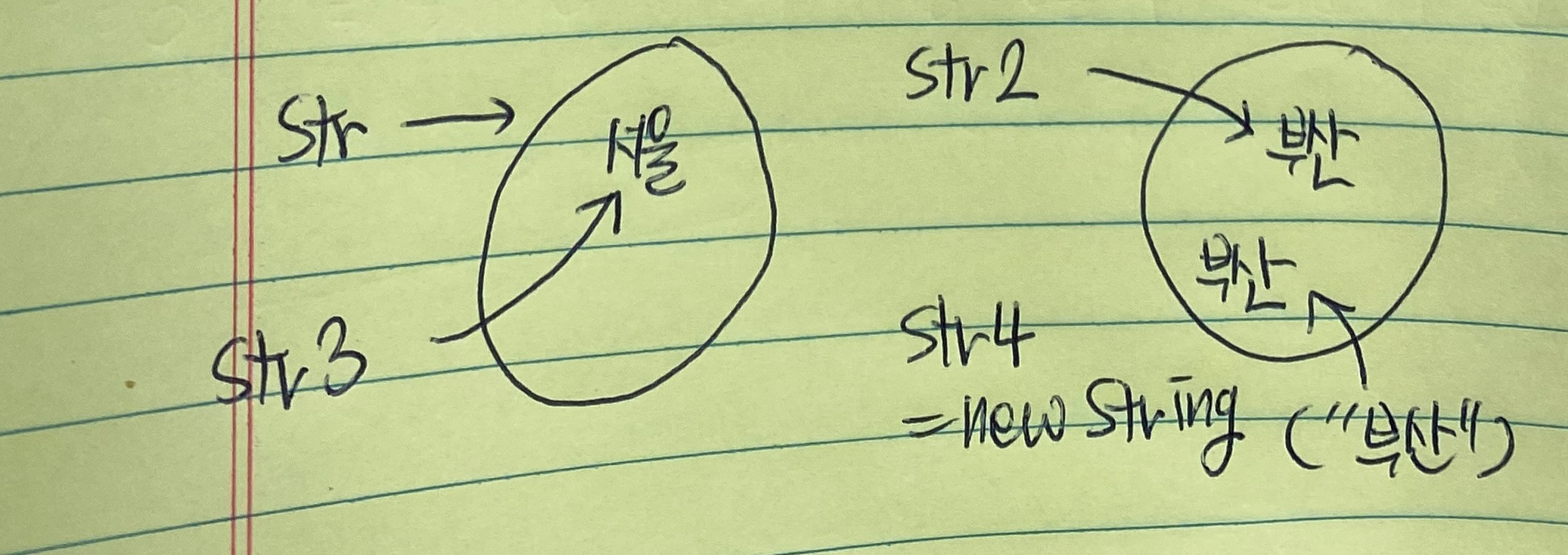
또한, 문자열이 같을 경우 암시적으로 객체를 생성하면 그 객체를 참조형 변수들끼리 공유하지만 명시적으로 만들 경우에는 별도로 생성한다는 점에서 차이가 있다.
첨부한 이미지 속 그림에 나와 있듯 String str = "서울"과 String str3 = "서울"은 하나의 객체를 공유하지만,String str2 = new String("부산")과 String str4 = new String("부산")은 서로 다른 객체를 선언하게 되는 것이다.
이를 String 클래스가 가지고 있는 메서드를 활용하여 눈으로 확인해 보자.
package kr.s26.lang.string;
public class StringMain01 {
public static void main(String[] args) {
//암시적으로 객체 생성
String str1 = "abc";
String str2 = "abc";
//객체 비교
if(str1 == str2) {
System.out.println("str1과 str2는 같은 객체");
}else {
System.out.println("str1과 str2는 다른 객체");
}
//문자열 비교
if(str1.equals(str2)) {
System.out.println("str1의 내용(문자열)과 str2의 내용(문자열)이 같다.");
}else {
System.out.println("str1의 내용(문자열)과 str2의 내용(문자열)이 다르다.");
}
System.out.println("==================================");
//명시적으로 객체 생성
String str3 = new String("Hello");
String str4 = new String("Hello");
//객체 비교
if(str3 == str4) {
System.out.println("str3와 str4는 같은 객체");
}else {
System.out.println("str3와 str4는 다른 객체");
}
//문자열 비교
if(str3.equals(str4)) {
System.out.println("str3의 내용(문자열)과 str4의 내용(문자열)이 같다.");
}else {
System.out.println("str3의 내용(문자열)과 str4의 내용(문자열)이 다르다.");
}
System.out.println("==================================");
String str5 = "bus";
String str6 = "BUS";
if(str5.equals(str6)) {
System.out.println("str5와 str6의 문자열은 같다");
}else {
System.out.println("str5와 str6의 문자열은 다르다.");
}
System.out.println("==================================");
if(str5.equalsIgnoreCase(str6)) {
System.out.println("[대소문자 구분 없이 비교]str5와 str6의 문자열은 같다");
}else {
System.out.println("[대소문자 구분 없이 비교]str5와 str6의 문자열은 다르다.");
}
}
}
-
str1과 str2는 암시적으로 객체를 생성하였고, 그 문자열이 같기 때문에 하나의 객체를 공유한다.
-
객체 비교 시 활용하는 비교 연산자를 통해 이 사실을 검증해볼 수 있다.
if(str1 == str2) {
System.out.println("str1과 str2는 같은 객체");
}else {
System.out.println("str1과 str2는 다른 객체");
}
출력 결과)
str1과 str2는 같은 객체- String이 가지고 있는 equals() 메서드는 문자열 비교 시 사용한다.
str1과 str2은 문자열이 같고, 다음과 같은 결과를 얻을 수 있다.
if(str1.equals(str2)) {
System.out.println("str1의 내용(문자열)과 str2의 내용(문자열)이 같다.");
}else {
System.out.println("str1의 내용(문자열)과 str2의 내용(문자열)이 다르다.");
}
출력 결과)
str1의 내용(문자열)과 str2의 내용(문자열)이 같다.-
반면 str3와 str4 같이 명시적으로 객체를 생성하면, 같은 문자열을 사용해도 각각 새로운 객체를 생성한다.
-
따라서 비교 연산자를 통해 객체 비교 시, 앞선 예제와 다른 결과를 얻게 된다.
if(str3 == str4) {
System.out.println("str3와 str4는 같은 객체");
}else {
System.out.println("str3와 str4는 다른 객체");
}
출력 결과)
str3와 str4는 다른 객체- 하지만 equals() 메서드를 활용하여 문자열 비교 시 두 문자열이 같다는 걸 확인할 수 있다.
if(str3.equals(str4)) {
System.out.println("str3의 내용(문자열)과 str4의 내용(문자열)이 같다.");
}else {
System.out.println("str3의 내용(문자열)과 str4의 내용(문자열)이 다르다.");
}
출력 결과)
str3의 내용(문자열)과 str4의 내용(문자열)이 같다.- 그렇다면 equals()는 언제 활용하는 것이 유리할까? 바로 대소문자를 구분하여 문자열을 비교하고자 할 때이다.
예를 들어 str5와 str6은 암시적으로 객체를 생성하였다. 하지만 우리에게는 같은 의미를 갖는 문자열 bus와 BUS가 equals()에게는 다른 문자열이 된다.
if(str5.equals(str6)) {
System.out.println("str5와 str6의 문자열은 같다");
}else {
System.out.println("str5와 str6의 문자열은 다르다.");
}
출력 결과)
str5와 str6의 문자열은 다르다.- 만약 대소문자를 구분하지 않고 문자열을 비교하길 원한다면, 그때는 equalsIgnoreCase() 메서드를 사용한다.
if(str5.equalsIgnoreCase(str6)) {
System.out.println("[대소문자 구분 없이 비교]str5와 str6의 문자열은 같다");
}else {
System.out.println("[대소문자 구분 없이 비교]str5와 str6의 문자열은 다르다.");
}
출력 결과)
[대소문자 구분 없이 비교]str5와 str6의 문자열은 같다앞서 배운 equals()와 equalsIgnoreCase() 외에도 String에는 다양한 메서드들이 존재하며, 이들은 활용도가 높기 때문에 암기하는 것이 좋다.
package kr.s26.lang.string;
public class StringMain02 {
public static void main(String[] args) {
String s1 = "Kwon Sun Ae";
//012345678910, 길이: 11
int index = s1.indexOf('n');
System.out.println("맨 처음 문자 n의 위치: " + index);
index = s1.indexOf("Sun");
System.out.println("문자열 Sun의 위치: " + index);
index = s1.lastIndexOf('n');
System.out.println("마지막 문자 n의 위치: " + index);
char c = s1.charAt(index);
System.out.println("추출한 문자: " + c);
index = s1.indexOf('s');
System.out.println(index);
index = s1.indexOf('S');
String str = s1.substring(index);
System.out.println("대문자 S부터 끝까지 잘라내기: " + str);
str = s1.substring(index, index+3);
System.out.println("시작 인덱스부터 끝 인덱스 전까지 문자열 추출: " + str);
int length = s1.length();
System.out.println("s1의 길이 : " + length);
String[] array = s1.split(" ");
for(int i=0;i<array.length;i++) {
System.out.println("array[" + i + "]: " + array[i] );
}
}
}
String s1 = "Kwon Sun Ae";
012345678910- indexOf() : 지정한 문자의 맨 처음 인덱스 반환한다.
int index = s1.indexOf('n');
System.out.println("맨 처음 문자 n의 위치: " + index);
출력 결과)
맨 처음 문자 n의 위치: 3- 단, indexOf()는 인자로 전달된 문자열의 길이가 1 이상일 경우, 제일 첫 문자의 위치를 반환한다.
index = s1.indexOf("Sun");
System.out.println("문자열 Sun의 위치: " + index);
출력 결과)
문자열 Sun의 위치: 5- 그리고 indexOf()는 없는 문자열의 경우, 존재하지 않는 인덱스라는 의미로 -1을 출력한다. 아래 예제를 통해 indexOf() 역시 대소문자를 구분한다는 것을 알 수 있다.
index = s1.indexOf('s');
System.out.println(index);
출력 결과)
-1- lastIndexOf() : 지정한 문자의 인덱스를 맨 뒤부터 찾아서 반환한다.
index = s1.lastIndexOf('n');
System.out.println("마지막 문자 n의 위치: " + index);
출력 결과)
마지막 문자 n의 위치: 7- charAt() : 지정한 인덱스를 통해서 문자를 반환한다. 3번의 결과로 index에 담겨 있던 7에 해당하는 문자 n이 반환된 것을 확인할 수 있다.
char c = s1.charAt(index);
System.out.println("추출한 문자: " + c);
출력 결과)
추출한 문자: n- subString() : 지정한 인덱스부터 끝 인덱스까지의 문자열을 추출한다. subString()이 indexOf()를 통해 지정한 문자열 'S'의 인덱스 5부터 끝 문자열까지 추출한 것을 확인할 수 있다.
index = s1.indexOf('S');
String str = s1.substring(index);
System.out.println("대문자 S부터 끝까지 잘라내기: " + str);
출력 결과)
대문자 S부터 끝까지 잘라내기: Sun Ae- 만약 subString()에 두 개의 인자가 들어갈 경우 첫 번째 인자를 시작 인덱스, 두 번째 인자를 끝 인덱스로 하여 시작 인덱스부터 끝 인덱스 '전까지' 문자열을 추출한다.
index(문자열 S의 위치)인 5와 8을 인자로 넣은 결과 8 전인 5~7까지의 문자열만이 추출된 것을 확인할 수 있다.
str = s1.substring(index, index+3);
System.out.println("시작 인덱스부터 끝 인덱스 전까지 문자열 추출: " + str);
출력 결과)
시작 인덱스부터 끝 인덱스 전까지 문자열 추출: Sun- length() : 문자열의 길이를 구한다. 문자열 역시 하나의 배열로 인식되기 때문에 그 인덱스가 0부터 시작하기 때문에 문자열의 길이는 항상 '끝 인덱스+1'이라는 점을 기억해 두면 좋다.
int length = s1.length();
System.out.println("s1의 길이 : " + length);
출력 결과)
s1의 길이 : 11- split() : 전달된 인자를 구분자로 삼고, 그 구분자를 기준으로 문자열을 나누고 배열에 담아 반환한다.
String[] array = s1.split(" ");//공백을 구분자로 처리
for(int i=0;i<array.length;i++) {
System.out.println("array[" + i + "]: " + array[i] );
}
출력 결과)
array[0]: Kwon
array[1]: Sun
array[2]: Aepackage kr.s26.lang.string;
public class StringMain03 {
public static void main(String[] args) {
String s1 = " aBa ";
String s2 = "abc";
int a = 100;
String msg = null;
msg = s1.toUpperCase();
System.out.println("msg:" + msg);
msg = s1.toLowerCase();
System.out.println("msg:" + msg);
msg = s1.replace("aB", "b");
System.out.println("msg:" + msg);
msg = s1.trim();
System.out.println("msg:" + msg);
boolean f = s1.contains("aB");
System.out.println("f:" + f);
f = s2.startsWith("ab");
System.out.println("f:" + f);
f = s2.endsWith("bc");
System.out.println("f:" + f);
//int -> String
msg = String.valueOf(a);
msg = a + "";
System.out.println(msg.length());
}
}
String s1 = " aBa ";//앞 뒤로 공백 두 칸씩
String s2 = "abc";
int a = 100;
String msg = null;//객체 생성이 되지 않아 주소가 없다는 뜻- toUpperCase() : 문자열을 대문자로 반환한다.
msg = s1.toUpperCase();
System.out.println("msg:" + msg);
출력 결과)
msg: ABA - toLowerCase() : 문자열을 소문자로 반환한다.
msg = s1.toLowerCase();
System.out.println("msg:" + msg);
출력 결과)
msg: aba - replace() : 첫 번째 인자의 문자열을 두 번째 인자의 문자열로 대체한다.
msg = s1.replace("aB", "b");
System.out.println("msg:" + msg);
출력 결과)
msg: ba - trim() : 앞 뒤 공백을 제거하는데, 이때 문자열 중간에 있는 공백은 불가하다.
msg = s1.trim();
System.out.println("msg:" + msg);
출력 결과)
msg:aBa- contains() : 지정한 문자열이 포함되어 있으면 true를 반환한다.
boolean f = s1.contains("aB");
System.out.println("f:" + f);
출력 결과)
f:true- startsWith() : 지정한 문자열로 시작할 경우 true를 반환한다.
f = s2.startsWith("ab");
System.out.println("f:" + f);
출력 결과)
f:true- endsWith() : 지정한 문자열로 끝나는 경우 true를 반환한다.
f = s2.endsWith("bc");
System.out.println("f:" + f);
출력 결과)
f:true- String.valueOf() : int 타입의 데이터를 String 타입의 데이터로 형변환한다.
int 타입의 데이터int a = 100;가 String으로 변환되어 length()로 길이를 구할 수 있게 된 것을 확인할 수 있다.
msg = String.valueOf(a);
System.out.println(msg.length());
출력 결과)
3- 또한, int 타입의 데이터를 String 타입으로 변환하는 방법이 한 가지 더 존재한다. 바로 "" (빈 문자열)과 연결하는 것이다. 빈 문자열은 객체 생성이 되지 않아 주소가 없다는 뜻의 null과 달리, '형식적인 문자열'로 객체는 있는데 내용은 없는 상태를 말한다.
msg = a + "";
System.out.println(msg.length());
출력 결과)
3이를 바탕으로 간단한 실습 2가지를 진행하였다.
package kr.s26.lang.string;
import java.util.Scanner;
public class StringMain04 {
public static void main(String[] args) {
/*
* [실습]
* 입력받은 문자열을 한 문자씩 읽어서 역순으로 표시하시오.
*
* [입력 예시]
* 문자열: hello
*
* [출력 예시]
* olleh
*/
Scanner input = new Scanner(System.in);
System.out.print("문자열: ");
String st = input.nextLine();
for(int i=st.length()-1;i>=0;i--) {
System.out.print(st.charAt(i));
}
input.close();
}
}
-
Scanner를 통해 문자열을 입력 받는다.
-
for문을 돌며 역순으로 인덱스를 반복할 수 있도록 '입력받은 문자열의 길이 - 1'에서 0까지
*입력받은 문자열의 길이 -1 = 끝 인덱스 -
감소 연산자를 사용해 i를 줄여나가는 조건문을 작성한다.
ex.for(int i=st.length()-1;i>=0;i--) -
수행문에서는
charAt()에 동적으로 변화하는 i를 넘겨 전달된 인덱스에 맞는 문자열을 출력할 수 있도록 한다.
이때 줄바꿈되지 않도록System.out.print()를 사용한다. -
작업이 끝나면 자원을 정리한다.
-
우리가 입력한 순서대로 출력하는 코드는 아래와 같다.
for(int i=0;i<n.length();i++){
System.out.print(ch.charAt(i));
}package kr.s26.lang.string;
public class StringMain05 {
public static void main(String[] args) {
/*
* [실습]
* str 변수에 저장된 값을 대문자 -> 소문자로
* 소문자 -> 대문자로 변환하시오.
*
* [출력 예시]
* ABCmdYE-4w?ewZZ
*
*/
String str = "abcMDye-4W?EWzz";
String result = "";
for(int i=0;i<str.length();i++) {
char c = str.charAt(i);
if(c >= 65 && c <= 90) {//대문자
result += String.valueOf(c).toLowerCase();
}else if(c >= 97 && c <= 122) {//소문자
result += String.valueOf(c).toUpperCase();
}else {
result += c;
}
}
System.out.println(result);
}
}
-
가장 먼저 for문 안에서
charAt()메서드를 통해 루프를 돌며 문자열 str을 하나씩 읽은 다음, 문자 변수char c에 담는다. -
해당 문자열이 대문자인지, 소문자인지, 특수문자인지 경우의 수를 나누어 변환해주기 위해 대소문자를 판별할 수 있도록 아스키코드를 활용해 if문으로 분기한다.
대문자 : A(65) ~ Z(90)
소문자 : a(97) ~ z(122) -
만약 대문자라면 =
if(c >= 65 && c <= 90)우선String.valueOf()를 통해 문자를 다시 문자열로 변환한 다음,toLowerCase()를 통해 소문자로 변환해준다.
이때 객체는 메서드 동작 후 자기 자신을 그대로 반환하기 때문에 String.valueOf() 뒤에 .을 붙인 다음 다른 메서드를 이을 수 있다. -
그 다음
String result라는 새로운 변수에 누적(+=)한다. -
만약 소문자라면 =
else if(c >= 97 && c <= 122)동일하게String.valueOf()를 통해 문자를 다시 문자열로 변환한 다음,toUpperCase()를 통해 대문자로 변환해 준다. -
그리고 역시
String result에 누적해준다. -
만약 대소문자가 아니라면, 변환 작업이 불필요하므로 그냥 누적한다. 특수문자의 경우 추가로 변환 작업이 필요하지 않기 때문에 누적 과정에서 자동으로 문자 → 문자로 형변환된다.
-
그렇게 차곡차곡 누적된 변수 result를 출력하면 대문자는 소문자로, 소문자는 대문자로 변환된 것을 확인할 수 있다.
