
인공지능, 머신러닝, 딥러닝
인공지능
- 인공(Artificial) + 지능(Intelligence) -> AI
ex) 로봇청소기, Expert system
머신러닝
- 학습(learning)하는 기계(machine) -> 학습 기반
ex) Decision tree, SVM
딥러닝
- 깊은(deep) 신경망 구조의 머신러닝
ex) MLP, CNN, RNN, Transformer

학습(learning)의 개념과 원리
머신러닝의 기본 구조

데이터셋 분할(split)
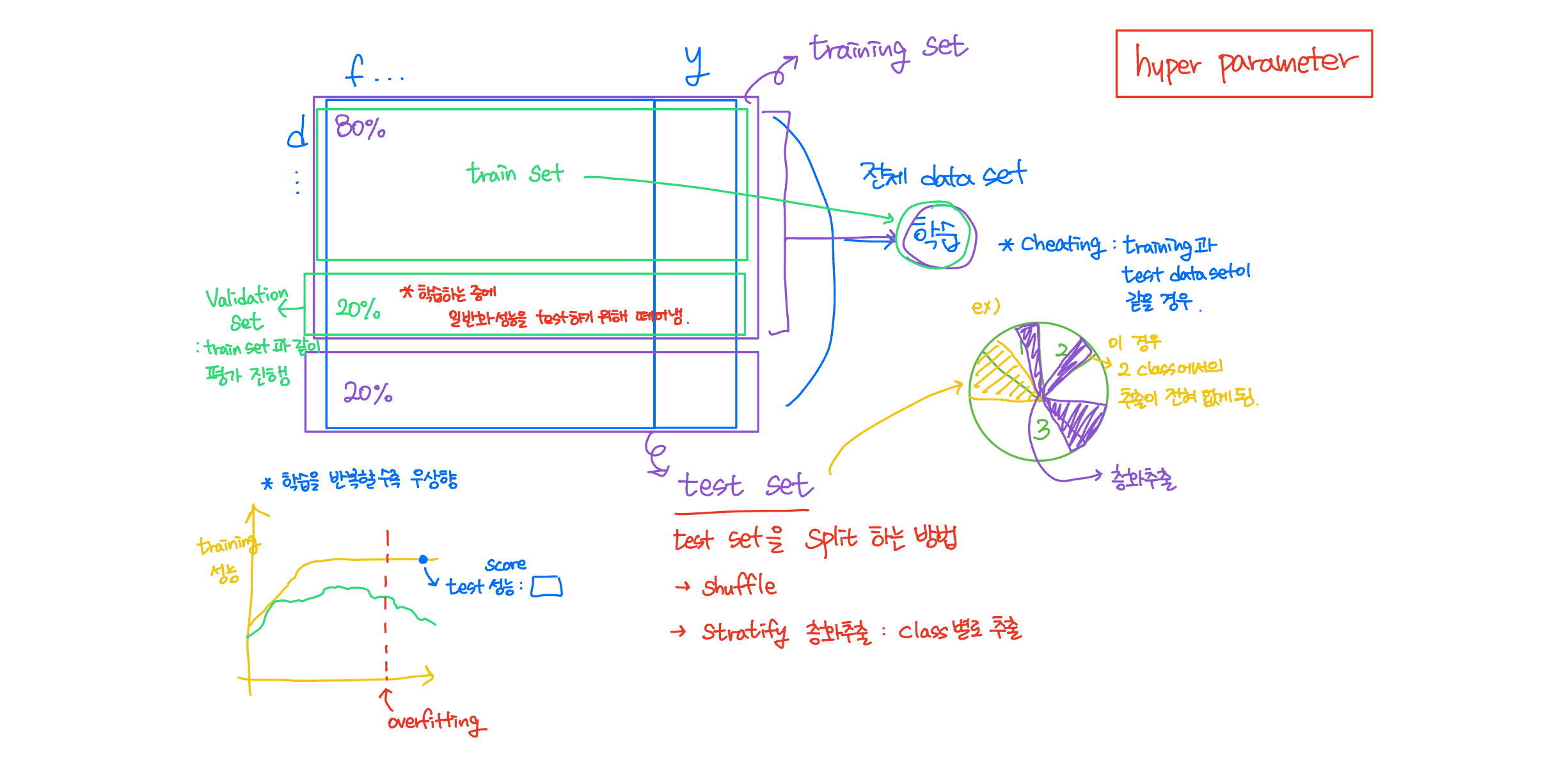
- 학습을 위해 전체 Data set 에서 80%를 training set으로 학습
- 학습이 끝나면 model의 성능 평가를 위해 test set 실행
=> 객관적인 모델의 성능 평가 가능
지도학습(supervised learning)과 비지도학습(unsupervised learning)
지도학습(Supervised Learning)
-
Dataset = Data + Label
- 입력 데이터와 해당 데이터에 대한 정답 또는 원하는 출력을 나타내는 "Label"이 함께 제공 - 모델은 입력 데이터와 라벨을 사용하여 입력 데이터에서 출력을 예측하고, 예측과 실제 라벨 간의 차이를 최소화하도록 학습됨 - 대부분의 연구, 산업에서 이용되는 학습법
비지도학습(Unsupervised Learning)
-
Dataset = Data
+ Label- 입력 데이터에 대한 명시적인 라벨 또는 정답이 제공되지 않는 학습 방법 - 비지도 학습에서 "Label"은 입력 데이터 그룹을 설명하거나 클러스터링(cluster)을 할 때 사용 - 비용적인 측면에서 가성비가 좋음 - K-Means Clustering(군집화)
반지도학습(Semi-Supervised Learning)
-
지도학습 + 비지도학습
- Pseudo-labeling 1. 초기 지도학습: 가지고 있는 작은 양의 레이블 데이터로 모델을 초기화하고 학습 2. 가상 레이블 생성: 학습된 모델을 사용하여 레이블이 지정되지 않은 추가 데이터(비지도 데이터)에 대한 예측을 수행 3. 가상 레이블을 추가하여 재학습: 가상 레이블과 함께 초기 레이블이 있는 데이터도 함께 사용하여 모델을 조정하고 성능을 개선 4. 반복 * kaggle 이나 많은 competition에서 자주 등장하는 개념(pseudo-labeling을 사용해도 된다는 조항이 있어야 함)
선형회귀(linear regression)
선형 회귀
-
Linear + Regression : 선을 그어 + 값을 예측
-
통계학에서의 Linear Regression 과 딥러닝에서의 Linear Regression
[ 통계학 ] 1. 데이터 분석 및 추론을 위해 사용 2. 통계적 선형회귀 모델은 주어진 데이터를 기반으로 독립 변수와 종속 변수 간의 관계를 설명하고, 모수 추정, 가설 검정, 신뢰구간 등의 통계적 절차를 사용하여 이런 관계를 분석하는 데 중점을 둠. 3. 모델의 신뢰성과 해석력이 중요함 [ 딥러닝 ] 1. 선형 회귀는 머신 러닝의 일부로, 데이터로부터 예측 모델을 구축하는 데 사용 2. 모델은 입력과 출력 간의 관계를 학습, 최적화 기술을 사용하여 모델의 예측 성능을 최대화하는 데 중점을 둠. 3. 대규모 데이터와 복잡한 모델 아키텍처를 사용하여 성능을 향상 시키는 것이 주요 목표
편향(Bias)
-
통계학에서의 Bias 와 딥러닝에서의 Bias
[ 통계학 ] - 추정치가 모집단의 실제 값과 얼마나 차이가 있는지를 나타냄. - 주로 통계적 추정에서 사용 - 편향된 추정치는 모집단 parameter를 평균적으로 정확하게 예측하지 못하는 경향이 있음 [ 딥러닝 ] - 뉴럴 네트워크 모델의 일부 - 모델이 데이터를 잘 적합시키기 위한 parameter 중 하나를 나타냄. - bias는 복잡한 데이터 패턴을 학습하고 적합하게 만들 수 있도록 도와주는 요소 - 딥러닝에서는 bias가 모델의 효율성과 성능 향상에 중요한 역할을 함.
선형회귀 입력과 출력

-
H(x) = w1x1 + w2x2 + w3x3 + b
-
선형회귀란?
- 3개의 특성에 각각의 가중치의 곱에 대한 전체 합을 통해 새로운 특성을 생성하는 구조
-
가중치(w)란?
-
해당 feature 가 어떤 방향으로 어느 정도 영향을 미치는지 상관관계를 나타내는 지표
- w1 의 경우 x1 이 증가함에 따라 H 가 증가하기 때문에 양수를 나타냄
- w3 의 경우 x3 가 감소함에 따라 H 가 증가하므로 음수를 나타냄
-
|w| 이 크면 클 수록 x 가 H 에 미치는 영향이 크다고 볼 수 있음
-

역시 깔끔한 정리입니다. 앞으로도 화이팅이에요!