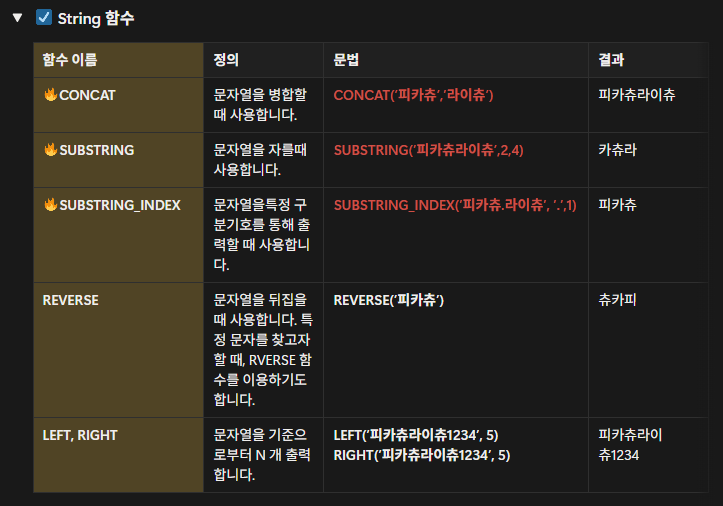
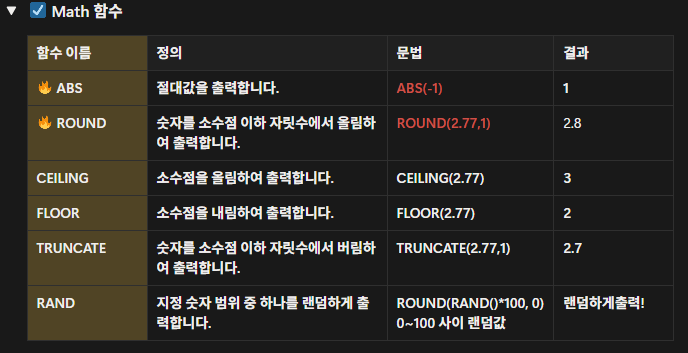
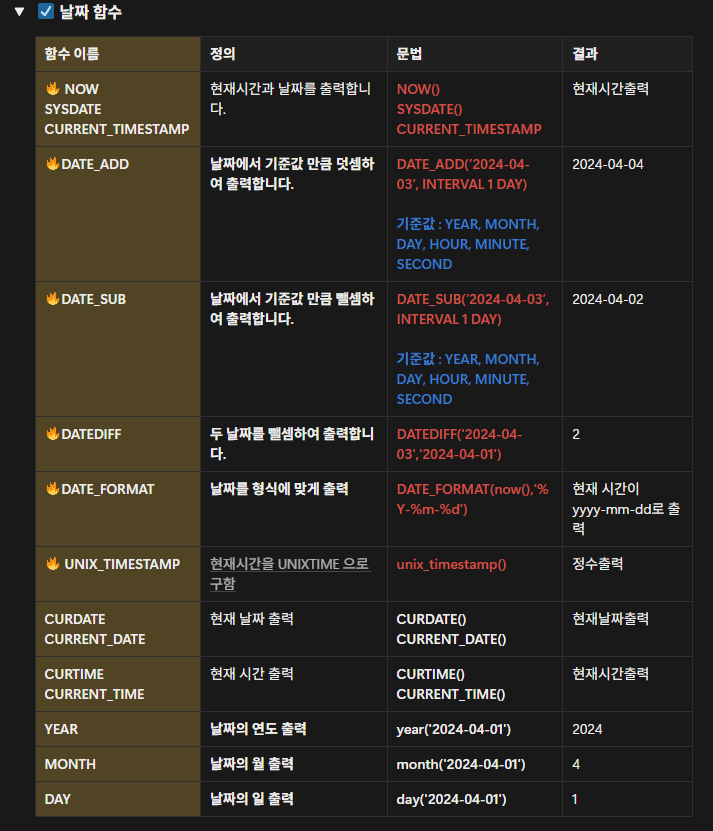
FROM → ON → JOIN → WHERE → GROUP BY → HAVING → SELECT → DISTINCT → ORDER BY
SQL 동작 순서를 명시
알아두고 항시 습관화하기
오늘한 SQL, PYTHON 이론 및 실습을
복습하고 다시 한 번 풀어보았다.
눈으로는 당연하지만, 내 머릿 속에서 찾아 표현하는 것은 당연하지가 않다..
(학습에 한정하지 않고)
앞으로 행동하고 발생하는 모든 현상에 대해 논리적으로 생각하고, '왜?' 를 계속 떠올리자..!
물음에 대한 답변을 하지 못 하면 모르는 것이고, 부족한 것이다.
SQL WINDOW FUCTION
테이블의 행과 행 간의 관계를 정의하기 위해 제공되는 함수
→ 여러 행의 관계를 파악하기 위해 사용, 분석 OR 순위 함수로 알려져 있음종류는 다음과 같다.
종류 함수 순위RANK, DENSE_RANK, ROW_NUMBER 집계SUM, MAX, MIN, AVG, COUNT 순서FIRST_VALUE, LAST_VALUE, LAG, LEAD 비율RATIO_TO_REPORT, PERCENT_RANK, CUME_DIST, NTILE 우리가 기존에 알고 있던 집계함수 역시 마찬가지로, 윈도우 함수이다.
순위, 합계, 평균, 행 위치 등을 조작하는 역할이다.종류는 확인했고, 특징을 알아보자
- 집계함수 : GROUP BY 구문과 병행하여 사용 가능
- 순위, 순서, 비율함수 : GROUP BY 구문과 병행하여 사용 불가
→ 윈도우 함수와 GROUP BY 구문은 둘 다 파티션을 분할한다는 의미에서 유사---- WINDOW FUNCTION 예시 SELECT WINDOW_FUNCTION () OVER (PARTITION BY 컬럼 ORDER BY 컬럼) FROM 테이블명 ## PARTITION BY 생략 가능윈도우 함수를 언제 써야하는지, 사용해야하는 이유는?
집계함수처럼 계산은 하되, 원본 행들을 그대로 유지하면서 계산 결과를 함께 보고 싶을 때SELECT department, AVG(salary) FROM employees GROUP BY department; -- 부서별 평균 급여만 남고, 개인별 행은 표출하지 않음SELECT employee_name, department, salary, AVG(salary) OVER (PARTITION BY department) AS dept_avg_salary FROM employees; -- SELECT 문의 행을 유지하면서, 각 부서별 평균 급여를 같이 표출
위에 종류를 나타낸 표를 참고
색 강조를 한 함수를 볼 수 있는데, 실무에서 자주쓰이는 함수가 대상이다.
먼저 순위함수를 살펴보자.
순위함수 (RANK)
특정 컬럼의 순위를 구하는 함수
동일한 값에 대해서는 같은 순위를 부여, 중간 순위를 비운 값이 출력select *, rank() over(partition by JOB order by SALARY) as rank1 from basic.window1
SALARY 값이 2등인 두 개의 행에 대해, 2가 아닌 3으로 표기가 된 것을 볼 수 있다.
순위함수 (DENSE_RANK)
특정 컬럼의 순위를 구하는 함수
동일한 값에 대해서는 같은 순위를 부여, 중간 순위를 비우지 않고 출력select *, dense_rank() over(partition by JOB order by SALARY) as RANK1 from basic.window1
SALARY 값이 2등인 두 개의 행에 대해, 2로 표기가 된 것을 볼 수 있다.
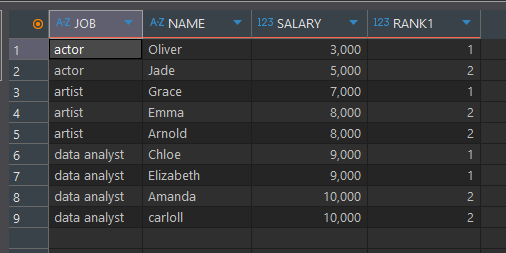
순위함수 (ROW_NUMBER)
특정 컬럼의 순위를 구하는 함수
동일한 값에 대해서 고유한 순위를 부여select *, ROW_NUMBER() over(partition by JOB order by SALARY) as RANK1 from basic.window1
SALARY 값이 2등인 두 개의 행에, 순차적으로 순위가 표기 된 것을 볼 수 있다.
순서 함수 (FIRST_VALUE)
파티션 별 가장 먼저 나온 값을 출력
공동 등수 인정 X, 처음 나온 행만 가져오며 MIN 함수와 결과 동일
FIRST_VALUE(컬럼1) OVER(PARTITION BY 컬럼2 ORDER BY 컬럼3)
순서 함수 (LAST_VALUE)
파티션 별 가장 마지막에 나온 값을 출력
공동 등수 인정 X, 나중에 나온 행만 가져오며 MAX 함수와 결과 동일
LAST_VALUE(컬럼1) OVER(PARTITION BY 컬럼2 ORDER BY 컬럼3)
순서 함수 (LAG)
이전 N 번째 행을 가져오는 함수
별도 명시가 없는 경우, 기본값은 1
가져올 행이 없을 경우 DEFAULT 값을 지정해주는 것으로 NVL, ISNULL 함수와 기능 동일select *, LAG(SALARY) OVER (ORDER BY NAME) as PREV_SAL from basic.window1
select *, LAG(SALARY, 2) OVER (ORDER BY NAME) as PREV_SAL from basic.window1
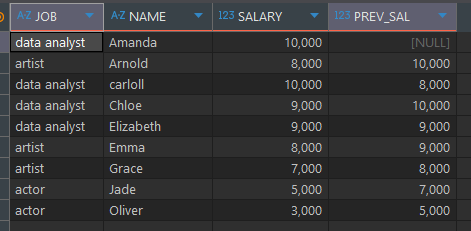
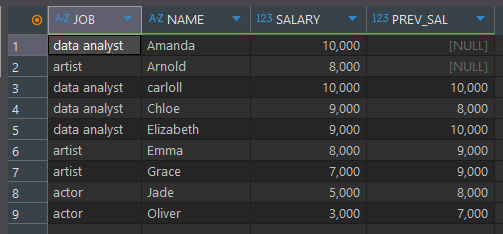
순서 함수 (LEAD)
이후 N 번째 행을 가져오는 함수
별도 명시가 없는 경우, 기본값은 1
가져올 행이 없을 경우 DEFAULT 값을 지정select *, LEAD(SALARY) OVER (ORDER BY NAME) as PREV_SAL from basic.window1
select *, LEAD(SALARY,2) OVER (ORDER BY NAME) as PREV_SAL from basic.window1
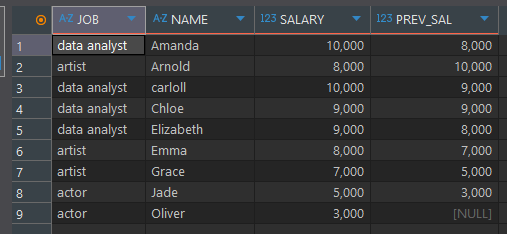
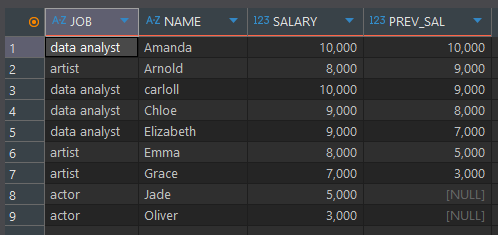
비율 함수 (RATIO_TO_REPORT)
파티션 내 전체 SU, 값에 대한 행별 백분율을 소수점으로 출력
결과값은 0 ~ 1 사이
MySQL 미지원 함수
RATIO_TO_REPORT(컬럼1) OVER (PARTITION BY 컬럼2 ORDER BY 컬럼3)
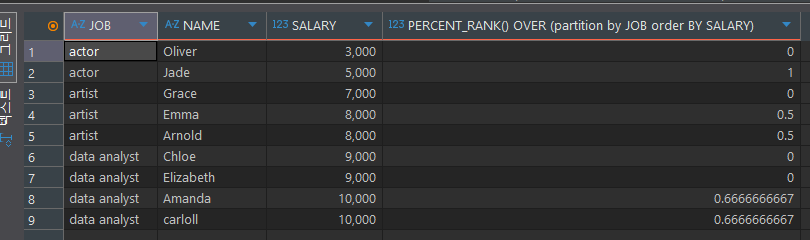
비율 함수 (PERCENT_RANK)
파티션 별 가장 먼저 나오는 값을 0, 마지막에 나오는 값을 1로 정하여,
행 순서 별 백분율을 출력select *, PERCENT_RANK() OVER (partition by JOB order BY SALARY) from basic.window1
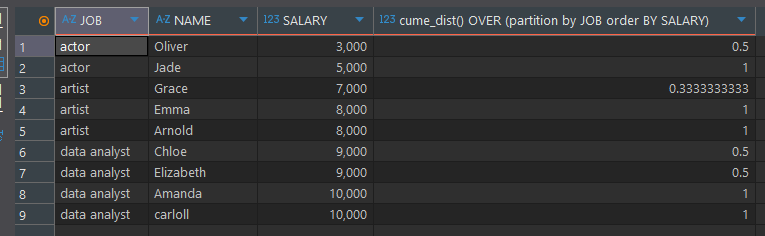
비율 함수 (CUME_DIST)
파티션 별 전체 건 수에서 현재 행보다 작거나 같은 건수에 대한 누적 백분율을 출력
select *, cume_dist() OVER (partition by JOB order BY SALARY)
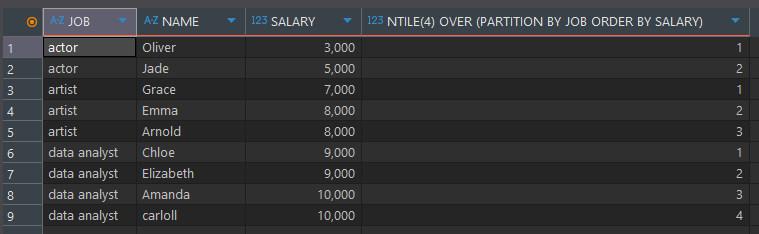
비율 함수 (NTILE)
파티션 별 전체 건수를 계산한 값으로 N등분한 결과를 출력
select *, cume_dist() OVER (partition by JOB order BY SALARY)
WITH 문
테이블 재사용
구분 상세 정의SQL 구문에서 사용되는 임시 테이블 사용이유쿼리 가독성 및 성능 향상 특징임시 테이블의 개념, 작성한 쿼리 내에서만 실행 가능 하나의 SQL 구문에서 여러 개의 WITH 문 선언 가능 하나의 테이블에 대한 여러 조회가 필요한 경우, WITH 문으로 1회 조회 및 선언 복잡한 연산을 보다 효율적으로 처리 (JOIN, UNION 등의 결과를 WITH 문에 저장 기본 문법은 아래와 같다.
WITH 임시테이블명 AS ( SELECT 컬럼1, 컬럼2, .. FROM 테이블명 ) SELECT 임시테이블에서 불러온 컬럼 중 필요한 컬럼 FROM 임시테이블명예시) PROGRAMMERS - 대장균의 크기에 따라 분류하기2
WITH CLASSIFIED AS ( SELECT ID, CASE NTILE(4) OVER (ORDER BY SIZE_OF_COLONY DESC) WHEN 1 THEN 'CRITICAL' WHEN 2 THEN 'HIGH' WHEN 3 THEN 'MEDIUM' WHEN 4 THEN 'LOW' END AS COLONY_NAME FROM ECOLI_DATA ) SELECT ID, COLONY_NAME FROM CLASSIFIED ORDER BY ID;예시2) 다중 WITH 구문
WITH gogo as -- 첫번째 WITH 절 ( select game_account_id, exp from basic.users where `level` >50 ), hoho AS -- 두번째 with 절, with 구문은 처음 한번만 작성합니다. ( select distinct game_account_id, pay_amount, approved_at from basic.payment where pay_type='CARD' ) select case when b.game_account_id is null then '결제x' else '결제o' end as gb , count(distinct a.game_account_id)as accnt from gogo as a left join hoho as b on a.game_account_id=b.game_account_id group by case when b.game_account_id is null then '결제x' else '결제o' end ; ) SELECT ID, COLONY_NAME FROM CLASSIFIED ORDER BY ID;
이외 주요 함수