근 3주 간의 SQL 세션이 끝났다.
코드카타를 통해 흐름은 놓치지 않을 예정.
그 동안 진행한 이론을 쭉 보면서 놓쳤던 부분이나, 되새기기가 필요한 부분을 끄적여보자.
데이터 분석가의 주요 업무&역량
- 데이터 추출
- 데이터 가공
- 데이터 시각화
- 인사이트 도출
SQL = 데이터 추출 / 가공에 있어 필수 역량
→ 데이터 추출과 전처리 정합성 검증
| 구분 | 상세 |
|---|---|
| 언어 | SQL, PYTHON |
| 통계지식 | 이론에 대한 이해, 필요한 부분은 학습이 필요 |
| 자격증 취득 | SQLD, ADsP 등 정량적 구분을 위함 |
| 프로젝트 경험 | 가장 중요 |
| 앞선 언어, 통계지식 등이 선행 되어야 함 |
★ 코딩테스트 필수 진행, 시간 내 추출 등 숙달 필요
ROW DATA : 가공되지 않은 데이터를 의미
DBMS : DB에 규칙성과 정합성을 부여 → 데이터 등록/정리/검색 을 용이하게 해주는 소프트웨어
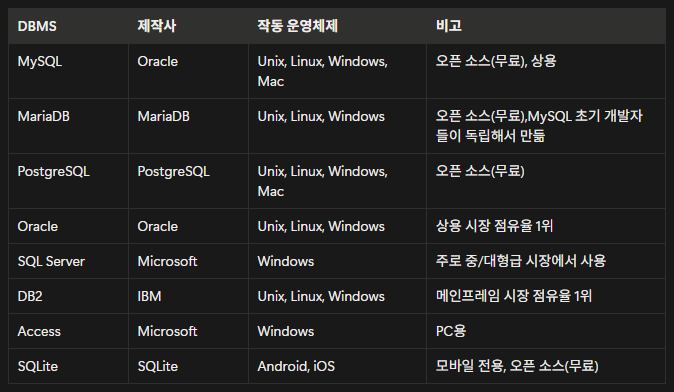
- DBMS 저장방식 : 관계형, 계층형, 망형으로 구분
그 중 관계형 저장방식이 대중적
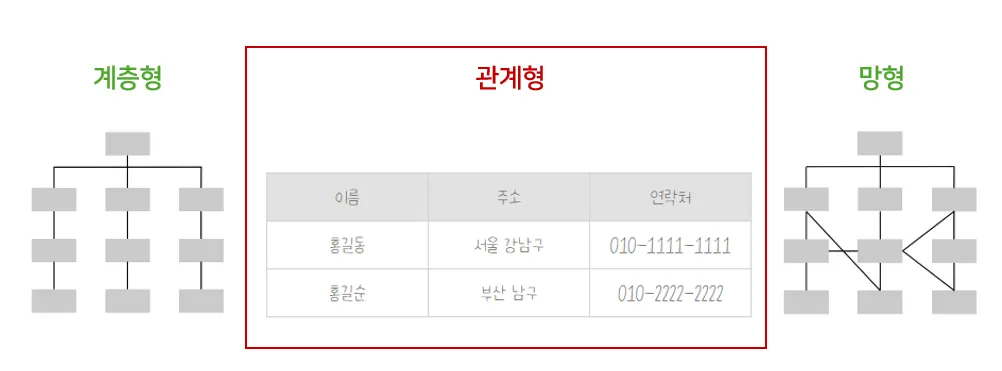
관계형(RDBMS)
1) 행과 열로 이루어진 2차원 구조
2) 계층형, 망형 구조가 발전된 형태
3) 데이터 구성, 복구가 가능
4) 정규화를 통한 중복제거 및 이상치 제거 가능SQL (Structured Query Language)
RDBMS 에서 데이터를 관리하고 처리하기 위한 표준화된 언어
SQL 의 작동 및 작성순서
다시 한 번 작성하지만
SQL을 작성하고 오류를 찾아내는데 많은 도움이 된다. 숙지하자.
작동 순서
FROM → ON → JOIN → WHERE → GROUP BY → HAVING → SELECT → DISTINCT → ORDER BY
작성 순서
SELECT → FROM → WHERE → GROUP BY → HAVING → ORDER BY

성장과 회고를 기록하는 일기장