오늘은 "데이터 리터러시" 에 대해 스터디를 해 보았다.
총 5개의 챕터로 된 강의를 수강하였으며, 내용 정리를 진행해보려고 한다.
내일 여유가 된다면 다시 한 번 회독해보려고 한다.
그만큼 유익하게 느껴졌기 때문이다.
1) "데이터 리터러시"의 정의
"리터러시(Literacy)" 의 사전적 의미는 "읽고 쓰는 능력" 을 뜻한다.
확장된 의미로는, "정보를 이해하고 평가하며 활용하는 능력"이라고 볼 수 있다.
해당 글에서는 확장된 의미로 이해하면 되겠다.
데이터 리터러시 의미
- 데이터를 읽는 능력
- 데이터를 이해하는 능력
- 데이터를 비판적으로 분석하는 능력
- 결과를 의사소통에 활용할 수 있는 능력
풀어 쓰자면,
- 데이터 수집과 데이터의 원천을 이해하고,
주어진 데이터에 대한 다양한 활용법을 이해하고,
데이터를 통한 핵심지표를 설정, 이해하는 것
→ 데이터 리터러시는 올바른 질문을 던질 수 있도록 만들어 준다
그렇다면 올바른 질문을 던지기 위해서는 데이터 분석만 잘하면 되는걸까?
2) "데이터 분석"에 대한 착각
데이터를 잘 분석하면 문제, 목적, 결론이 나올 것
문제 없이 가공하면 유용한 정보를 얻을 수 있음
분석에 실패한다면 방법론, 분석스킬의 부족이라고 생각
본 캠프 전 세미나를 수강하면서 머릿속을 맴도는 생각이 있었다.
얻고자 하는 결과를 위해 데이터 분석을 진행할 때,
"근거가 되는 데이터를 잘 선택한 걸까?" "방향성이 이게 맞나?" 라는 의문은 어떻게 대처해야할까
이러한 의문을 갖고, 대표적인 데이터 해석의 오류 사례 3가지를 살펴보자.
① 심슨의 역설
"부분"에서 성립한 대소 관계가
그 부분들을 종합한 "전체"에 대해서는 성립하지 않는 모순적인 경우를 뜻함
이해를 위한 아래 예시를 살펴보자.
## 출처 : 영궁공공보건국 발표한 브리핑 자료(202108)
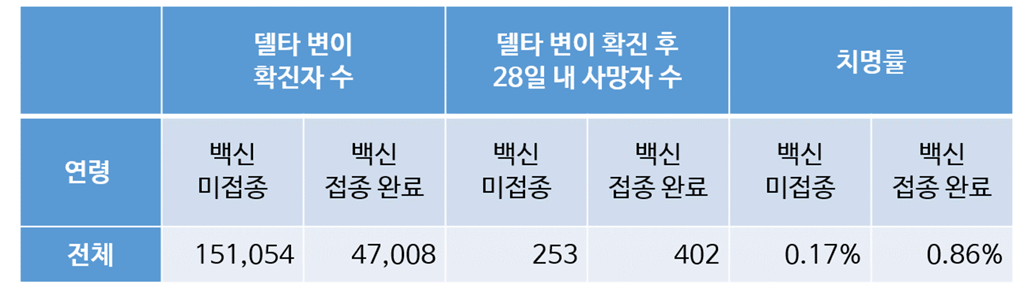
위 표를 데이터를 확인해보면,
- 델타 변이 확진자 수 (A) 와, 델타 ~ 28일 내 사망자 수(B) 의 데이터 확인
- 치명률 = B/A 수치
접종 완료자의 치명률이 미접종자에 비해 높다.. 그것도 5배정도 (??)
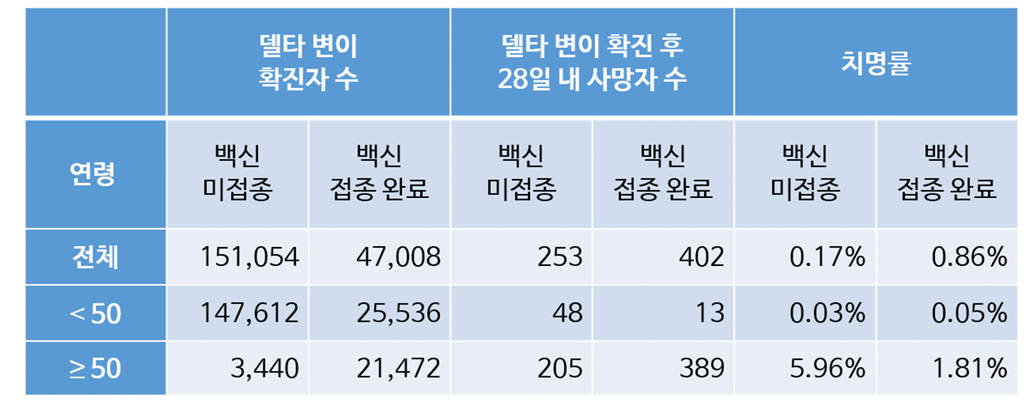
다음은 기존 표에서 연령 구분 데이터가 추가된 표이다.
- 50세 미만의 경우, 접종자의 치명률이 높긴 하지만 차이가 근소함
- 50세 이상인 경우, 미접종자의 치명률이 3배정도 높음
연령 항목을 중심으로 정리하자면,
50세 미만인 경우 접종여부와 관계없이 치명률이 매우 낮다.
50세부터는 접종 시 치명률을 3배정도 낮출 수 있는 효과가 있음 으로 볼 수 있다.
"전체"(연령) 에 대한 결과(치명률) 가,
"부분"(50대 미만/이상의 데이터)에 대한 결과에 그대로 적용되는 것이 아님
해당 예시를 기억하면서,
데이터 기반의 결론이라도 맹목적으로 신뢰하지는 말자.
② 시각화를 활용한 왜곡
## 출처 : The Economist 자료
매년 노동자와 자본가가 버는 시간당 액수의 증가를 표현한 도식
(좌측은 원본, 우측은 로그를 취함)
원본을 보면 노동자의 임금이 현저히 낮은 것을 알 수 있음.
로그를 취한 도식의 경우,
노동자들의 임금 증가가 급격하게 이루어져 왔다고 해석 될 여지가 존재한다.
시각화 왜곡없게 잘하자
③ 샘플링 편향 (Sampling Bias)
전체를 대표하지 못하는 편향된 샘플 선정으로 인해 오류가 발생
예시)
Digest 미국잡지사 1936년 미대통령 선거 전 우편물을 통한 천만 수준의 대규모 여론조사 사례
→ 명부 취합 시 자사 구독자 명부, 클럽 회원 등 부유층 계층으로 편향된 경향이 존재
→ 또한 정치 무관심 그룹, 자사를 싫어하는 그룹 등을 제외시킴으로써 편향성 역시 존재
표본을 위한 데이터 수집에 있어 누락/중복 문제는 없도록 신경쓰자
④ 상관관계와 인과관계
각 관계에 대한 정확한 정의가 필요
상관관계
- 두 변수가 얼마나 상호 의존적인지 파악하는 것
- 한 변수가 증가하면 나머지도 증가/감소, 추이를 따름
인과관계
- 하나의 요인으로 인해 다른 요인의 수치가 변하는 형태
- 원인과 결과가 명확
상관관계는 인과관계가 아닌 것을 항상 유의해야 한다.
3) 데이터 분석에 대한 접근법 & 핵심
앞선 의구심과 오류 케이스를 상기하면서, 올바른 접근 방식에 대해 알아보자.

데이터 분석은 크게 3가지로 나뉜다.
1) 문제 및 가설 정의
2) 데이터 분석
3) 결과 해석 및 액션 도출
"생각" 이 주요한 단게에서 "데이터 리터러시" 가 필요하다.
→ "작업"인 데이터 분석이 목적이 되지 않도록 항상 "Why"를 떠올리자
보통 데이터 분석에 실패하는 이유는 "문제에 대한 명확한 정의"를 하지 않기 때문이다.
① 문제 정의란?
- 데이터 분석 프로젝트의 성공을 위한 초석 (많은 리소스를 투입하더라도 첫 단추가 중요)
- 분석하려는 특정 상황이나 현상에 대한 명확하고 구체적인 진술
- 프로젝트의 목표를 설정하고 분석 방향을 설정
★★★ 문제 정의함에 있어 정확한 정답은 없다.
많은 고민을 해보고 오류를 최소화 하기 위해 고민해보자 ★★★
예시 1) # 문제 정의 실습 진행 해보기 (보완 사항도 고민) #
상황 : 매출 증가가 목표인 패션 플랫폼 A
문제 정의 : 매출을 어떻게 늘릴 수 있을까?
예시 2) # 문제 정의 실습 고민해보기 (보완 사항도 고민) #
상황 :
3개월 전부터 자사 제품의 사용자 수가 감소하고 있다.
사용자 수를 늘리기 위한 포인트 이벤트를 하고 있지만, 효과가 없어보인다.
또한 자사 제품 내 서비스 중 A보다 B가 더 안 좋은 상황이다.
사용자가 줄었기에, 수입도 감소하고 있다.
② 문제 정의 방법론
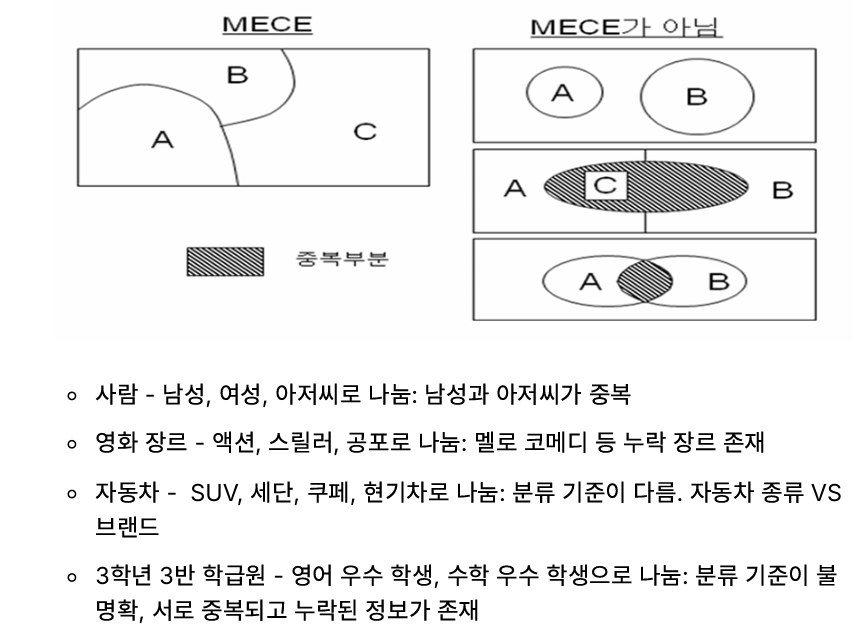
- MECE (Mutually Exclusive, Collectively Exhaustive)
문제 해결과 분석에서 널리 사용되는 접근 방식
상호 배타적이면서, 전체적으로 포괄적인 구성요소로 나누는 것
→ 복잡한 문제를 체계적으로 분해, 구조화된 방식으로 분석이 가능
설명이 어렵지만, 예시를 통해 쉽게 알아보자.
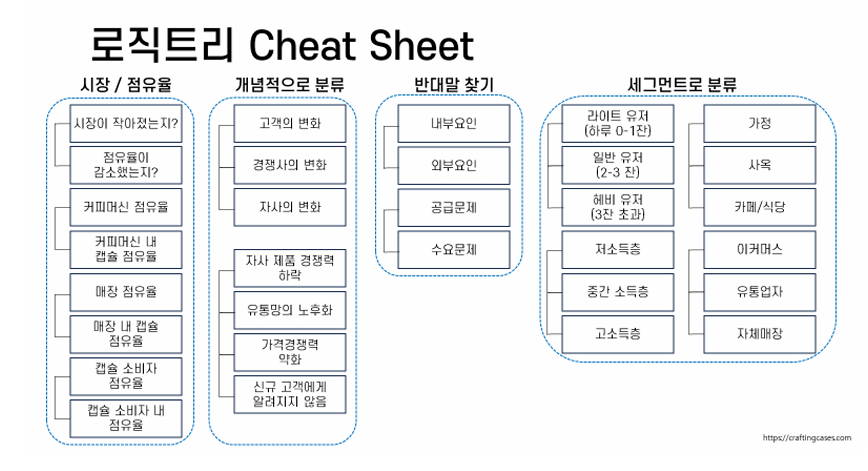
- 로직 트리 (Logic Tree)
MECE 원칙을 기반으로 조금 더 복잡한 문제를 분해하는데 사용
상위부터 하위 문제로 계층적 접근
로직 트리는 사용자가 사용하는 기준과 생각에 따라 달라진다.
★★★ 시간 투자 많이 해서라도 해당 방법론에 익숙해지자
중복과 누락 오류를 최소화하고 제거하기 위한 투자 ★★★
예시) # 실습 진행 해보기 #
1. 살을 어떻게 뺄 것인가?
2. 수익성 개선 방법에는 무엇이 있을까?
## 참고자료 [nescafe - 로직트리]
문제 정의 필요성 (재차 강조)
풀고자 하는 것을 명확하게 정의하고, 해결하기 위한 데이터 분석의 방향성을 정한다.
결과를 정리하고 해석하여, 더 나아지기 위한 새로운 액션 플랜을 수립하기 위함
③ "문제 정의" 의 핵심
So What? (그래서 뭐? 결과가 뭔데?)
Why So? (왜 그렇게 말하는데? 근거가 뭔데?)
- So What?
- '그래서', '따라서', '이렇 듯' 앞에 오는 정보나 소재에서
과제의 답변에 맞는 중요한 핵심을 추출하는 작업
- 나타난 현상을 바탕으로 과제에 비추어 말할 수 있는 내용의 핵심을 추출하는 작업
-
Why So?
- 구체적으로 무슨 뜻인지를 검증하고, 확인하는 작업
- 'So What' 요소의 타당성을 전체 혹은 그룹핑한 요소로 검증하고 증명하는 작업
앞서 진행한 실습 로직 트리도 위 법칙에 맞는지 확인을 해보자
④ "문제 정의" 팁
- 결과를 공유하려는 자가 누구인지 정의하기
- 결과를 통해 원하는 변화 생각하기
- 회사 소속이라면, 경영자 입장에서 보려고 노력
- 많은 사람들과 의견을 나눠보기
- 반드시 혼자서 오래 고민해보는 시간 갖기
오늘은 데이터 리터리시의 정의 ~ 문제정의 까지 진행하고,
명일 데이터의 유형, 지표 설정, 결론 도출을 순서로 마무리 작성예정이다.
