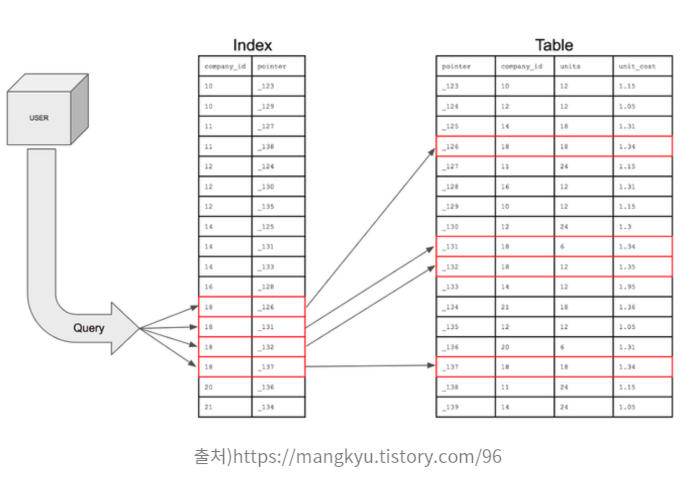
데이터베이스를 설명하기 앞서 가장 기본적인 RDBMS 구조를 보고 시작해보고자 합니다
* DBMS(DataBase Management System) :
사용자의 요청을 해석하여 데이터베이스에 저장된 정보를 관리할 수 있게 도와주는 소프트웨어
ex) MySQL, Oracle DB, Maraia DB 등
SQL : RDBMS에 저장된 데이터를 관리하기 위해 설계가 된 프로그래밍 언어
✨인덱스
* 정의
DB 내 저장된 데이터의 주소라고 생각하면 된다. 이를 가지는 이유는 많은 데이터를 일일히 조회할 수 없고 한 눈에 찾기 위해 사용한다.
마치 책갈피, 색인과도 같다 미리보기가 아닌 바로 어디인지 위치를 찾아주는 것이니 주의하자.
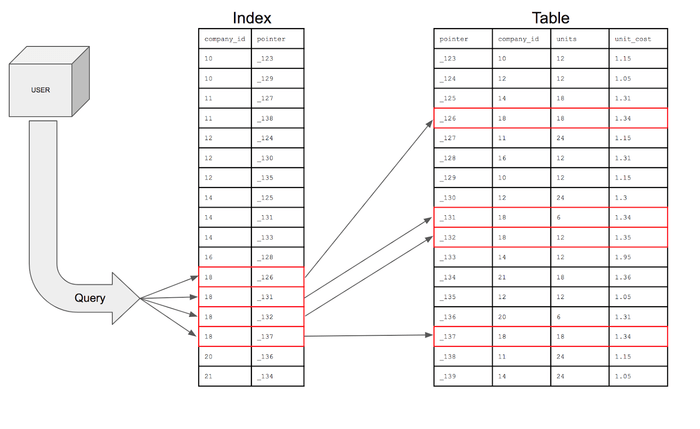
인덱스는 즉 테이블 내의 1개나 여러개의 컬럼을 key로 기준을 삼아 해당 key에 OID(레코드의 물리적 주소값)을 저장하여 찾는 객체다.
2. 인덱스의 장단점
-
(장점)
- 원하는 데이터를 빠르게 조회할 수 있다.
- 시스템의 부하를 줄인다.
-
(단점)
- 타 성능에 악영향
- 데이터 조회(SELECT) 외에
INSERT/UPDATE/DELETE등의 성능에 영향을 미침
- 데이터 조회(SELECT) 외에
- 추가 저장 공간 필요
- 인덱스 key에 대한 OID를 저장을 해야하는데 공간이 필요하다.
=> 그래서 이를 사용할 때 테이블의 전체 영역 중 30~50% 이상을 잡아 먹는다는 점이 있다😮
- 인덱스 key에 대한 OID를 저장을 해야하는데 공간이 필요하다.
- 이를 계속적으로 관리가 필요
- 인덱스를 생성 및 관리해주어야 함
- 타 성능에 악영향
그럼에도 불구하고 현재 RDBMS에서 많은 데이터를 관리하기에 그 수많은 데이터 중 조회 업무는 90%를 차지한다.
이렇기에 조회의 속도, 검색 속도의 향상은 시스템 부하를 감소시킨다고 볼 수 있어 인덱스는 위의 단점에도 사용하면 좋다.
.
.
.
이런 곳에서 쓰면 좋다고 한다.
1) 규모가 큰 테이블
2) 조회 기능(SELECT) 이 많이 쓰이는 곳에서
3) 혹은 JOIN / WHERE / ORDER BY에 자주 사용되는 컬럼,
(4) 혹은 데이터의 중복도가 낮은 컬럼 등에서..!
인덱스는 카디널리티가 높고, 선택도가 낮은 곳을 선택해서 쓰자
+) 'SQL 튜닝'이란 것은 백엔드에서 인덱스를 활용할 수 있도록 SQL을 수정하는 기능이라고 한다. 😮
✨ 인덱스와 B+Tree 사용의 이유
알고리즘이 꽤 많이 나온다. 특히 여기서는 시간 복잡도에 대한 얘기가 가장 많이 언급되는데

가장 일반적인 모양의 Tree로 이에 대한 시간 복잡도는 O(log N)이다.
그러나 예외는 있다. 최악의 경우 한쪽으로 늘어진 
경우 시간 복잡도는 O(N)이다..
그래서 이런 최악을 대비하여 Balanced Tree( B-Tree, RedBlack-Tree 등) 을 사용한다.
그러면 여기서 하나의 의문을 가질 수 있다. 우리는
왜? 평균적으로 가장 빠른 Hash Table인 O(1)인데
굳이? (Balanced) Tree를 쓰는걸까?
그 이유를 알아보자...
1. Hash Table의 단점...
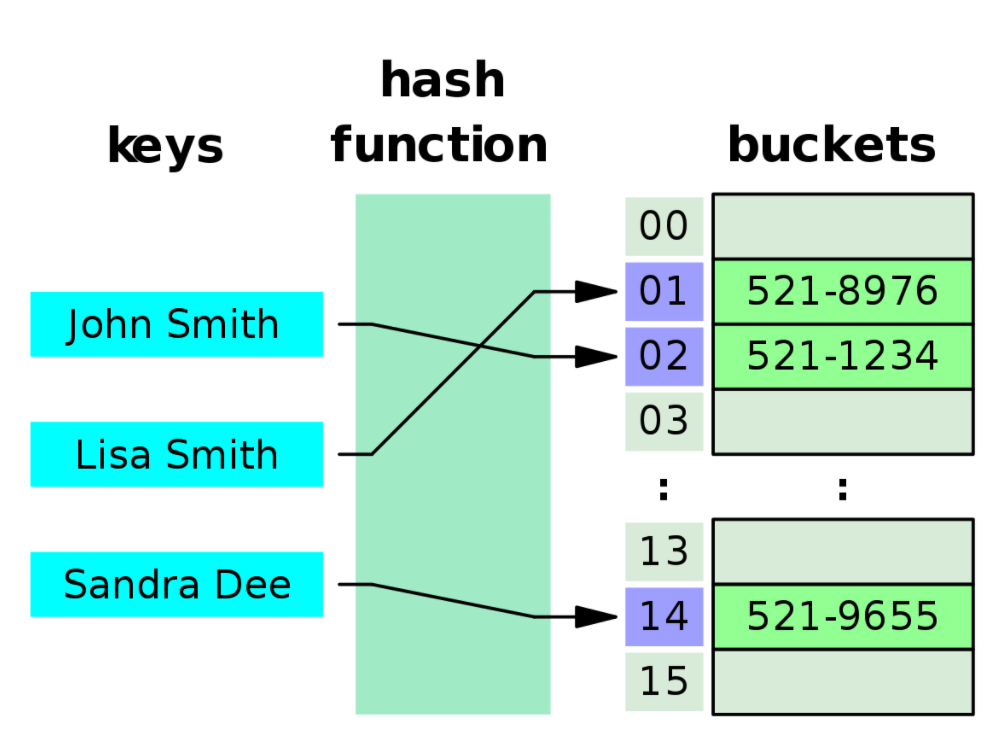
* Hash Table은
Hash Function 이라는 특정 계산을 하는 함수에 '입력 값(keys)'가 들어오면 언제나 같은 결과를 뱉는다.
그래서 미리 저장된 메모리 공간(Hash Table)에 한 번에 접근하므로 빠른 시간 복잡도 O(1)를 가져 한 번에 접할 수 있다고 생각하는데...
- 이 O(1)이라는 시간 복잡도 즉, "탐색시간은 단 하나의 데이터를 탐색하는 시간" 이다.
- 또한, Hash Table에 저장되어 있는 값들은 정렬되어 있지 않아 조회를 하고자 하는 특정 값보다 크거나 작은 값을 찾을 수 없다.😥
그렇기 때문에 DB의 인덱스의 자료구조로 비효율적이라 잘 쓰지 않는다.
답은 B+Tree

-
(정의)
하나의 노드에 여러 데이터가 저장 가능한 트리 -
장점
1. 노드 내의 데이터들은 항상 정렬되어 있다.
2. 해당 데이터들 사이의 범위를 이용하여 자식 노드를 가질 수 있다.
-> 노드 내 데이터 개수가 N이면 자식 노드의 개수는 (N+1)개.
정리하면
RedBlack-Tree의 경우
하나의 노드 내에 무조건 하나의 데이터 만을 가지고, 이로 인해 자식 노드로 넘어가는 횟수가 많아지게 된다.(이는 노드 간에 "참조 포인터"로 연결)
B+Tree는
하나의 노드 내에 여러 데이터를 저장할 수 있다.
그리고 하나의 노드 내에 정렬된 데이터들이 "배열"처럼 모습을 띄는데,
-> 포인터로 메모리에 접근시 부가적인 연산이 필요한 것에 비해 '배열' 방식은 바로 다음 인덱스로 접근하기에 훨씬 빠르다.
특히 데이터 개수가 많아지면 처음에 이론적인 시간 복잡도는 두 트리가 O(log N)이나 물리적인 메모리 처리에서 접근 방식이 매우 차이가 난다.
⭐ B-Tree를 선택한 이유 한 줄로 정리
- 트리 내 모든 데이터가 항상 정렬된 상태로 유지되기 때문에, 등호(=) 연산뿐만 아니라 부등호(>, <) 연산 처리도 가능
- 포인터 접근 방식이 적어 매우 많은 데이터가 있어도 속도 이슈가 적다.
- 데이터 탐색뿐 아니라, 삽입 및 수정 및 삭제에도 항상 O(log N)의 시간 복잡도를 가진다.
- 리프노드들이 Linked List로 되어 있다.
왜 부등호에 이점이 있을까? 다시 위로 올라가서 확인 안하고 링크드리스트 여서 다시 되돌아가서 조건으로 조회하지 않고 리프노드 내에서 뒤에만 찾아보거나 하면서 조회를 하는 범위가 줄어들기 떄문(시간 단축)
출처
헬창 백엔드 개발자의 이것저것 블로그를 참조하여 작성하였습니다.
정말 많은 이해를 도와주신 이 블로그를 참조하여 작성하였습니다
