
필수적으로 알고가기
-
SSL과 CL(=Contrastive Learning)
- 용어정리 💡 Pretext Task : SSL를 학습하기 위해 사용자가 만든 문제(=training data set) Downstraem Task : SSL을 적용해서 풀 문제(=validation, Testing data set)
- Contrastive Learning이란?
- 인코더가 없는 구조!
- Contrasitve Loss 함수를 이용해 성능을 평가한다!
- Postive와 Negative Sample 데이터를 번갈아 비교하면서 학습한다.
- Augmentation을 활용해서 학습한다.
- SSL이 적용되는 원리
-
Pretext Task
SSL은 처음에 label이 없는 데이터셋을 가지고 학습한다 → 각 이미지에 대한 label을 직접 사용자가 만들어 학습되도록 한다. → output과 label간의 유사성을 계산해 정확도를 판단
-
DownStream task에 적용
-1. Linear Evaluation
Pretext Task를 통해 만들어진 모델의 weights를 freeze시키고, FC Layer를 붙여 Fine-tunning한다. → 보통 일반적으로 사용하는 방법
-2. Semi Supervised Learning
데이터셋의 Label을 1%~10%사이로만 이용해서 학습시킴
-3. Transfer Learning
학습된 모델을 Transfer-learning시켜 다른 데이터셋을 평가
-
-
SSL (=Self-Supervised-Learning)의 진행방향
초반에 제안된 SSL 방법은 1. Generative Learning, 2. Proxy Task가 있다.
-
Genrative Learning(GL)
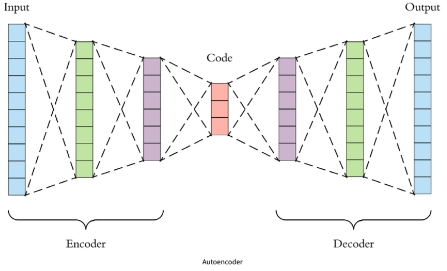
Autoencode같이 Encode와 Decode가 같이 구성되어있는 모델이 학습하는 것을 Genrative Learning이라고 한다.
이 GL은 Encode와 Decoder 둘 다 학습하기 떄문에 컴퓨터 리소스가 크다는 것이 단점이다.
또한 SSL 모델을 우리가 사용하는 Image Classification에서 사용할때에는 Decorder가 딱히 필요없다.
-
Proxy Task
Proxy Task란 Generative Learning 과 다르게 Decorder의 구조는 없고, 미리 사용자가 Label을 만들어서 작업을 수행하는 방법이다.
→ 이에 대한 논란이 있음. 바로, 사용자가 만든 label이 고차원 정보를 만드는데 도움이 될 것인가? 이다.
-
Proxy Task의 대표적인 모델 : Examplar
💡 Examplar 모델 요약 : 이미지 각각의 Label을 사용자가 만들고 이에 대해 Random Augmentation을 진행해, origianl image의 label에 전부 할당해서 모델이 학습시킨다.
-
Proxy Task의 대표적인 모델 : Jigsaw Puzzle
💡 jigsaw Puzzle 모델 요약 : 이미지를 여러개의 패치로 만들어 순서를 맞춰 학습시키는 모델 Jigsaw Puzzle 모델은 학습된 모델이 Imge classification이나 Object Detection과 같은 것에 좋다고 논문에서는 얘기한다고 함.
💡 단점 : 직접 라벨링을 만들어야한다는 문제점을 가지고 있음! → 그래서 Proxy Task를 통해 만들어진 학습 모델이 기존 이미지보다 고차원적인 information을 가지는지에 대한 평가가 모호함 → 이를 해결해주는 것이 Contrastive Learning(대조학습)
-
-
-
Augmentation 이란?
**Image Data Augmentation for Deep Learning: A Survey 논문 참조**
Image Data Augmentation for Deep Learning: A Survey
💡 개념 : 하나의 데이터를 여러가지 방법(crop, intensity 바꾸기, random 등)으로 모델이 데이터로 학습을 할때 학습 데이터셋의 규모를 키우는 방법 -
Augmentation 방법
-
Basic Transformations(Original, Flipping, Rotation, Cropping)

-
Color Space

-
Noise Injection
Contrast를 조절하거나, Histogram Equalization(HE)를 적용하거나, Noise Filter를 조절해서 만들거나, White Balance를 조정하거, Shapen효과를 주기도 함
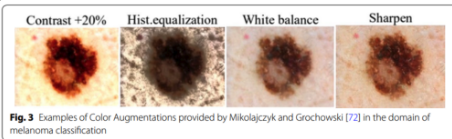
-
Kernel Filter
-
Gaussian Filter : 이미지를 흐리게 만듬

-
Edge Filter : 이미지를 선명하게 만듬
-
Patch Shuffle Filter : nn으로 특정 영역을 나눠 해당 영역의 픽셀을 패치단위로 섞음 Proxy task기법과 비슷함
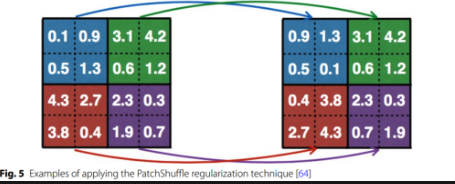
-
-
- Evaluation
본 논문에서는 Augmentation 기법중 Cropping 효율이 높다는 것을 알 수 있다.
다만 논문에서는 데이터 셋에 따라 다른 증강 기법이 더 효율적일 수 있으니, 데이터에 따라 다르게 보아야한다고 전달한다.
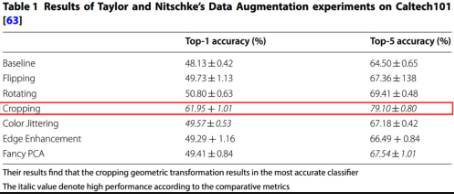
- Augmentation을 할떄 주의할 점
<aside>
💡 데이터의 본질이 흐려질 수 있다. blur나 crop을 하였을때 과연 원본 이미지의 성질을 가지고 있는지가 중요하다!
</aside>

- 참고 링크
[[논문 분석] A survey on Image Data Augmentation for Deep Learning](https://foreverhappiness.tistory.com/112)-
SimCLR 구조
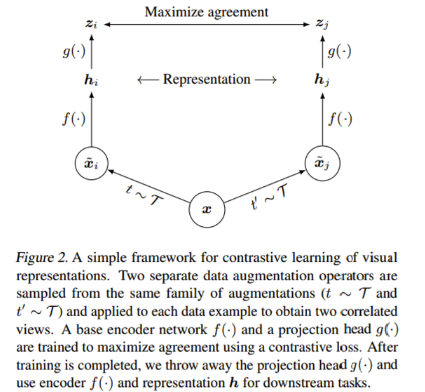
-
Linear Evaluation 성능 평과 결과
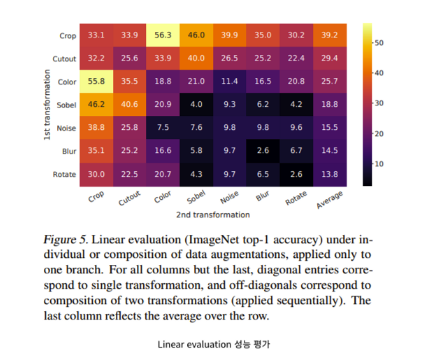
CROP과 Color를 섞은것이 가장 성능이 좋다고 나온다.
참고 및 의견
- **Image Data Augmentation for Deep Learning: A Survey 논문 참조**
